[Paper Review] AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling
[논문 리뷰] AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling
AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling
Jun Zhan, Junqi Dai, Jiasheng Ye, Yunhua Zhou, Dong Zhang, Zhigeng Liu, Xin Zhang, Ruibin Yuan, Ge Zhang, Linyang Li, Hang Yan, Jie Fu, Tao Gui, Tianxiang Sun, Yugang Jiang, Xipeng Qiu
[Arxiv] [Project Page] [Github] [Huggingface]
Introduction
LLMs은 인간 언어를 이해하고 생성하는 데 있어 놀라운 능력을 보여주고 있지만 텍스트 처리에 한정되어 있다. LLM에 멀티모달 인지 능력을 부여하기 위한 현재 접근 방식은 멀티모달 Encoder를 언어 모델에 결합하여 다양한 모달리티의 정보를 처리하고, LLM의 강력한 텍스트 처리 능력을 활용해 일관성 있는 응답을 생성하는 것이다. 그러나 이는 텍스트 생성만 가능하며, 다양한 모달리티 출력은 불가능하다.
기존의 any-to-any 멀티모달 생성에 대한 연구들은 몇 가지 한계를 보여주었는데, 강력한 Language 모델이 부족하여 추론과 의사결정 능력이 떨어지거나, 사전에 개별적으로 학습된 Encoder와 Decoder를 사용하여 입력과 출력 간 표현이 일관되지 않게 되어, 학습과 추론을 복잡하게 만들었다. 또한, 다양한 모달리티를 안정적으로 학습하기 위해 기존 모델과 기술에 많은 수정이 필요했다.
본 논문에서는 이러한 문제를 극복하기 위해 AnyGPT를 소개한다.
AnyGPT는 discrete representation을 이용해 다양한 모달리티를 통합적으로 처리할 수 있는 any-to-any 멀티모달 언어 모델(MLLMs)이다. 이미지, 오디오 등의 데이터를 의미 있는 discrete sequence token으로 압축하는 멀티모달 tokenizer를 갖추고 있다.
또한, 모든 모달리티를 포함하는 정렬된 멀티모달 데이터가 부족한 문제를 해결하기 위해, 텍스트 중심의 멀티모달 정렬 데이터셋 AnyInstruct-108k를 구축한다. 텍스트는 의미 표현의 가장 정교한 모달리티이며 대부분의 멀티모달 데이터셋에 존재하기 때문에, 다른 모달리티를 텍스트에 정렬시킴으로써 모달 간 상호 alignment을 달성할 수 있다. 이 데이터셋은 다양한 모달리티가 섞인 108,000개의 다중 턴 대화로 구성되어 있어, 모델이 임의의 멀티모달 입력과 출력을 처리할 수 있도록 학습된다.
Method : AnyGPT
LLM을 이용해 어떤 모달리티에서든 어떤 모달리티로도 생성이 가능하도록 하기 위해 균일하게 학습할 수 있는 포괄적인 프레임워크를 제안한다.
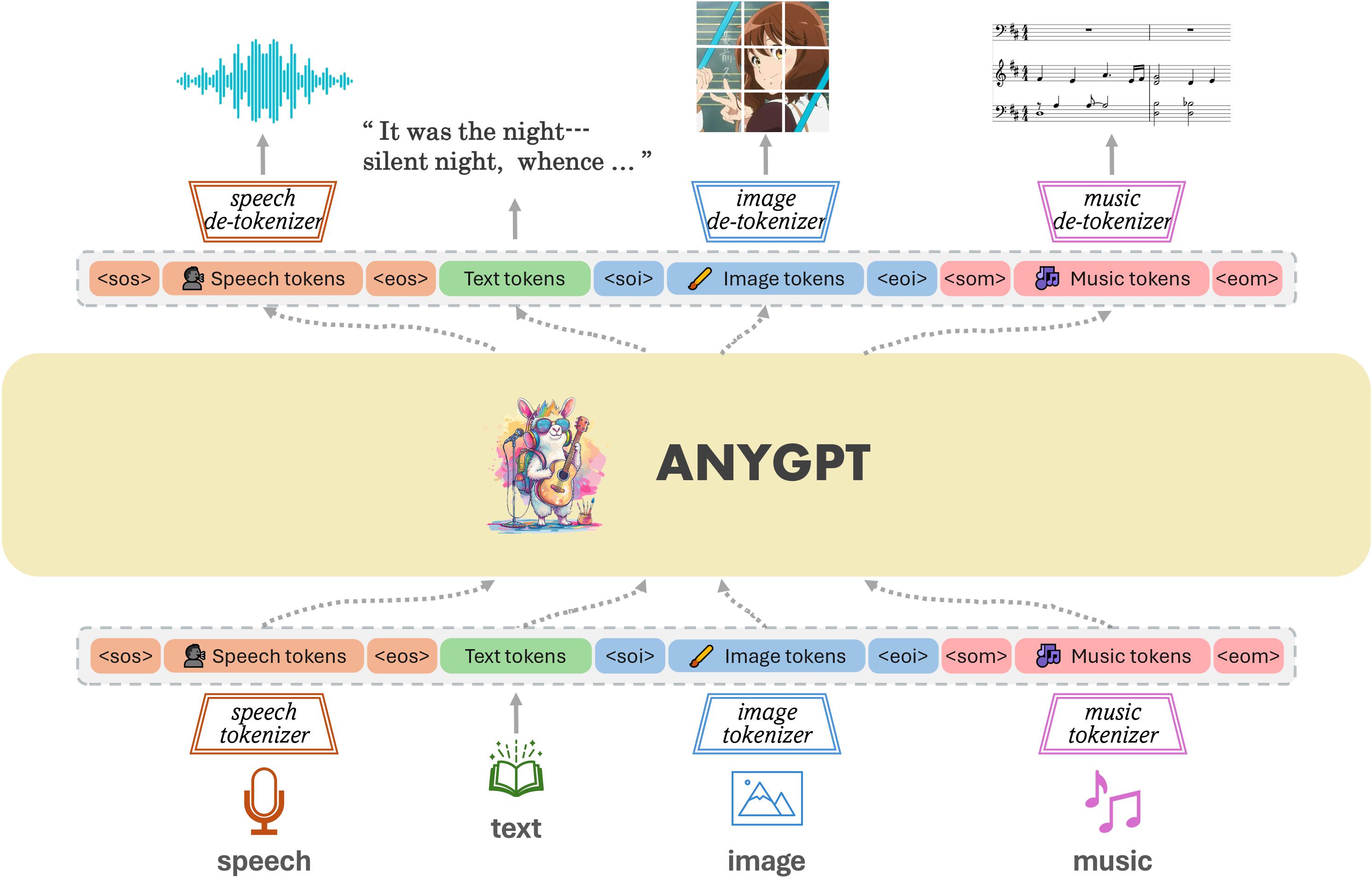
이 프레임워크는 크게 세 가지 주요 구성 요소로 이루어진다:
- Multimodal tokenizers
- Backbone LLM
- Multimodal de-tokenizers
토크나이저는 continuous한 non-text 데이터를 discrete token으로 변환하며, Language 모델에 의해 다음 토큰 예측(next-token prediction)을 학습한다.
Inference 단계에서는, 생성된 멀티모달 토큰들을 de-tokenizers를 통해 원래의 모달리티로 복원한다.
생성 품질을 높이기 위해 후처리 모듈(multimodal enhancement modules)도 추가로 사용할 수 있다.
1. Tokenization
아래는 다양한 모달리티에 따른 tokenizer 설계이다.
| 모달리티 | Vocab Size | 샘플당 토큰 수 | RVQ 사용 | 입력 크기 |
|---|---|---|---|---|
| 이미지 | 8192 | 이미지당 32개 | ✘ | 224×224 |
| 음성 | 1024 | 1초당 50개 | ✔ | 가변 길이 |
| 음악 | 4096×2 = 8192 | 1초당 200개 | ✔ | 5초 |
Image Tokenizer
이미지는 SEED Tokenizer를 사용하며 ViT Encoder, Causal Q-Former, VQ Codebook, MLP, UNet Decoder 등으로 구성된다.
- $224×224$ RGB 이미지를 $16×16$ 패치로 나눈다.
- 32개의 causal 임베딩으로 변환한다.
- codebook을 통해 양자화 코드로 이산화한다.
- MLP를 사용하여 코드를 미리 학습된 unCLIP Stable Diffusion(unCLIP- SD)의 latent space과 align된 임베딩으로 디코딩한다.
- UNet Decoder를 사용하여 생성 임베딩을 원본 이미지로 복원한다.
최종적으로 이 코드는 unCLIP 기반 diffusion 모델의 잠재공간에 맞춰 재구성된다.
Speech Tokenizer
SpeechTokenizer는 Residual Vector Quantization (RVQ) 기반의 Encoder-Decoder 구조를 갖고 있으며, 8개 layer으로 구성된 RVQ를 통해 단일 채널 오디오를 $50\;\text{Hz}$ frame rate로 압축한다.
첫 번째 layer는 semantic 정보를, 이후 layer는 감정·억양 같은 언어 외 정보(paralinguistic detail)를 담는다.
Commonvoice 및 Librispeech 데이터로 사전학습된 SpeechTokenizer를 활용한다.
AnyGPT에서는 semantic 토큰만 LLM이 처리하며, 나머지 감각 정보는 별도의 음성 복제 모델(voice cloning model)이 처리한다.
Music Tokenizer
RVQ를 사용하여 latent space를 양자화한 convolutional AutoEncoder인 Encodec을 사용한다.
32kHz 단일 채널 음악을 50Hz frame으로 처리한다. 4 개의 quantizer가 있는 RVQ를 사용하여, 5초 길이의 음악을 $250×4$ codes matrix로 변환한 뒤, 프레임 단위로 펼쳐서 시퀀스를 구성한다.
LLM은 첫 번째 프레임의 초기 4개 token을 예측하는 것으로 시작하여 이후 작업 역시 비슷하게 진행된다.
2. Language Model Backbone
Expanding vocabulary
멀티모달 token을 기존 LLM에 통합하기 위해, 각 모달리티별로 고유한 token 집합을 추가하고, 임베딩 행렬 및 prediction layer의 차원을 확장한다.
각 모달리티의 token이 결합되어 새로운 어휘를 만들고, joint representation space에서 aling되어 학습된다. 전체 어휘 크기 $V = ∑^n_{i=1} V_i$ ($V_i$: i번째 모달리티의 어휘 크기)
Unified Multimodal Language Model
각 모달리티별로 tokenizer를 통해 압축된 discrete token을 사용하여 언어 모델을 next token predict하도록 학습한다. 이를 통해 각 모달리티의 인지, 이해, 추론, 생성을 하나의 자동회귀적 task으로 통합할 수 있다.
pretrain된 LLaMA-2 7B을 백본으로 사용하며, 임베딩과 출력 layer 외에는 변경 없이 사용된다.
3. Multimodal Generation
고품질의 멀티모달 데이터는 많은 bit를 가지고 있기 때문에 sequence 길이가 길어지며 Language 모델의 계산 복잡도는 sequence 길이에 따라 지수적으로 증가한다. 이때문에, 본 논문에서는 2단계 프레임워크를 제안한다.
Semantic Information modeling
Language 모델은 semantic-level(의미적) 에서 결합되고 align된 콘텐츠를 생성
즉, 텍스트, 이미지, 음성, 음악 간의 의미적 관계를 반영한 discrete token sequence를 생성
Perceptual information modeling
- non-autoregressive Decoder가 semantic token을 실제 멀티모달 content로 복원
Image
SEED token을 사용하며, Stable Diffusion 3 latent space와 정렬되어 있기 때문에 Diffusion을 통해 고품질 이미지로 복원한다.
Speech
non-autoregressive Masked Language 모델인 SoundStorm을 활용하여 semantic token으로부터 SpeechTokenizer의 acoustic tokens을 생성한다.
이 모델은 Multilingual LibriSpeech(MLS) 데이터셋에서 학습되었다.
이후, SpeechTokenizer의 Decoder가 모든 음성 token을 오디오 데이터로 복원한다.
이 접근 방식은 단 3초 길이의 음성 프롬프트만으로 화자의 목소리를 복제할 수 있도록 하며, 동시에 LLM이 처리해야 할 음성 시퀀스 길이를 효율적으로 단축시킨다.
Music
Encodec token을 사용하며, 이는 사람이 인지하지 못하는 고주파 세부 정보를 제거함으로써 token 수를 줄이고, semantic 정보에 집중하도록 설계된다. 이후 Encodec Decoder를 사용해, discrete token을 고품질 음악 데이터로 재구성한다.
Multimodal Data
Pretraining Data
Any-to-Any generation을 가능하게 만들기 위해서는, 모달리티 간의 관계가 충분히 aligned된 데이터가 필요하지만 이러한 데이터는 수가 매우 적다.
이를 해결하기 위해, 본 논문에서는 텍스트 중심의 bi-modal alignment dataset을 구축한다. 이때 텍스트는 다른 모달리티 사이의 브릿지 역할을 한다. 즉, 각각의 모달리티를 텍스트와 정렬시키는 방식을 통해, 최종적으로 모든 모달리티 간의 상호 정렬(mutual alignment)을 달성하는 것을 목표로 한다.
모달리티마다 표현과 정보의 종류가 모두 다르기 때문에, 모든 데이터를 token 수를 기준으로 정규화하여 비교 가능한 형태로 만든다.
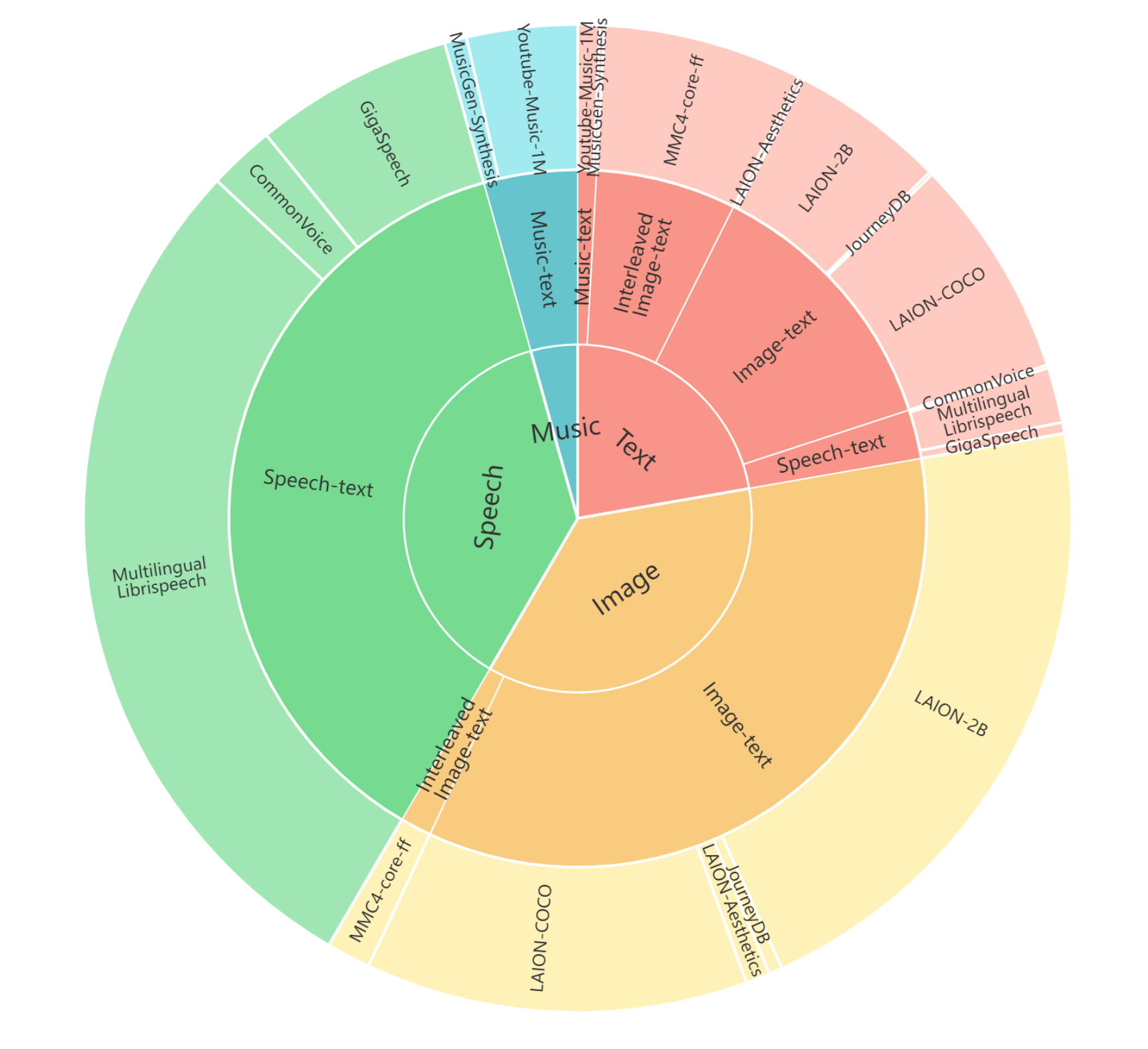
위 Figure는 사전학습에 사용된 전체 데이터의 모달리티별 비율을 시각적으로 보여준다. (중심은 모달리티, 중간은 데이터 유형, 바깥쪽은 세부 데이터셋으로 구성)
token 수가 적은 모달리티는 oversampling 하여, 하나의 학습 배치 안에서 다양한 모달리티가 균형 있게 포함되도록 조정했다.
- Image & Text
- 데이터 목록
- LAION-2B : 웹에서 수집된 Image-Text 쌍 (noise alt-text 포함)
- LAION-COCO : LAION-2B의 6억 개 subset, BLIP로 캡션 생성
- JourneyDB : Midjourney로 생성된 이미지 및 설명
- LAION-Aesthetics : LAION 5B에서 시각적으로 고품질인 이미지들만 추출한 subset
- 위 데이터셋을 전처리를 통해 3억 개의 고품질 Image-Text 데이터를 얻는다.
- 데이터 목록
- Speech & Text
- 데이터 목록
- Gigaspeech : 오디오북, 팟캐스트, 유튜브 등에서 수집된 영어 음성 데이터 (1만 시간)
- Common Voice : 인터넷 자원봉사자들의 영어 녹음 (3000시간 사용)
- Multilingual LibriSpeech (MLS) : LibriVox 오디오북 기반 (영어 4만 4000시간 사용)
- 위 데이터를 조합하여 57,000시간 분량의 Speech-Text를 구축
- 데이터 목록
- Music & Text
- 100만 개 이상의 유튜브 음악 영상을 크롤링
- 영상 제목을 기반으로 Spotify API를 통해 음악과 metadata(제목, 설명, 키워드, 재생목록, 가사 등)를 매칭
- metadata JSON은 GPT-4에게 입력되어, noise를 제거하고 유의미한 요약 문장으로 변환
Training Sample
Language model(LM)을 학습시키기 위해 다양한 템플릿을 사용하여 멀티모달 문장을 구성하여 데이터의 다양성을 확보한다. 각 문장은 non-text $X$와 설명 text로 이루어진다.
OpenAI의 GPT-4를 사용하여 수백개의 instruction을 생성하였으며, $X$-to-text, text-to-$X$ 의 형태로 이루어져있다. 하나의 train sample은 $(I, S, T)$ 로 구성되어있다.
- $I$ : instruction
- $S$ : discrete token sequence
- $T$ : 대응되는 text
Example 1 : $X$ - text
[Human]: {I}.{S}<eoh> [AnyGPT]: {T}<eos>Example 2 : text - $X$
[Human]: {I}. This is input: {T}<eoh> [AnyGPT]: {S}<eos>
<eoh>는 human 입력의 끝,<eos>는 AnyGPT 응답의 끝을 의미
각 모달리티 마다 문장 길이가 많이 다르다는 것을 발견하고, 학습 효율을 높이기 위해 동일한 데이터셋에서 여러 샘플을 하나의 긴 시퀀스로 연결하고, 이 시퀀스가 LLM의 최대 시퀀스 길이를 넘지 않도록 구성했다.
이렇게 하면 시퀀스 내의 모든 토큰이 loss에 기여할 수 있게 된다.
Hyperparameters
| Pretrain | Fine-tuning | |
|---|---|---|
| Gradient clipping | 1.0 | 1.0 |
| batch size | 480 | 64 |
| max length | 4500 | 4500 |
| training steps | 81,000 | 5,000 |
| lr scheduler | cosine | cosine |
| Peak lr | 6e-5 | 2e-5 |
| warmup ratio | 0.03 | 0.03 |
| optimizer | Adam | Adam |
| GPU | A100 | A100 |
Multimodal Interleaved Instruction Data Construction
현재까지는, 두 개 이상의 모달리티로 이루어진 대규모 instruction 데이터셋은 존재하지 않는다. 이는 다양한 모달리티가 혼합된 복합적인 대화를 처리할 수 있는 범용 멀티모달 모델의 개발을 크게 제약하고 있다.
이를 해결하기 위해, Data synthesis를 통해 총 108,000개의 multi-turn 대화 sample로 구성된 합성 데이터셋을 구축하였다. 각 샘플은 텍스트, 음성, 이미지, 음악 등 다양한 모달리티가 혼합된 형태를 띤다.
이러한 데이터는 다음 두 단계로 생성된다:
1. 멀티모달 요소를 통합한 Text 기반 대화 생성
이 단계에서는 GPT-4를 사용해 텍스트 중심의 다중 턴 대화를 생성한다. 이때 이미지, 음악 등 non-Text 요소는 텍스트로 묘사된 형태로 생성된다.
meta topic 확장
우선, 100개의 meta topics를 정하고 GPT-4를 이용해 총 20,000개의 구체적인 topic으로 확장한다.
Prompt

시나리오 생성
각 topic에 대해 사용자가 챗봇에게 질문하는 대화 시나리오를 GPT-4가 작성한다.
이 과정에서 우리는 다양한 모달리티 조합 예시(demonstrations)를 모델에 제공하여, 텍스트뿐 아니라 이미지·음악이 포함된 대화를 유도한다.
Prompt

멀티턴 대화 생성
생성된 시나리오를 바탕으로, GPT-4가 여러 턴(turn)으로 이루어진 실제 대화를 작성한다.
이때 이미지, 음악 등은 상세한 텍스트 설명으로 삽입된다.
다양한 프롬프트 예시를 활용하여, 모달리티가 얽힌 대화의 다양성과 현실성을 높인다.
Prompt

이 결과, 텍스트 기반의 대규모 멀티모달 대화 데이터를 확보할 수 있게 되었다.
2. Text → Multi-modal 전환
앞서 생성된 텍스트 설명을 실제 멀티모달 콘텐츠로 변환한다.
| Modality | Generation Tool |
|---|---|
| Image | DALL·E-3 (OpenAI) |
| Music | MusicGen (Meta) |
| Speech | Azure TTS API (Microsoft) |
또한, 텍스트 instruction 데이터셋 중 일부는 음성화하기 적합한 내용을 선별하여, Text-Speech 데이터 10만 개를 별도로 생성하였다.
Experiment
모든 모달리티에 대해 이해와 생성 능력을 Text ↔ Image / Speech / Music에 대한 task에서 평가한다.
zero-shot 상황에서 평가를 수행하여 Generalization 능력을 평가한다.
Image
Understanding
Task : Image captioning
Dataset : MS-COCO 2014 데이터셋의 Karpathy split test set
| Model | CIDEr ↑ |
|---|---|
| Flamingo (9B) | 79.4 |
| Flamingo (80B) | 84.3 |
| Emu (14B) | 112.4 |
| DreamLLM (8B) | 115.4 |
| InstructBLIP (14B) | 102.2 |
| SEED-LLaMA (8B) | 123.6 |
| AnyGPT (8B) | 107.5 |
Generation
Task : Text-to-Image
Dataset : MS-COCO validation set에서 3만장 sampling
| Model | CLIPScore ↑ |
|---|---|
| GILL | 0.67 |
| Emu | 0.66 |
| SEED-LLaMA | 0.69 |
| AnyGPT | 0.65 |
Speech
ASR - Automatic Speech Recognition
Task : Speech-to-Text
Dataset : LibriSpeech의 test-clean subset
| Model | WER (%) ↓ |
|---|---|
| Human-level | 5.8 |
| Wav2vec 2.0 | 2.7 |
| Whisper Large V2 | 2.7 |
| AnyGPT | 8.5 |
TTS
Task : Text-to-Speech, 화자 음색 복제
Dataste : VCTK 데이터셋 (화자 미포함 상태로 평가)
| Model | WER (%) ↓ | SIM ↑ (화자 유사도) |
|---|---|---|
| Ground Truth | 1.9 | 0.93 |
| VALL-E | 7.9 | 0.75 |
| USLM | 6.5 | 0.84 |
| AnyGPT | 8.5 | 0.77 |
Music
Task : Music Understanding & Generation
Dataset : MusicCaps
| Music understanding | **CLAP Score ↑ ** |
|---|---|
| <music, real caption> | 0.16 |
| <music, generated caption> | 0.11 |
| Music generation model | CLAPScore ↑ |
|---|---|
| Riffusion | 0.19 |
| Mousai | 0.23 |
| AnyGPT | 0.14 |
Example Demonstrations
AnyInstruct-108k 데이터셋으로 파인튜닝을 거친 후, AnyGPT는 모든 모달리티를 자유롭게 조합한 대화가 가능함을 보여준다.
텍스트, 이미지, 음성, 음악이 혼합된 지시를 이해하고, 상황에 따라 가장 적절한 모달리티 조합을 선택해 응답할 수 있다.
예를 들어, 3초짜리 음성 프롬프트로 화자의 감정과 톤을 파악하고, 동일한 음색과 분위기를 반영한 음성 응답을 생성할 수 있다.
관련 예제는 Project Page 에서 확인할 수 있다.
Conclusion
AnyGPT는 discrete token representation을 활용함으로써, 새로운 모달리티를 기존의 대규모 언어 모델(LLM)에 추가적인 구조 변경 없이 자연스럽게 통합하는 방법을 제안한다. 또한 이러한 통합을 위해 다양한 모달리티가 복잡하게 얽힌 다중 턴 지시 대화 데이터셋인 AnyInstruct-108k를 처음으로 합성하고 공개한다.
실험 결과에 따르면, AnyGPT는 다양한 cross-modal tasks에서 주목할 만한 성능을 보여주었으며, discrete token을 사용한 멀티모달 통합이 실제로 효과적이며 실용적임을 입증한다.
Limitations
Any-to-Any 멀티모달 LLM 벤치마크의 부재
Any-to-any 멀티모달 LLM 분야는 아직 초기 단계의 연구 주제이다. 하지만 모델의 다양한 능력을 측정할 수 있는 벤치마크가 부재하다는 점은 큰 도전 과제이다. 성능 평가 및 위험 탐지까지 포함하는 통합 벤치마크의 구축이 시급하다.
LLM 자체 성능 향상
또한, discrete token 기반 멀티모달 LLM은 이 가능하지만, 단일 모달 학습에 비해 약한 성능을 보이며 각 모달리티에 대한 최적화된 성능을 내기 어렵다. AnyGPT의 경우 결국 모델의 각 모달리티 Tokenizer가 성능을 결정하므로 Tokenizer의 품질이 모델 전체 성능의 상한선임을 뜻한다.
긴 문맥 처리 능력
이미지와 오디오 같은 모달리티는 시퀀스 길이가 길어지는 경향이 있지만 AnyGPT는 음악의 경우 5초로 제한되어 실용적 활용에 한계가 있다.