[Paper Review] Ctrl-D
[논문 리뷰] CTRL-D: Controllable Dynamic 3D Scene Editing with Personalized 2D Diffusion
CTRL-D: Controllable Dynamic 3D Scene Editing with Personalized 2D Diffusion
Kai He , Chin-Hsuan Wu , Igor Gilitschenski
CVPR 2025.
[Arxiv] [Project Page] [Github]

Introduction
최근의 효율적인 3D Representation 기법인 NeRF와 3D Gaussian Splatting은 사실적인 새로운 View 합성을 가능하게 했다. 하지만 동적 3D 장면의 제어 가능하고 일관된 편집은 아직 탐구되지 않은 상태이다.
최근 Dynamic 3D scene editing (동적 3D 장면 편집) 연구에서 InstructPix2Pix는 pretrained Diffusion 기반 이미지 편집 방법을 이용하여 장면을 반복적으로 편집하는 것을 시도했다. 하지만 세밀한 부분 편집이 불가능하고 Diffusion 모델의 사전 학습된 제한된 훈련 도메인 때문에 프레임 간에 일관성 없는 편집이 발생한다.
Ctrl-D는 단일 편집된 이미지만을 사용하여 IP2P를 reference 이미지로부터 “편집 능력”을 “학습”하게 fine tuning한다. 이를 통해 편집 중에 관련 영역에 집중할 수 있게 하여 안정성과 실용적 사용성을 향상시킨다. 이어서 3D Gaussian를 기반으로 하여 2단계에 걸쳐 Dynamic 3D scene editing의 효율성을 향상시키는 것을 목표로 한다.
Background
Dynamic 3D Gaussian Splatting
3D Gaussian Splatting은 위치(position) $x$, 불투명도(opacity) $σ$, quaternion $r$과 스케일링 $s$로부터 얻은 3D covariance $Σ$로 정의되는 3D Gaussian $G = (x, r, s, σ)$을 사용한다. 2D에서의 픽셀 $p$의 색상은 다음과 같은 스플래팅 렌더링 과정을 사용하여 렌더링된다:
\[C(p) = \sum_{i \in N} \alpha_i c_i \prod_{j=1}^{i-1} (1 - \alpha_j), \\ \alpha_i = \sigma_i e^{-\frac{1}{2} (p-\mu_i)^T \sum^{\prime}(p-\mu_i)},\]$\alpha_i$에서 $c_i$는 광선을 따라 각 3D Gaussian의 색상을 나타내며, $Σ’$는 해당하는 2D covariance 행렬이고, $μ_i$는 3D Gaussian이 2D로 투영된 $uv$ 좌표를 나타낸다.
Dynamic scenes 모델링에서 몇몇 연구는 canonical space에서 3D Gaussian을 학습할 수 있게 하고, 그 다음 변형된 3D Gaussian $G = (x+δx, r+δx, s+δx, σ)$을 래스터화 파이프라인에 넣는 deformation field를 도입하여 3DGS를 확장했다. 3D Gaussian의 시간 $t$와 위치 $x$를 입력으로 사용할 때, 변형 MLP는 다음을 예측한다.
canonical space : 동적이거나 변형 가능한 객체의 기준 형태나 상태를 참조하는 표준화된 공간
객체나 장면이 변형되기 전의 원래 형태나 구조를 나타내는 공간을 의미한다. 동적 3D 모델링에서는 객체가 시간에 따라 움직이거나 변형될 수 있다. 이러한 변형을 효율적으로 처리하고 이해하기 위해, 객체의 기준 상태를 “canonical space”에서 정의한다. 그 후, 실제 장면에서 객체가 어떻게 움직이고 변형되는지를 설명하는 변형 필드(deformation field)를 사용하여 이 canonical space에서의 정의를 현재 장면이나 상태로 매핑한다.
\[(\delta \mathbf{x}, \delta \mathbf{r}, \delta \mathbf{s}) = F_θ(γ(sg(\mathbf{x})), γ(t)),\]deformation field : 변형 공간 장면이나 객체의 기하학적 구조를 변형시키기 위한 벡터 필드를 말한다. 이 필드는 각 점의 변형을 정의하는 벡터를 포함하며, 이를 통해 원본 모델의 각 점을 새로운 위치로 이동시킨다.
여기서 $sg(·)$는 stop gradient 작업을 나타내고, $γ$는 위치 인코딩을 나타낸다.
InstructPix2Pix
InstructPix2Pix는 2D Diffusion Image Editing 방법이다. 이미지 $I$와 텍스트 $C_T$가 주어지면, IP2P는 $C_T$에 따라 $I$를 편집한 이미지 $z_0$를 생성하려 한다.
Diffusion 모델은 $z_t$(입력 이미지 or Noise)에 대해 timestep $t$ 에서의 Noise을 예측하며, denoising U-Net $ϵ_θ$를 사용한다. IP2P는 각 $(I, C_T)$ 에 대해 편집된 이미지 $I_\text{edited}$ 가 제공되는 데이터셋에서 훈련된다. 이 방법은 Latent Diffusion을 기반으로 하며, VAE를 포함한다. 학습 중에는 $z = E(I_\text{edited})$에 Gaussain Noise $ϵ ∼ N(0, 1)$을 추가하여 noise가 추가된 $z_t$를 얻으며, $t ∈ T$는 무작위로 선택된 timestep이다. denoiser $ϵ_θ$는 Stable Diffusion 가중치로 초기화되고 다음 Objective를 최소화하기 위해 fine-tuning된다:
\[\mathbb{E}_{I_\text{edited},I,C_T,ϵ,t} \left[ \|ϵ - ϵ_θ(z_t, t, I, C_T)\|^2_2 \right].\]학습 데이터에서 $I = \varnothing_I$, $C_T = \varnothing_T$, $(I = \varnothing_I, C_T = \varnothing_T)$ 조건을 각각 5%씩 할당하며 Image Guidance scaling $s_I$ 와 Text Guidance scaling $s_T$로 제어할 수 있다.
Method
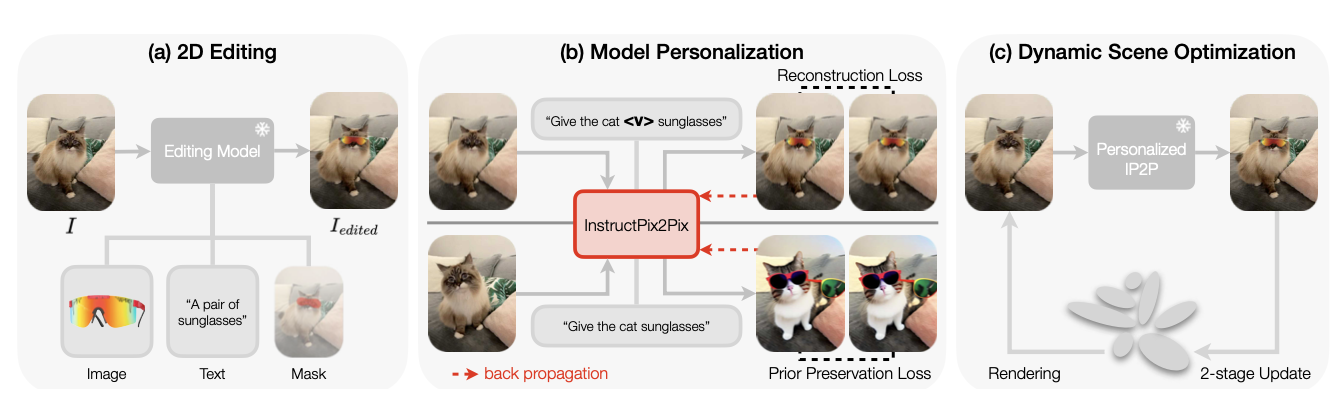
Personalization of InstructPix2Pix
$I_\text{edited}$와 원본 이미지 $I$를 얻은 후, IP2P의 U-Net $ϵ_θ$를 fine-tuning하여 개인화된 편집 모델을 생성한다.
이를 위해서는 편집 task을 정확하게 설명하는 text 지시가 필요하다. 초기에는 GPT-4V를 사용하여 편집을 설명하는 초기 text 지시 $C^*_T$를 생성하고, 편집 대상을 설명하는 마지막 명사나 형용사 앞에 specialized token <$V$> 를 추가한다. 이를 통해 맞춤형 텍스트 프롬프트 $C_T$를 생성한다.
IP2P의 일반화 능력을 유지하기 위해, DreamBooth의 prior preservation loss을 통합하며, 입력은 다음과 같다.
- 초기 텍스트 지시 $C^*_T$
- 동적 장면 데이터셋에서 무작위로 선택된 프레임 $I_{d}$,
- 원래 IP2P가 텍스트 condition $C_T^* $와 이미지 condition $I_d$로 생성한 이미지 $I^*_\text{edited}$
이 설정은 모델이 새로운 편집을 학습하면서도 이전 지식을 보존할 수 있도록 한다.
Fine-tuing Loss function는 두 가지 term으로 구성된다. main term은 target 편집 이미지에서 예측된 noise와 실제 noise 사이의 오차를 최소화하고, prior preservation term은 모델이 원래 편집 기능을 일반화하는 것을 잃지 않도록 보장한다.
\[\mathcal{L}_\text{fine-tune} = \underbrace{\mathbb{E}_{I_\text{edited},I,C_T,ϵ,t} \left[ \|\epsilon - \epsilon_{\theta}(z_t, t, I, C_T)\|^2_2 \right]}_{\text{main}} + \underbrace{\lambda \mathbb{E}_{I*\text{edited},I_d,C^*_{T},ϵ,t} \left[ \|\epsilon - \epsilon_{\theta}(z^*_t, t, I_d, C^*_{T})\|^2_2 \right]}_{\text{prior preservation}},\]여기서 $z_t$는 편집된 입력 이미지에서 추출된 noise한 latent representation의 timestep $t$를 나타내고, $z^*_t$는 prior preservation에 사용된 해당 변수를 나타낸다. $λ$는 prior preservation term의 가중치를 조절하는 parameter이다.
Data augmentation
DreamBooth에서 fine-tuning은 일반적으로 3~5개의 이미지를 필요로 하지만, 이 연구에서는 동일한 편집 효과를 달성하는 여러 쌍의 이미지를 얻는 것이 어렵다. 단일 이미지 pair만 사용할 경우, overfitting과 model collapse를 초래할 수 있다.
이러한 제한을 극복하기 위해, source 및 편집된 이미지에 대해 otation, translation, shear과 같은 affine transformations을 적용하는 간단하고 효과적인 데이터 증강 기술을 사용한다.
Optimization of Dynamic 3D Gaussians
Dynamic 3D Gaussians를 편집하기 위해 2 단계 Optimization 방식을 제안한다.
- 단일 이미지 편집 단계에서 편집된 이미지를 keyframe으로 사용하여 장면의 canonical space를 Optimization하면서 동시에 Gaussian density를 높인다.
- deformation field 와 3D Gaussian을 모두 최적화한다.
Stage 1: Keyframe-guided Gaussian densification
편집된 2D 이미지를 reference keyframe으로 사용하여 Dynamic scene의 canonical space를 최적화한다. 이 단계에서는 deformation field를 고정하고 3D Gaussian을 fine tuning한다.
원래의 3DGS는 Adaptive Control of Gaussians를 도입하며, Gaussian의 density를 적응적으로 제어한다. Ctrl-D에서는 유사한 적응 스키마를 사용하고 위치 gradient를 활용하여 밀도화가 필요한 영역을 식별한다. 편집된 2D 이미지와 gradient를 기반으로 3D Gaussian을 최적화함으로써 전체 최적화를 가속화한다.
Stage 2: Optimization on both deformation fields and 3D Gaussians
Gaussian의 수를 고정, deformation field와 3D Gaussian을 모두 최적화한다.
Instruct-NeRF2NeRF처럼 비슷한 절차를 적용하고, Iterative Dataset Update (Iterative DU)를 사용하여 각 iteration마다 데이터셋 이미지를 그 편집된 이미지로 교체한다. 각 iter에서 편집하지않을 frame을 무작위로 선택하고, personalizing된 IP2P를 사용하여 해당 편집된 이미지를 생성하고 edited image buffer 에 추가한다.
deformation field와 3D Gaussian은 edited image buffer 기반으로 학습된다. 이 Warm-up 단계에서는 모든 이미지가 한번 이상 편집되어 edited image buffer에 모든 이미지가 포함되면, Iterative Dataset Update과 방식이 일치한다.
Warm-up 이후, 초기 결과는 합리적인 시간적 일관성을 보여준다. 이 시간적 일관성을 더욱 향상시키기 위해, temporal loss $L_\text{temp}$를 도입하여 인접된 프레임 간의 차이를 최소화한다. 전체 loss는 다음과 같다.
\[\mathcal{L} = (1−λ_d)\mathcal{L}_1 + λ_d\mathcal{L}_\text{D−SSIM} + λ_t\mathcal{L}_\text{temp},\]첫번째, 두번째 항은 3DGS에서 적용된 loss이다.
Experiments

qualitative한 결과는 위와 같다. 텍스트와 이미지 프롬프트 편집, Style transfer 모두 높은 fidelity, 품질, controllability를 볼 수 있다. 모든 scene에서 강력한 시간적, multi-view 일관성을 유지한다. 또한 local 편집을 효과적으로 수행하여 관련 없는 영역을 그대로 보존하는 것을 볼 수 있다.
Dynamic scene editing methods와 비교

Instruct 4D-to-4D와의 결과를 비교한 것이다.
Video editing methods와 비교

AnyV2V와 비교한 결과이다. 첫 번째 프레임만 편집한 후 나머지 프레임으로 변경 사항을 전파한다.
Ctrl-D는 첫 번째 프레임(가장 왼쪽 이미지)을 편집하고, Dynamic scene Optimization 없이 개인화된 IP2P 모델을 직접 사용하여 결과를 생성하며 훨씬 높은 품질과 일관된 결과를 보여준다.
반면, AnyV2V의 결과는 흐릿하고 프레임 간 일관성이 떨어진다. 길이가 길어질수록 AnyV2V는 점점 더 불안정해지고 낮은 품질의 결과를 생성한다.
Ctrl-D는 Muti-view scene에서도 일관성을 유지하는 데 효과적인 반면 AnyV2V는 Muti-view scene를 유지하는 데 어려움을 겪는다.
Data Augmentation

Augmentation의 유/무 결과를 비교한 결과이다.
Edited image buffer

Edited image buffer의 효과를 평가한다.
- 모든 프레임에서 무작위로 프레임을 선택
- Edited image buffer에서 특별히 프레임을 선택.
1000회 최적화 반복으로 실행하며, buffer를 사용했을때는 성공적으로 편집된 결과를 생성하는 반면, 다른 변형은 원본 장면과 거의 동일한 결과를 생성한다.
Editing Ability Generalization

Ctrl-D의 Personalization은 IP2P가 reference를 기반으로 새로운 편집 능력을 “학습”한다고 볼 수 있다. 이 편집 능력의 Generalization 능력을 확인하기 위해, 2D 고양이 이미지에 특정 선글라스를 추가하는 편집을 IP2P를 fine-tuning하는 데 reference로 사용한다. 이후 IP2P는 학습된 편집 능력을 얼굴과 전신에 적용한다. 결과는 안정적이며 고품질로, 높은 일반화 능력을 보여준다.
Limitation

Ctrl-D는 고품질의 편집 결과를 제공하지만, Reconstruction Backbone과 IP2P에서 몇 가지 한계가 있다.
첫 번째 줄에서 훈련된 Dynamic 3D Gaussian scene이 움직이는 손과 같은 detail한 부분에서 선명하게 렌더링하지 못했을 때, 이 이미지를 기반으로 편집을 수행하여 결과적으로 흐릿하고 불명확한 결과를 초래한다.
Personalized IP2P는 여전히 빈 영역에 복잡한 contents을 잘 추가하지 못한다.
개에게 가방을 추가하려했지만, 모델은 여러 관점에서 가방을 일관되게 렌더링하는 데 실패한 것을 볼 수 있다. 이는 IP2P가 빈 영역에 복잡한 contents를 추가하지 못하기 때문이다.