[Paper Review] DCGAN
[논문 리뷰] Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks - DCGAN
논문 제목은 Unsupervised representation learning with Deep Convolusional Generative Adversarial Networks이다. (arxiv)
이 논문에서 강조하는 점은 GAN의 안정화 측면이다. 앞의 GAN 포스트에서 말했듯이, minmax 게임을 풀어나가는 GAN은 이론적으로는 수렴할지라도, 실제 train할 때에는 이론적 가정이 깨지면서 불안정한 면을 보이기도 했다.(GAN 논문에서는 그럼에도 불구하고 좋은 성능을 보이므로 합리적인 모델임을 시사했다.) 이러한 GAN의 단점을 커버한 것이 DCGAN이다. 이 논문이 발표된 후에 나온 GAN 모델의 구조는 모두 DCGAN의 구조에 베이스를 두었다고 볼 수 있다.
Introduction
DCGAN은 기존 GAN의 구조를 변형하여 CNN을 적극적으로 활용한다. 이로 인해 이미지의 고차원과 고정밀 특성을 더 잘 다룰 수 있게 하였다.
논문에서 다음과 같은 내용을 다룬다.
- 대부분의 환경에서 안정적인 학습이 가능한 Convolutional GAN을 제안
- 훈련된 Discriminator(판별자)로 Classification에서 다른 unsupervised 알고리즘보다 좋은 성능을 보여준다.
- 학습된 필터를 시각화하여 특정 filter가 특정 object를 그리는 방법을 학습했음을 보여준다.
- Generator가 생성된 sample의 의미적 특정을 조작할수 있는 벡터 특성을 가짐을 보여준다.
Approach and Model Architecture
DCGAN은 CNN의 아키텍쳐에서 3가지 특징을 가져왔다.
1. Spatial Pooling 함수를 Stride Convolution으로 대체
Downsampling 기법중 하나인 spatial pooling은 일반적으로 maxpooling 등의 함수를 사용한다. DCGAN에서는 pooling 함수을 사용하는 대신, Convolution layer가 이 과정을 학습하도록 한다. Generator는 spatial upsampling을, Discriminator는 spatial downsampling을 가능하게 학습하였다.
2. Fully-connected layer 제거
Fully-connected layer는 주로 네트워크의 마지막 부분에 위치하며 이전 계층에서 추출된 모든 특성을 종합하여 최종 출력을 만드는 것이 목적이다. 예시로는 당시 많이 쓰이던 global average pooling이 있다. global average pooling은 모델의 안정성은 높이지만, 모델의 수렴 속도를 저하시킨다.
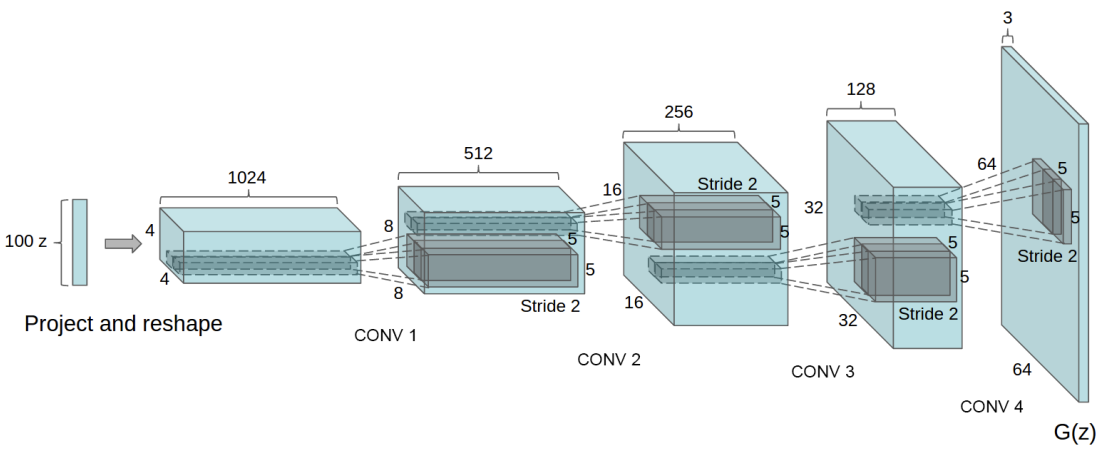
DCGAN에서는 필요한 부분인 $G$의 input 부분과, $D$의 output부분을 제외하고 Fully-connected layer를 제거하였다. $G$에 입력되는 Noise 데이터의 행렬곱셈이 사용되며, $D$에서는 마지막 Convolution layer를 flatten한 후, Sigmoid 함수에 제공한다.
3. Batch Normalization
Batch Normalization은 Input 데이터의 평균과 unit variance가 0이 되도록 정규화하여 학습을 안정화시킨다. 하지만 모든 layer에 적용시켰을 때에는 문제가 생겨서, $G$의 output layer와 와 $D$의 input layer에 적용시키지 않았다.
추가로 Generator에서 tahn 함수를 activation 함수로 사용하는 output layer를 제외하고 ReLU를 사용하였으며, Discriminator에서는 모든 layer에 Leaky ReLU를 사용하였다.
논문에서 안정적인 DCGANs를 위한 가이드라인을 작성하였다.

Details of Adversarial Training
DCGAN은 LSUN, Imagenet-1k, 새로 수집한 Faces dataset 3가지 데이터셋으로 학습하였다.
Train Detail
- tahn 활성화 함수 범위인 [-1, 1]로 데이터셋 preprocessing
- Mini-batch Stochastic gradient descent를 사용하였으며 배치 크기는 128
- 표준편차 0.02의 정규분포로 weight 초기화
- Adam Optimizer, Learning rate는 0.0002
- momentum $\beta_1$의 권장값인 0.9은 불안정, 0.5가 안정
$\beta$는 Momentum 알고리즘에서 사용하는 값이다. Momentum 알고리즘이란, Gradient descent에서 기울기(gradient)의 가중 평균치를 산출하여 weight를 업데이트하는 것이다. Momentum을 사용함으로써, 속도가 빠르고 SGD가 over shooting, diverging 되는 것을 방지하며 local minimum 탈출이 가능하다.
DCGAN은 Generator가 단순히 Train 데이터를 overfitting과 memorizing 하지않는다는 것을 보여준다.

위 사진은 Train이 epoch 1 진행되었을 때 sample이다. Epoch을 한번 학습시켰을때 SGD 기법이 데이터를 memorization할 수 없기 때문에, memorization 기법을 사용하지 않는다는 증거가 된다.
위 사진은 Epoch 5의 sample이다. 이미지에서 여전히 noise가 생성된 부분이 보이기 때문에, 아직underfitting 되었음을 알 수 있다.
Empirical Validation of DCGANs capabilities

위 표는 학습된 DCGAN과 다른 모델 간의 CIFAR-10 데이터셋 Classification 결과이다. DCGAN은 CIFAR-10이 아닌, Imagenet-1k로 학습되었으며 그 feature들이 CIFAR-10을 Classification하는데 사용되었다.
Investigating and Visualizing the internals of the Networks
논문에서는 다양한 방법으로 Train된 $D$와 $G$를 살펴보았다.
Walking in the Latent Space
Latent Space($G$의 input data 공간 $z$)상에서 급격한 변화는 memorization의 흔적이라고 할 수 있다. Generator가 memorization한다는 것은 overfitting되어 Train 데이터와 latent $z$가 1대1로 mapping되었다는 것을 의미한다. 이는 $z$가 변화할 때 갑작스럽게 변화한다는 것을 통해 확인 할 수 있다. Latent Space를 거치면서 이미지 생성 과정에서 생기는 의미적인 변환은 모델이 잘 학습되고 있다는 것을 의미한다. 여기서 의미적인 변환이란, 물체가 생기거나 제거되는 등의 변환을 말한다.

위 이미지를 보면 이미지가 갑작스럽게 변하지 않고 자연스럽게 변환되는 것을 볼 수 있다.
Visualizing the Discriminator Features
이전 연구에서 대규모 데이터셋으로 학습된 CNN의 supervised training(지도학습)이 성능이 매우 좋다는 것을 보였고, 학습할때 객체 감지를 학습한다. DCGAN 역시 흥미로운 feature를 학습한다.

우리가 주목해야할 점은 오른쪽 Trained filters이다. 이는 $D$의 마지막 convolution layer에서 학습한 6개의 convolution feature이다. 이는 discriminator가 침대와 창문 같은 침실의 특징을 학습하였음을 알 수있다.
Manipulating the generator representation
Forgetting to draw certain object
앞에서 $D$가 어떠한 feature를 학습하는지 알아보았으며 $G$에 대해서도 알아보자. 생성된 sample을 보면, $G$가 침대, 창문, 램프 등의 특정 물체들을 학습하였음을 알 수 있다. 이러한 표현이 어떻게 이뤄지는지를 살펴보기 위해 논문에서는 창문이라는 물체를 제거하는 실험을 진행하였다.
150개의 셈플에서 52개의 창문에 bounding box를 그리고, 해당 box부분에 대한 feature map을 삭제하여 다시 새로운 sample을 생성하여 삭제되지 않은 채 생성한 sample과 비교하였다.

윗줄을 보면 창문을 생성한 것을 볼수 있으며, 아랫줄은 노이즈가 많이 있지만 창문이 있는 위치에 거울이나 문과 같은 다른 물체를 생성하는 등 $G$가 배경 표현과 객체 표현을 분리하여 생성함을 알 수 있다.
즉 $G$의 각 filter가 데이터셋이 포함된 여러 객체들을 나누어 담당하고 있음을 시사한다.
Vector arithmetic on Face sample
이 파트에서는 Face sample에 대한 vector 산술 연산을 다룬다.
인간은 King - Man + Woman이 Queen을 의미함을 의미론적 추론으로 알 수 있지만 컴퓨터는 이러한 추론을 할 수 없다. 하지만 vector(‘King’) - vector(‘Man’) + vector(‘Woman’)과 같이 각 단어의 의미를 포함하는 vector로 산술 연산을 진행할 경우, 결과에 가장 가까운 vector인 vector(‘Queen’)을 도출해낼 수 있다.
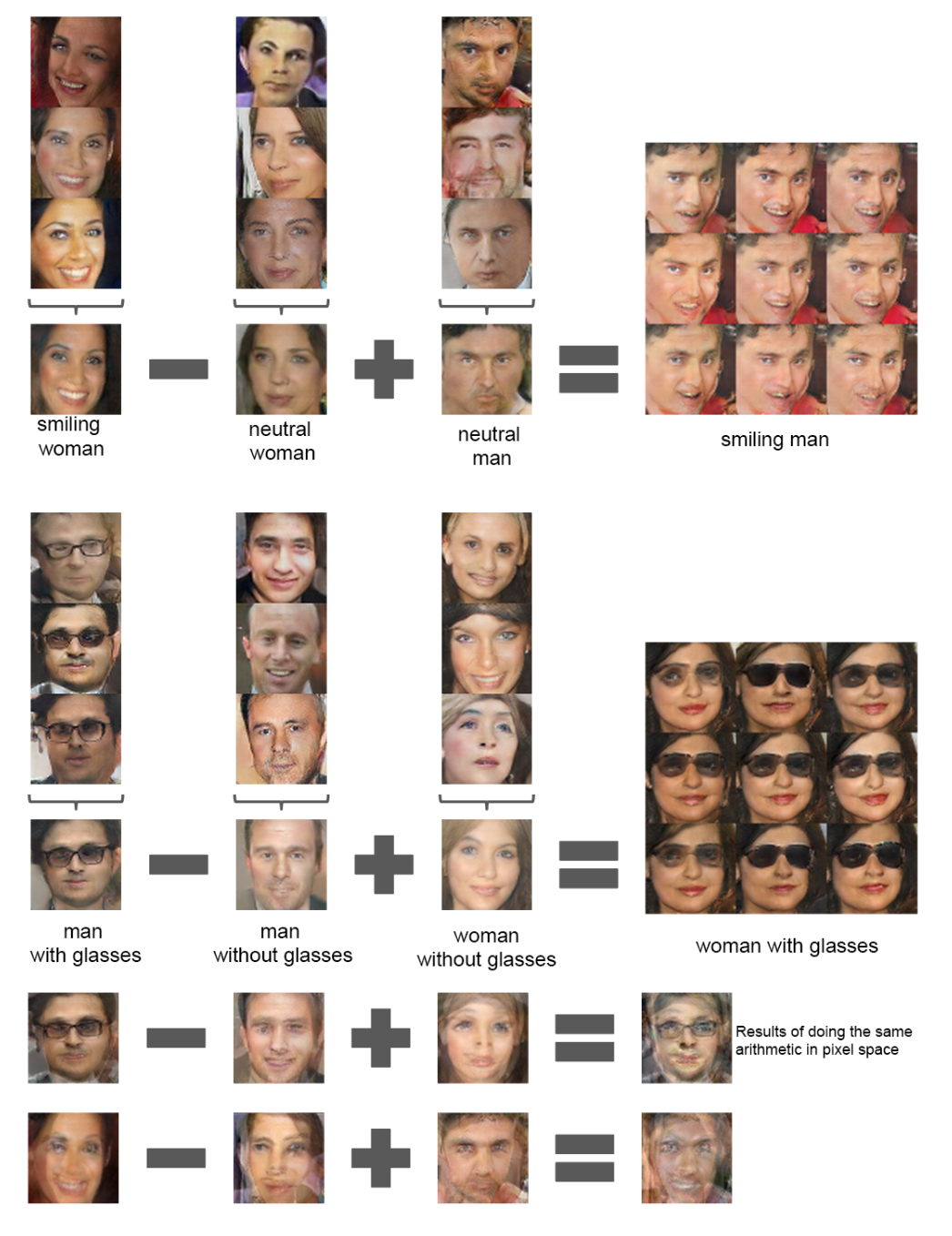
논문에서는 $G$의 $z$에도 유사한 구조가 나타나는지 살펴보았으며, 3개의 예제의 $z$ vector 평균을 구하여 $z$ space에서 linear하게 모델링하여 의미론적으로 안정된 sample을 생성하는 것을 확인하였다.
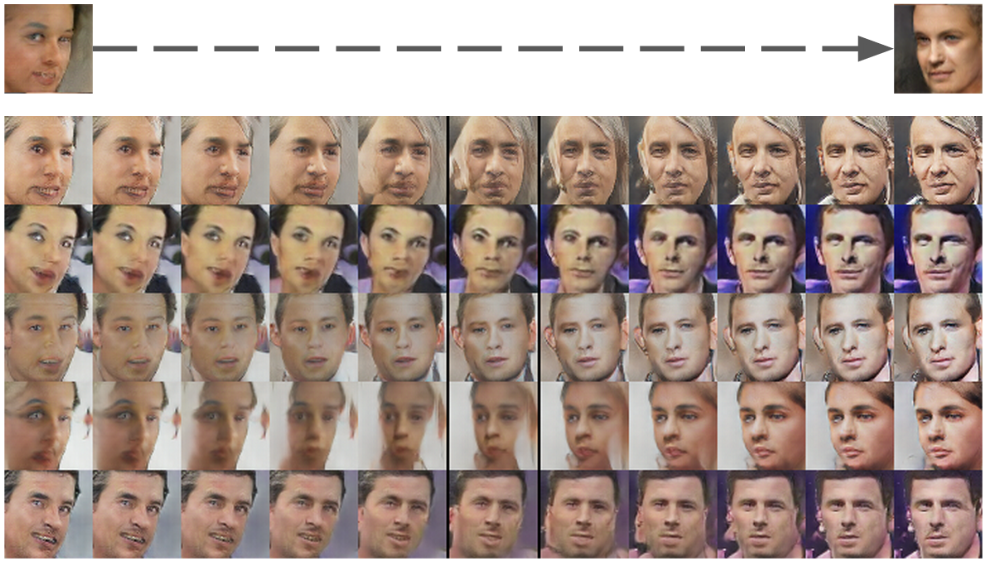
위 그림은 좌/우을 바라보는 얼굴 sample을 선형적으로 Interpolation하여 변환시킨 것이다.
Conclusion (정리)
- 이미지 생성 성능 향상: DCGAN은 Convolutional layer를 사용함으로써 이미지의 지역적 특성을 보다 효과적으로 학습한다. 이로인해 더 고화질이고 실제와 유사한 이미지를 생성할 수 있다.
- 학습의 안정화: DCGAN은 Batch Normalization, Leaky ReLU 등의 기법을 도입하여 GAN의 학습을 보다 안정화시켰다. GAN은 Generator와 Discriminator의 학습이 균형을 이루어야 하는데, 이 과정에서 발생할 수 있는 불안정성을 감소시켰다.
- Latent Space의 해석 가능성: DCGAN은 Latent Space(잠재 공간)의 각 차원이 의미 있는 정보를 인코딩하고, 이를 통해 새로운 이미지를 생성할 수 있음을 보여주었다.
- 신경망 구조의 표준화: DCGAN은 GAN의 구조를 표준화하는 데 기여했다. DCGAN이 제안한 구조는 그 이후의 많은 GAN 연구에서 기반으로 사용되었다.