[Paper Review] DINO
[논문 리뷰] Emerging Properties in Self-Supervised Vision Transformers (DINO)
Emerging Properties in Self-Supervised Vision Transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv´ e Jegou, Julien Mairal, Piotr Bojanowski, Armand Joulin
Facebook AI Research | Inria | Sorbonne University
ICCV 2021
DINO는 NLP의 BERT처럼, ViT 기반에서 unlabeled 데이터로 뛰어난 representation 학습을 가능케 한 self-supervised learning 프레임워크이다.
Background
Vision Transformer: ViT
- Patch Embedding: 이미지를 $N\times N$ 픽셀 patch로 잘라 일종의 “단어” token으로 변환한다.
- $\texttt{[CLS]}$ token: Transformer 입력 시 맨 앞에 추가하는 학습 가능한 벡터로, 전체 이미지 표현을 모으는 역할을 맡는다.
- Multi-Head self attention: patch 간 관계를 전역적(global)으로 파악한다. 여러 head가 서로 다른 패턴·객체에 주목한다.
- Patch size(/16, /8 등): patch가 작아질수록 공간 해상도가 높아지지만 연산량이 증가한다. 논문에서는 작은 patch(/8)가 attention으로 객체 경계를 잡는 데 유리함을 보인다.
Self-supervised learning (SSL)
Label 없음: 정답 label을 쓰지 않고 입력 자체 변형(view)들 간 일관성이나 대조를 학습 신호로 삼는다.
Collapse 문제: 모델이 모든 입력에 대해 같은 출력을 내는 ‘무의미한’ 상태로 수렴할 위험이 있다.
평가 프로토콜
- Linear Probe: backbone을 고정하고 선형 classifier를 학습해 표현 품질을 측정
- k-NN: 학습 없이 Nearest Neighbor로 바로 분류한다. feature space가 얼마나 구조화됐는지 가늠할 수 있다.
주요 패러다임
계열 대표 기법 핵심 아이디어 Collapse 방지 방법 Contrastive Learning SimCLR, MoCo 같은 이미지 view는 끌어당기고, 다른 이미지는 밀어낸다. 대규모 negatives 샘플(negatives) 필요 Clustering/할당 매칭 SwAV 여러 view를 동일 cluster에 할당하도록 강제 Sinkhorn-Knopp 정규화로 균형 유지 Self-Distillation BYOL, DINO 모멘텀 teacher 출력 ≈ student 출력이 되도록 학습 모멘텀 teacher + 예측기(BYOL) 또는 Centering, Sharpening(DINO)
Knowledge Distillation
Teacher 모델이 학습한 지식을, Student 모델이 더 잘 따라 배우도록 유도하는 학습 기법
Teacher
성능이 뛰어난, 크고 복잡한 모델 (예: ensemble 모델, BERT-Large, ViT-Large 등)
일반적으로 많은 계산 자원과 긴 학습 시간을 들여 훈련됨
Student
더 작고 가벼운 모델 (예: MobileNet, DistilBERT 등)
inference 시 빠르고 효율적이어야 하는 상황에서 사용
Teacher의 출력 분포(soft labels)에는 정답 이외의 추가적인 계층 구조/상관관계 정보가 포함되어 있음
예: “고양이 vs 강아지 vs 호랑이”에서 고양이=정답일 때,
Teacher softmax가 [0.87, 0.10, 0.03]이라면 → 고양이와 호랑이는 관련 있음
반면 hard label은 그냥 [1,0,0]이므로 정보 loss
Student은 이 soft 분포를 모방하도록 학습함으로써 더 풍부한 표현을 학습한다.
loss은 보통 두 가지 loss을 더해 학습함:
\[\mathcal{L}_{\text{total}} = \alpha \cdot \mathcal{L}_{\text{hard}} + (1-\alpha) \cdot \mathcal{L}_{\text{soft}}\]- $\mathcal{L}_{\text{hard}}$: teacher 없이 원래 정답에 기반한 일반 cross-entropy
- $\mathcal{L}_{\text{soft}}$: teacher softmax 결과와 student softmax 결과의 cross-entropy
DINO를 위한 필수 개념
Softmax의 온도(temperature) $\tau$
일반 softmax:
$p_i=\frac{\exp(z_i)}{\sum_j \exp(z_j)}$
여기서 $z_i$는 logit이다.
온도 $\tau$를 넣은 softmax:
$p_i(\tau)=\frac{\exp(z_i/\tau)}{\sum_j \exp(z_j/\tau)}$
- $\tau \downarrow$ (작게): 분포가 뾰족(sharp)해진다. 큰 로짓 하나가 확률을 거의 독점한다.
- $\tau \uparrow $ (크게): 분포가 평탄(smooth)해진다. 확률이 고르게 퍼진다.
간단 예시(로짓 [2,1,0]):
- $\tau=1$ → 대략 $[0.665, 0.245, 0.090]$
- $\tau=0.5 $ → $[0.867, 0.117, 0.016]$ (더 뾰족)
- $\tau=5$ → $[0.402, 0.329, 0.269]$ (더 평탄)
ViT에서 나타나는 Emerging Properties
자가 supervised learning(self-supervised learning)을 통해 ViT 모델이 별도 감독 없이 얻게 된 고차원적인 능력이나 표현 구조.
- Attention 기반 객체 경계: self-supervised ViT의 마지막 Attention head들은 별도 학습 없이도 객체 mask에 해당하는 패턴을 형성한다.
- k-NN 친화적 feature space: 단순 거리 기반으로도 높은 분류 정확도를 달성한다는 사실은 feature들이 클래스별로 잘 분리되어 있음을 뜻한다.
Metric
- Top-1 / Top-5 Accuracy: 분류 정확도. ImageNet 선형 평가에서 성능 비교에 사용.
- mAP (Mean Average Precision): 이미지 검색이나 복제 탐지에서 랭킹 품질을 측정한다.
- J & F: 비디오 객체 분할 성능(영역 일치도 Jaccard + 경계 품질 F)을 나타내는 지표.
Introduction
CNN 기반의 Self-supervised learning 기법들은 최근 몇 년간 큰 성공을 거두며 이미지 표현 학습의 가능성을 보여주었다.
대표적인 예로 SimCLR, MoCo, SwAV, BYOL 등이 있는데, 이들은 구조적으로 유사한 틀 안에서 각각의 아이디어로 모델 붕괴(collapse) 현상을 피하거나 성능을 높였다 . 예를 들어,
- SimCLR: 대규모 배치에서 contrastive learning으로 이미지를 비교
- MoCo: 모멘텀 인코더와 메모리 뱅크를 도입해 많은 negative sample을 효율적으로 활용
- SwAV: Clustering을 활용하여 데이터 augmentation된 view들의 Cluster 할당을 맞춤
- BYOL: 모멘텀 기반의 teacher network와 예측기를 사용해 self-distillation 방식으로 학습
- 별도의 Negative sample 없이 collapse를 방지
이런 기법들을 통해 label 없이도 이미지에서 유용한 표현을 학습할 수 있음이 입증되었고, 대규모 이미지 데이터셋에 대한 self-supervised 사전학습이 점차 주목받게 되었다.
Vision Transformer (ViT)는 NLP에서 Transformer가 그랬듯 이미지 영역에서도 잠재력이 큰 모델이지만,
- 대용량의 학습 데이터와 막대한 연산량이 필요
- supervised learning된 ViT의 feature 표현이 특별히 뛰어난 점도 없다
위와 같은 한계가 보고되었다.
이러한 배경에서, Transformer의 성공 비결 중 하나가 대규모 self-supervised 사전학습(BERT의 mask 예측, GPT의 언어 모델링 등)이라는 점에 착안하여 , ViT에도 Self-supervised learning을 적용하면 새로운 장점이 나타나지 않을까? 하는 의문이 제기되었다.
이미지 자체에서 얻을 수 있는 풍부한 신호로 ViT를 학습시키면 ConvNet과는 다른 고유한 표현 능력을 이끌어낼 수 있을 것으로 기대한 것이다.
이 DINO(Distillation with No labels) 논문의 핵심 질문은 “Self-supervised learning을 거친 Vision Transformer는 과연 ConvNet과 질적으로 다른 특성을 보이는가?” 이다.
결과로는 두 가지 특성이 드러났다:

self-supervised 방식으로 학습한 ViT의 self-attention map을 들여다보면 이미지의 장면 구성과 객체 경계 정보가 명시적으로 나타난다
마지막 layer의 여러 attention head들이 집중한 영역을 시각화하면 segmentation 결과와 유사
supervised learning ViT와 ConvNet 기반 모델에서 발견되지 않은 특성
→ 즉, self-supervised ViT는 이미지의 형태와 구성을 더 잘 파악
self-supervised ViT의 feature representation은 매우 단순한 KNN classifier만으로도 뛰어난 인식 성능을 보임
- ViT-small 모델의 경우 ImageNet 테스트에서 k-NN 분류로 Top-1 정확도 78.3%를 달성
- 별도 classifier, 데이터 Augmentation, Fine-tuning 없이도 기존 모델의 선형 분류 성능에 육박
- k-NN만으로 높은 정확도를 얻을 수 있다?
- self-supervised ViT가 학습한 feature space가 잘 구조화되어 있어 클래스들이 명확히 구분
- 이또한 Conv 기반 self-supervised 모델에서는 발견되지 않은 현상
- ViT-small 모델의 경우 ImageNet 테스트에서 k-NN 분류로 Top-1 정확도 78.3%를 달성
요약하면, Self-supervised learning된 ViT에서는 기존에 없던 고유한 특성들이 발현
- attention을 통한 객체 구조 파악
- 뛰어난 feature 분별력
이 두 가지 발견은 ViT의 가능성을 새롭게 부각시키는 것으로, 저자들은 어째서 이러한 특성이 ViT에서 나타나는지, 그리고 이러한 특성을 끌어낸 Self-supervised learning 기법(DINO)의 구성 요소는 무엇인지를 심도 있게 분석하고 있다.
Goal
Vision Transformer(ViT)에 특화된 Self-supervised 학습 프레임워크를 설계하고, 이를 통해 label 없이도 의미 있는 시각 표현(visual representation)이 자연스럽게 형성되는지 확인하는 것
구체적으로는:
별도의 supervision 없이 ViT가 어떤 고수준 표현을 자발적으로 학습하는지를 실증적으로 탐색한다.
ViT 구조에 맞는 새로운 self-distillation without labels 방법론을 설계하여,
- label 없이도 의미 있는 표현 학습
- object-level segmentation 등 Emerging Properties의 자연스러운 출현 확인
Motivation
CNN 기반 self-supervised 방식의 한계
기존 Self-supervised 학습(SimCLR, MoCo 등)은 대부분 CNN에 기반
CNN은 국소 필터/계층적 구성에 따라 inductive bias가 강해, global semantics를 잘 반영하기 어려움
반면 ViT는 global self-attention으로 전역적 구조나 의미 정보를 잘 포착할 수 있음
→ ViT에 특화된 SSL 방법 필요
ViT의 표현 학습 방식에 대한 미지의 영역
ViT가 label 없이 학습될 때 어떤 표현을 만들고, 그것이 어떤 특성을 띄는지에 대한 연구는 거의 없음
특히 attention 구조가 의미 정보(예: 객체 윤곽)를 내포할 수 있는지 여부는 실험적으로 미확인 상태
“지도 없이도 구조가 생겨나는가?”라는 근본적 질문에 접근하고자 함
Contributions
DINO: label 없는 self-distillation 프레임워크 제안
모멘텀 인코더를 활용한 teacher-student 구조
multi-crop strategy + centering + sharpening으로 collapse 방지
별도의 정답 label 없이도 Student이 Teacher 출력을 모방하면서 의미 있는 표현을 학습함
- ViT에서의 Self-Supervised 학습이 만들어내는 Emergent Behavior 발견
- 학습된 attention head가 객체의 형태와 경계를 자발적으로 분할함
- 학습 후 feature 공간은 단순 k-NN만으로도 고성능 분류가 가능할 만큼 구조화되어 있음
- 이러한 표현은 semantic segmentation, image retrieval, copy detection 등 다양한 태스크로 전이 가능함
Self-Supervised ViT의 설계 요소에 대한 체계적 분석
모멘텀 인코더, 패치 크기, multi-crop, projection head 등 설계 요소들의 영향 분석 (ablation study)
특히 Teacher-Student 구조의 역할, 센서링/Sharpening이 collapse를 막는 원리를 실증적으로 검증
Approach
DINO(self-DIstillation with NO labels)는 label 없이 진행되는 self-distillation 방식의 Self-supervised learning 프레임워크이다.
Self-Supervised Learning with Knowledge Distillation
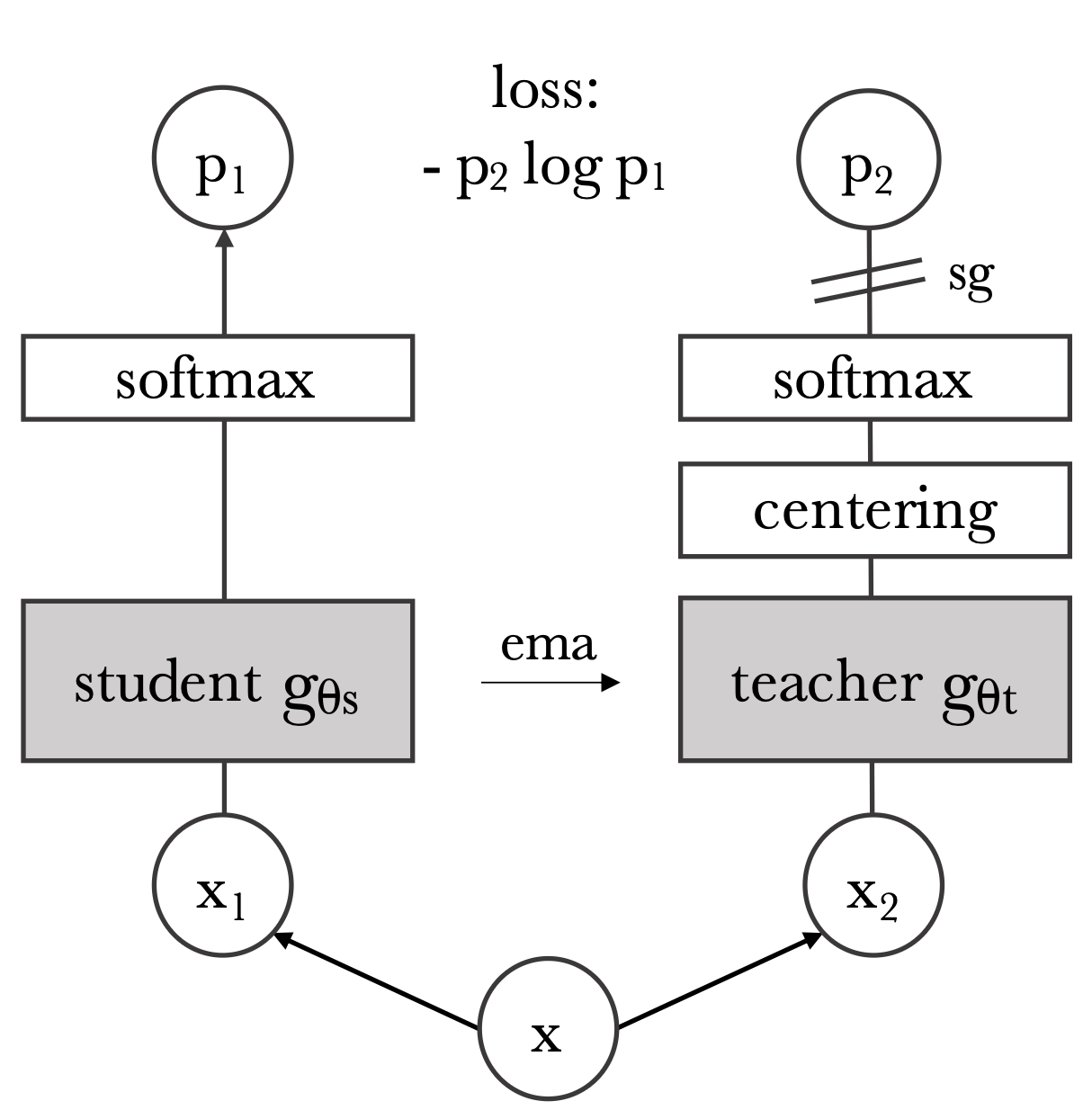
핵심 아이디어는 Knowledge distillation에서 파생되었다.
Knowledge distillation란 주어진 Teacher 네트워크 $g_{\theta_t}$의 출력을 Student 네트워크 $g_{\theta_s}$가 모방하도록 훈련하는 학습 패러다임이다.
즉, Teacher 네트워크와 Student 네트워크 두 개의 모델을 운용하며, student ViT가 입력 이미지에 대한 teacher ViT의 출력을 예측하도록 학습하는 것이다.
이때 teacher network에는 정답 label이나 별도의 supervison이 전혀 없으며, 단지 student의 과거 상태를 반영한 모멘텀 EMA 모델이 teacher 역할을 한다.
입력 이미지 $x$에 대해 두 네트워크는 Multi-view를 입력받아 각각 $K$차원 확률 분포 $P_s$, $P_t$를 출력한다.
$K$차원 벡터를 확률분포로 해석하기 위해 temperature 조절 softmax를 적용
$P_s$ 분포는 student 출력 $g_{\theta_s}$를 온도 $τ_s$로 softmax 정규화하여 얻는다.
\[P_s(x)^{(i)} = \frac{\exp(g_{\theta_s}(x)^{(i)} / \tau_s)}{\sum_{k=1}^K \exp(g_{\theta_s}(x)^{(k)} / \tau_s)},\]- $\tau_s > 0$ : softmax의 출력 분포의 날카로움을 조절하는 temperature 파라미터이다.
Teacher $P_t$도 같은 방식으로 계산되며 $\tau_t$를 따르지만, 추가로 centering과 sharpening을 적용한다. (뒤에서 추후 설명)
\[P_t(x)^{(i)} = \frac{\exp\left((g_{\theta_t}(x)^{(i)} - c^{(i)}) / \tau_t\right)}{\sum_{k=1}^K \exp\left((g_{\theta_t}(x)^{(k)} - c^{(k)}) / \tau_t\right)}\]Teacher는 stop-gradient로 고정
Student의 과거 상태만 반영하며, 학습이 이루어지지는 않음
- $g_{\theta_t}(x) \in \mathbb{R}^K$: teacher 네트워크의 K차원 출력
- $c \in \mathbb{R}^K$: center 벡터, 해당 배치의 평균값을 지수이동평균(EMA)으로 누적한 것 - centering
- $\tau_t$: 낮을수록 sharp한 분포가 됨 - sharpening
DINO의 학습 목표는 student 분포 $P_s$가 teacher 분포 $P_t$를 닮게 만드는 것이며, 이를 위해 아래 Loss를 최소화한다.
\[\min_{\theta_s} H(P_t(x), P_s(x))\]- $H(a, b) = - a \log b$ : cross entropy loss
이러한 knowledge distillation 수식을 Self-supervised learning으로 확장한다.
먼저, multi-crop 전략을 사용해 입력 이미지 $x$로부터 여러 view(=변형된 이미지) 집합 $ V$를 아래와 같이 생성한다.
기존 방식들은 크기가 비슷한 crop 2개만 사용 → 시야가 좁고 다양성 부족.
- SimCLR나 MoCo-v2는 contrastive loss로 학습되며, 일반적으로 positive pair 한 쌍만 필요.
- BYOL은 collapse 방지를 위해 projector, predictor 등 복잡한 구성과 대칭 crop이 필수였기 때문에 multi-crop 설계가 어려움
- 두 개의 Global View $x^g_1$, $x^g_2$ : $224×224$
- 원본 이미지의 50% 이상 영역을 포함
- 여러 개의 local View : $96\times96$
- 원본 이미지의 50% 이하 영역만 포함
Student 네트워크는 모든 view를 입력받지만, Teacher 네트워크는 global view만 처리하며, local-to-global 대응이 이루어지도록 유도한다.
예를 들어, 하나의 Global view 이미지를 teacher에 넣었을 때 나온 확률분포 $P_t(x)$에 대해, student 네트워크가 다른 view $x^′$(local crop된 이미지)를 입력받아 출력한 분포 $P_s(x^′)$와 최대한 일치하도록 하는 식이다.
student 네트워크가 작은 크롭(일부 국소 영역)만 보고도 전체 이미지에 대한 전역적 표현을 추측하도록 훈련
즉, student이 입력으로 받은 국소 이미지 조각에 대해, teacher가 넓은 시야로 본 경우와 동일한 표현을 내도록 student을 지도
이러한 multi-crop 방식은 SwAV에서 처음 도입된 기법으로서, 하나의 이미지에서 다양한 크기/영역의 view를 추출함으로써 보다 풍부한 학습 신호를 제공
전체 Loss function는 다음과 같이 정의된다:
\[\min_{\theta_s} \sum_{x \in \{x^{g}_1, x^{g}_2\}} \sum_{\substack{x’ \in V \\ x’ \neq x}} H(P_t(x), P_s(x’))\]이 loss은 teacher 출력 $P_t$를 soft 타겟으로 한 Knowledge distillation 형태로 볼 수 있으며, label이 없는 자율적 학습임에도 teacher network의 “예측”을 정답 삼아 student을 훈련시키는 셈이다.
실제 구현에서는 여러 view 쌍에 대해 이 cross entropy loss을 합산하여 최종 loss로 사용
두 네트워크는 동일한 아키텍처를 공유하지만, 서로 다른 매개변수 집합 $θ_s$와 $θ_t$를 사용하며 위 loss를 최소화하여 매개변수 $θ_s$를 학습한다. 이 multi-crop 방식이 다양한 view 간의 비교 수를 늘리면서도 계산량은 억제해준다.
Contrastive 방식들은 수많은 negative 샘플과도 연산을 진행하기 때문에 연산량이 급증한다.
Teacher Network
기존 Knowledge distillation와 달리, pre-train된 teacher network가 없는 대신, Student의 과거 가중치를 기반으로 teacher를 생성한다.
student과 teacher network는 동일한 ViT를 사용하며, 파라미터 세트만 서로 다른 복제 모델이다.
처음에는 student 네트워크의 가중치를 teacher에 복사하여 시작하고, 이후 teacher 모델의 가중치는 student의 가중치를 지수 이동 평균(EMA)으로 업데이트하는 모멘텀 인코더 방식을 사용한다 :
\[\theta_t \leftarrow \lambda \theta_t + (1-\lambda) \theta_s\]EMA: 과거로 갈수록 지수적으로 작아지는 가중치를 주어 평균을 내는 방법
이동평균(SMA: Simple Moving Average) : 최근 k개 관측값의 산술 평균을 쓰는 방법
- $θ_t$: EMA로 천천히 업데이트되는 teacher
- $θ_s$: 빠르게 변하는 student
- $λ$: 모멘텀/감쇠 계수, cosine 스케줄에 따라 $0.996→1.0$로 증가
Ablation study를 통해 여러 업데이트 방식을 비교한 결과
한 epoch 동안 teacher 고정 : Good
student 가중치를 그대로 복사: 학습 수렴 실패
왜 EMA방식이 좋을까?
student가 학습하면서 출력이 계속 바뀌는데, teacher도 그걸 매번 따라가면 너무 불안정해짐
EMA는 이전 teacher의 출력도 일정 비율로 유지해서, 부드럽고 일관된 target을 제공
결과적으로 Student이 더 일관된 방향으로 학습할 수 있게 되고, collapse도 방지됨
Polyak-Ruppert 평균화처럼 일종의 앙상블 효과도 생김
이렇게 함으로써 teacher network는 student의 과거 지식을 항상 반영하게 되며, 안정적 목표 출력을 제공한다.
중요한 점은 teacher network의 출력에 대해 loss function를 계산하되, 역전파 시에는 teacher에 stop-gradient를 적용하여 오직 student만 학습되도록 한다.
이러한 구조는 별도의 정답 label 없이도 student이 자기 자신(과거의 분신)을 teacher 삼아 학습하는 Self-Distillation 형태로 볼 수 있다.
Network architecture
Student와 Teacher 모두 $g = h \circ f$로 구성된다.
$f$: backbone (ViT 또는 ResNet)
- Transformer 인코더로서 입력 patch들을 인코딩하여 $\texttt{[CLS]}$ token feature를 출력
$h$: Projection head
backbone 출력 $\texttt{[CLS]}$ 를 $K$-차원으로 매핑
$\texttt{[CLS]}$ feature를 받아 최종 representation vector를 산출
3 layer MLP (hidden 2048차원) → L2 정규화 → weight normalization FC layer
이 설계는 SwAV에서 사용된 프로젝트 head와 유사한 구조
BYOL에서는 student 출력에 별도의 predictor MLP를 두어 teacher 출력과 비교하지만, DINO는 이런 예측기를 사용하지 않고 student과 teacher가 똑같은 아키텍처를 갖는다.
또한, ViT 구조상 배치 정규화(BatchNorm)를 쓰지 않는데, DINO에서도 프로젝션 head에 BatchNorm을 전혀 넣지 않아 전체 프레임워크가 BN-free로 동작한다.
이러한 통일된 아키텍처와 BN-free 설계는 ViT 특성을 존중하면서도 간결성을 유지한 DINO만의 구성이다.
Avoiding Collapse
Self-supervised learning에서 가장 큰 난제 중 하나는 모델 붕괴(collapse)이다.
이는 모든 입력에 대해 출력이 상수로 수렴해 버리는 trivial한 해법을 모델이 학습하는 현상으로, 지도 신호가 없을 때 흔히 나타날 수 있다. 기존 SSL 방식은 contrastive loss, clustering, predictor, BN 등으로 collapse 방지
DINO에서는 teacher network의 출력에 간단한 centering과 sharpening 연산만 적용하고도 별도의 복잡한 장치 없이 collapse를 방지할 수 있음을 보인다 .
- Centering
- Teacher 출력 벡터의 각 차원에 대해, 현재 배치에서의 평균값을 빼주는 작업
- 특정 한 차원의 값이 항상 크게 형성되는 것을 막아주며, 한편으로는 모든 차원의 값 분포를 고르게 만들어 출력이 균일 분포에 가까워지는 경향을 유발
- 안정적
- Sharpening
- teacher 출력에 적용하는 softmax의 온도 $τ_t$를 낮게 설정하여 출력 확률분포를 첨예하게 만드는 작업
- 온도를 낮추면 softmax 결과가 가장 큰 값에 더욱 치우쳐서 몇몇 차원은 매우 높은 확률, 나머지는 매우 낮은 확률이 되므로, 출력 분포가 균일해지는 것을 방지하는 효과
- 학습 신호를 명확히
DINO에서는 Centering으로 발생하는 균일화 경향과, Sharpening으로 발생하는 첨예화 경향이 균형을 이루도록 두 작업을 함께 적용한다.
이를 통해 별도 predictor나 복잡한 정규화 없이도 collapse를 억제하는 데 성공
Centering에서 사용되는 평균 벡터(center) c는 매 배치의 teacher 출력 평균을 추적하도록 EMA 업데이트되는데, 이렇게 하면 batch size에 관계없이 안정적으로 동작할 수 있다.
\[c \leftarrow m c + (1 - m) \frac{1}{B} \sum_{i=1}^B g_{\theta_t}(x_i)\]- 여기서 $B$는 배치 사이즈, $m$은 모멘텀 비율.
이 두가지를 적용하면 위에 나왔던 Teacher 확률분포 $P_t$가 나오게 된다.
\[P_t(x)^{(i)} = \frac{\exp\left((g_{\theta_t}(x)^{(i)} - c^{(i)}) / \tau_t\right)}{\sum_{k=1}^K \exp\left((g_{\theta_t}(x)^{(k)} - c^{(k)}) / \tau_t\right)}\]요약하면, DINO는 모멘텀 teacher + Centering & Sharpening으로 Self-supervised learning의 수렴 안정성을 확보하였고, BYOL 등이 사용한 예측기나 복잡한 대비 loss 없이도 좋은 성능을 얻어냈다는 점이 주목될만하다.
왜 DINO에서 “teacher softmax 온도”를 조절하나?
DINO는 teacher 분포 $P_t$를 student 분포 $ P_s$가 따라가도록 Cross-Entropy를 최소화한다.
이때 teacher 분포를 얼마나 ‘자신감 있게’ 만들지가 중요하다.
- 너무 평탄(온도 큼)하면 $P_t$가 거의 균일해져 학습 신호가 약해지고, 극단적으로는 collapse를 부추길 수 있다.
- 적당히 뾰족(온도 작음)하면 teacher가 명확한 타깃을 제시해 student이 의미 있는 구조를 학습하기 쉽다 -> sharpening
DINO는 여기에 centering(평균 제거)까지 곁들여,
- centering으로 특정 차원의 독주(한 로짓만 계속 크게 나오는 붕괴)를 막고,
- teacher softmax의 낮은 온도(Sharpening)로 지나치게 평탄한 분포로 가는 붕괴를 막는다.
두 장치가 서로 반대 방향의 붕괴를 억제하여 균형을 이룬다.
왜 하필 Centering?
Pseudo code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# gs: student network, gt: teacher network
# C: center (K차원 벡터)
# tps, tpt: student / teacher 온도
# l, m: 모멘텀 계수
gt.params = gs.params # 초기엔 Student과 Teacher 동일
for x in loader: # 미니배치 로드
x1, x2 = augment(x), augment(x) # 랜덤 뷰 2개 생성
s1, s2 = gs(x1), gs(x2) # Student 출력
t1, t2 = gt(x1), gt(x2) # Teacher 출력
loss = H(t1, s2)/2 + H(t2, s1)/2 # 교차 손실
loss.backward() # 역전파
# 네트워크 업데이트
update(gs) # SGD
gt.params = l * gt.params + (1-l) * gs.params # Teacher EMA 갱신
C = m * C + (1-m) * mean([t1, t2]) # 센터 업데이트
def H(t, s): # 손실 함수 정의
t = t.detach() # stop gradient
s = softmax(s / tps)
t = softmax((t - C) / tpt) # centering + sharpening
return - (t * log(s)).sum().mean()
요약하면
- 두 가지 변환된 이미지 $x_1$, $x_2$를 student과 teacher에 입력
- teacher 출력은 centering 후 softmax
- student 출력은 softmax 후 teacher 출력과 cross entropy 계산
- teacher에 stop-grad 적용, loss은 student만 업데이트
- teacher는 student의 EMA로 업데이트
이처럼 teacher-student의 Knowledge Distillation 관점에서 본 Self-supervised learning 방법은, label 없이 진행되는 새로운 형태의 Knowledge Distillation라고 볼 수 있으며, 기존 방법들의 장점을 조합하면서도 ViT에 특화된 설계로 간결하면서 강력한 성능을 보여주었다.
Implementation & Evaluation
DINO를 학습시키기 위한 구현 세부 사항과, 실험에서 사용된 평가 프로토콜을 설명한다.
Vision Transformer
본 논문에서는 DeiT(Touvron et al., 2020)의 구현을 따른다. 사용된 다양한 네트워크 구성은 아래 표에 정리되어 있다.
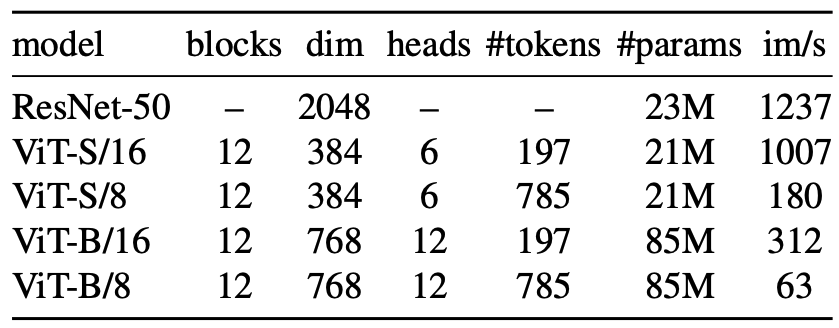
ViT는 해상도 N \times N의 겹치지 않는 이미지 patch grid를 입력으로 받는다.
이 논문에서는 일반적으로 $N=16$ 또는 $N=8$ 을 사용한다.
패치들은 linear layer을 거쳐 Embedding 시퀀스로 변환된다.
learnable한 token 하나를 시퀀스에 추가 : $\texttt{[CLS]}$
- 입력 시퀀스 전체의 정보를 집약
- projection head $h$는 이 token의 출력에 연결된다.
실제로는 어떤 label이나 supervision과 연결되어 있지 않지만, 기존 BERT나 ViT 논문들과 일관성을 위해 같은 이름을 사용
Implementation details
모델은 label이 없는 ImageNet 데이터셋에서 사전학습된다.
- Optimizer : AdamW를 사용하며,
- ViT-S/16 기준으로 batch size 1024를 16개의 GPU에 분산 학습
- learning rate : $ 0.0005 \times \frac{\text{batch size}}{256}$
- warmup 이후에는 learning rate을 cosine 스케줄로 감소
- weight decay : 0.04 → 0.4로 cosine 스케줄을 따름
- Student 온도 $\tau_s$ : 0.
- Teacher 온도 $\tau_t$ : 처음 30 epoch 동안 0.04 → 0.07까지 선형으로 증가(warm-up)
- 데이터 증강 : BYOL 방식(color jittering, Gaussian blur, solarization)을 따릅니다.
또한 multi-crop 증강과 함께, bicubic interpolation을 사용해 position embedding을 다양한 크기에 맞게 조정한다.
Evaluation protocols.
Self-supervised 학습의 일반적인 평가는 다음 두 가지 방식 중 하나를 사용한다:
- Linear probing : backbone $f$은 고정시킨 채, 위에 1 layer linear classifier를 학습
- Fine-tuning : backbone $f$ 포함 전체 네트워크를 downstream task에 맞게 다시 학습
Linear 평가:
- 학습 : random resize crop + 수평 flip 사용
- 테스트 : 중앙 crop 사용해 정확도 측정
Finetuning 평가:
- pre-train된 가중치로 네트워크 초기화 후 전체 모델을 학습
- 하이퍼파라미터(예: learning rate)에 민감하고, 실험마다 정확도 편차가 큼
그래서 DINO는 추가적으로 다음 방식을 함께 사용한다:
k-NN 기반 nearest neighbor classifier
사전학습된 모델을 freeze하여, downstream task의 train 이미지 feature를 저장
이후 test 이미지의 feature를 저장된 훈련 피처들과 비교하여 가장 가까운 k개의 샘플과 매칭
여러 k 값을 실험한 결과, k=20일 때 성능이 가장 안정적으로 좋았음
이 방식은 하이퍼파라미터 튜닝도 필요 없고, 데이터 증강도 필요 없으며, 한 번만 dataset을 통과하면서도 좋은 성능을 보이며 간편하다.
Main Results
DINO가 기존 self-supervised learning(SSL) 방식들과 비교해 얼마나 성능이 우수한지를 ImageNet 벤치마크 기준으로 평가한다.
Metric
- Linear classification (선형 분류기 성능)
- k-NN 분류기 (비지도 방식의 최근접 이웃 분류기)
Comparing with SSL frameworks on ImageNet
Same architecture
기존의 대표적인 SSL 방법들(BYOL, MoCo-v2, SwAV 등)과 동일한 backbone (ResNet-50, ViT-S)으로 비교한다.
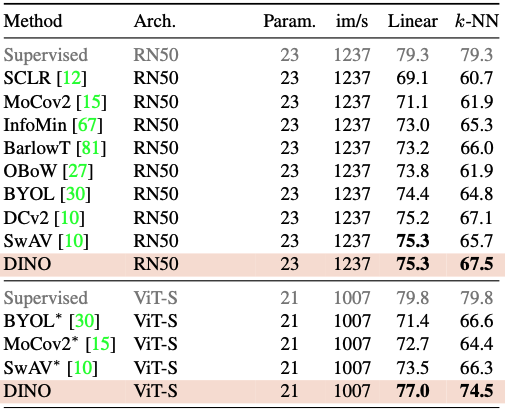
결과 :
- ResNet-50 : SwAV와 동일한 75.3% 선형 정확도, k-NN은 67.5%로 최고
- ViT-S : 기존 방법들 대비 +3.5%p (linear), +7.9%p (k-NN) 차이로 우위
특히 ViT-S에서 linear와 k-NN 성능이 매우 유사 (77.0 vs 74.5)
k-NN 분류기가 label 없이도 거의 supervised 수준의 성능을 낼 만큼 좋은 feature를 학습한 것
Across architectures
이 섹션은 “어떤 방식이 제일 좋은가”보다는, “DINO + ViT 아키텍처를 확장했을 때 어디까지 성능이 좋아지는가”를 보기 위한 것이다.
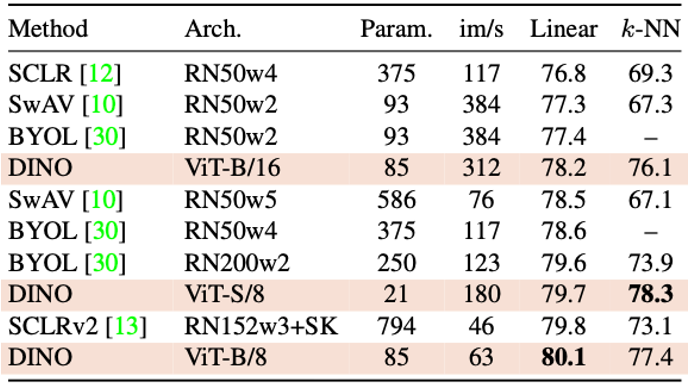
결과 :
ViT-B/8 (8×8 patch 사용) : linear 정확도 80.1%, k-NN 77.4% 달성
기존 SOTA였던 SCLRv2 (supervised에 가까운 크기의 RN152w3+SK) 보다
- 파라미터 수 10배 감소 (794M → 85M)
- 속도 1.4배 향상 (im/s 46 → 63)
- 정확도도 미세하게 더 높음 (79.8% → 80.1%)
Properties of ViT trained with SSL
우리는 DINO feature의 특성을 nearest neighbor search을 통해 평가하며, 물체의 위치 정보와 downstream task로의 이전 가능성을 유지한다.
Nearest neighbor retrieval with DINO ViT
Image Retrieval (이미지 검색)
- 데이터셋:
- Oxford와 Paris image retrieval datasets
- Medium(M), Hard(H) 난이도에서 Mean Average Precision(mAP) 측정
- 비교 대상:
- DINO로 학습된 ViT
- Supervised ImageNet 학습 ViT
k-NN 기반 검색: 학습된 feature를 freeze하고 k-NN으로 검색
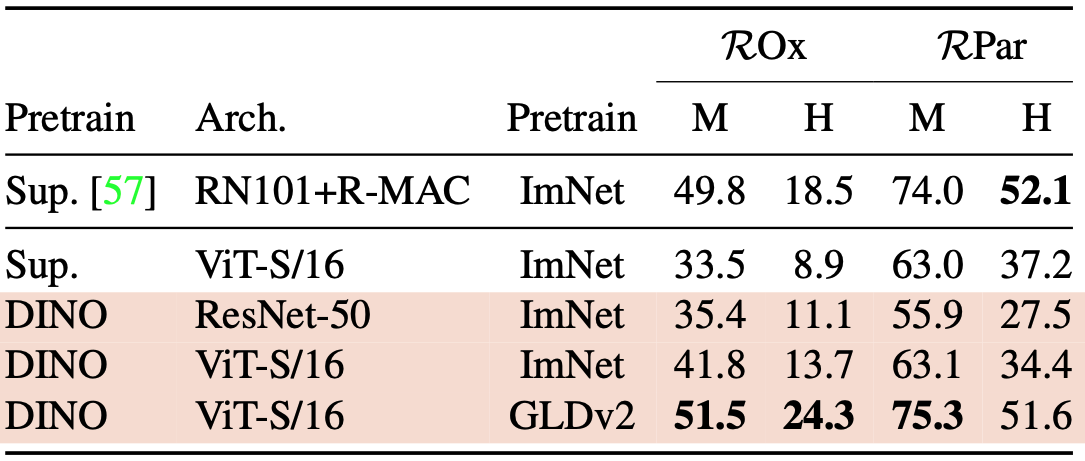
DINO로 학습된 ViT는 라벨이 있는 ImageNet 학습보다도 더 뛰어난 retrieval 성능을 보인다.
이는 self-supervised 학습만으로도 강력한 시멘틱 표현을 학습할 수 있음을 보여준다.
Copy Detection (복제 이미지 탐지)
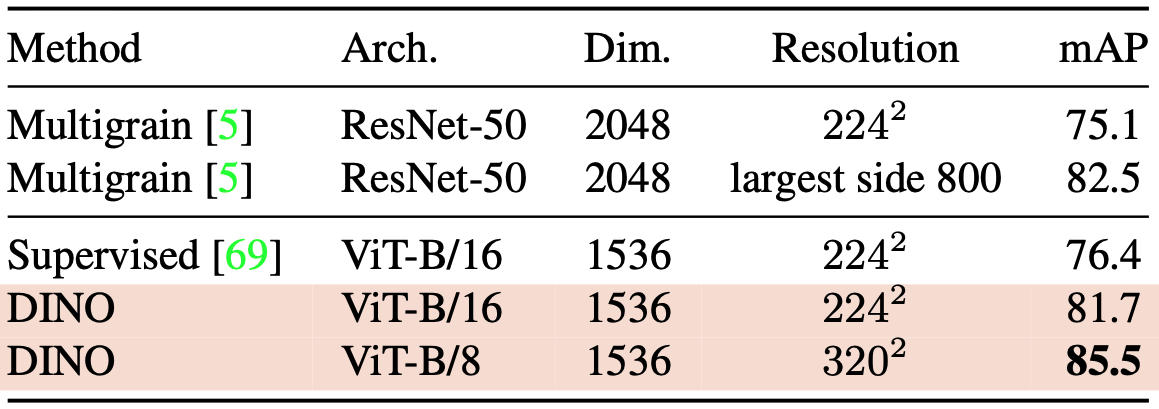
- 사용 데이터셋 : Copydays
- 복제 이미지 (블러, 인쇄/스캔 등 변형된 이미지)를 탐지하는 벤치마크
- YFCC100M 데이터셋에서 랜덤으로 선택된 10k 개의 방해 이미지(distractor images)를 추가
Pre-train된 네트워크에서 얻은 features을 사용하여 cosine similarity를 통해 직접 copy detection를 수행한다.
DINO-ViT-B는 GeM pooling + $\texttt{[CLS]}$ token으로 1536차원 feature 생성한다.
Whitening
- YFCC100M 데이터셋에서 20K개의 feature를 수집해 whitening matrix 학습
- 이후 test 이미지 feature에 whitening 적용하여 cosine similarity 기반 탐색 수행
Whitening은 주어진 벡터 데이터 x를 평균은 0, 공분산 행렬은 단위 행렬이 되도록 만드는 과정
$x_{\text{whitened}} = W (x - \mu)$
사용 이유
- 특성 decorrelation : 서로 상관관계가 있던 feature들을 분리하여 학습 안정화
- 동일 스케일 정규화 : 각 차원의 분산을 1로 맞춰 optimization 안정화
- 성능 향상 : 특히 k-NN, retrieval, copy detection 등에서 거리 기반 비교 성능 개선
Discovering the semantic layout of scenes
Self-attention map에는 이미지의 segmentation 정보가 포함되어 있다.
이 연구에서는 이 특성을 표준 벤치마크에서 측정하는 동시에, 이러한 attention map에서 생성된 mask의 품질을 직접 평가하여 측정한다.
Video instance segmentation
DAVIS-2017 비디오 인스턴스 segmentation 벤치마크에서 출력 patch token을 평가한다.
우리는 Jabri 등 의 실험 프로토콜을 따르며, 연속된 프레임 간의 가장 가까운 이웃을 사용하여 장면을 segmentation한다.
video instance segmentation 작업에서 사전학습된 모델의 feature를 그대로 사용하여, 프레임 간의 최근접 이웃(nearest neighbor) 기반 매칭만으로 장면을 분할하는 방식.
다시 말해, fine-tuning 없이 사전학습된 feature만으로 dense task를 수행하는 평가 방식입니다.
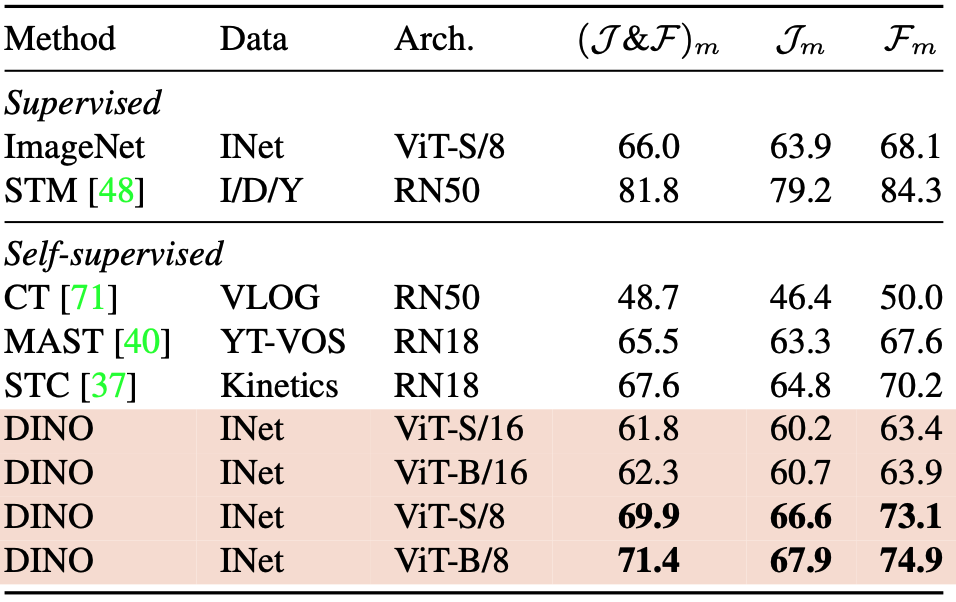
네트워크가 미세 조정되지 않았기 때문에 모델의 출력은 일부 공간 정보를 유지했을 것이다.
마지막으로, 이 밀도 있는 인식 작업에서 작은 패치(“/8”)를 사용한 변형은 훨씬 더 좋은 성능을 보인다$(+9.1%\; ()$ $\mathcal{J}$ & $\mathcal{F}$$)_m$ for ViT-B).
Probing the self-attention map.

서로 다른 head들이 이미지 내 서로 다른 semantic regions을 attention 할 수 있음을 보여준다.
이는 가려져 있는 경우(예: 세 번째 행의 덤불)나 크기가 작은 경우(예: 두 번째 행의 깃발)에도 마찬가지다.
이 시각화는 480p의 이미지를 기반으로 하며, ViT-S/8 모델의 경우 총 3601개의 토큰 시퀀스가 생성된다.
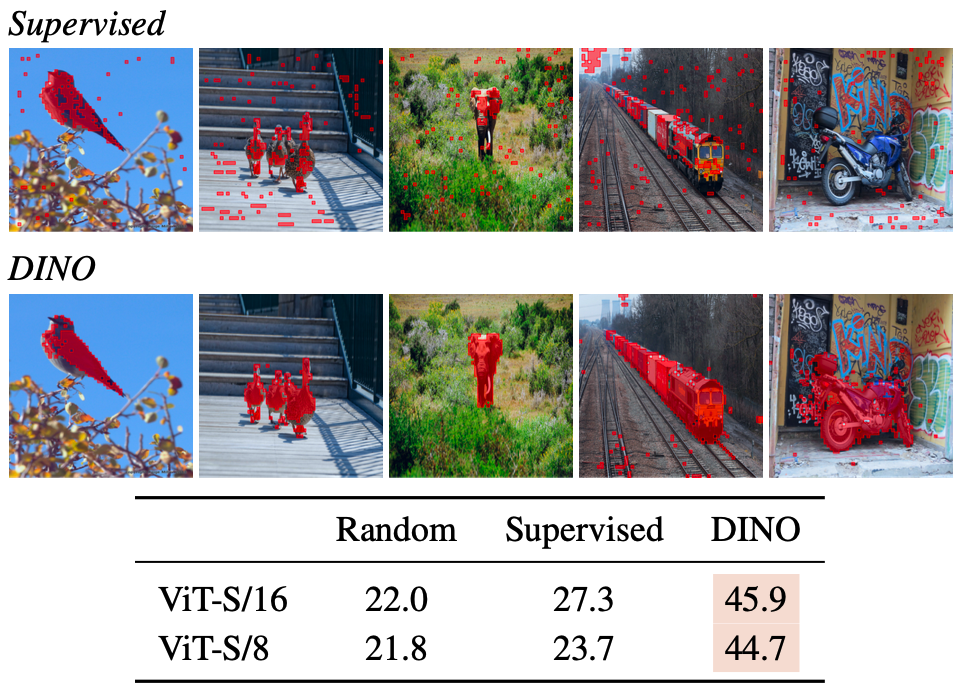
또한 위 이미지에서는 supervised learning된 ViT는 배경이 복잡할 때 오브젝트에 잘 주의를 기울이지 못한다는 것을 정성적 및 정량적 관점 모두에서 보여준다.
Self-attention map을 mask로 변환하여, 해당 맵의 상위 60% mass을 유지하는 방식으로 mask를 만들고, 이를 정답 mask와 비교해 Jaccard 유사도를 측정한다.
여기서 self-attention map은 마스크 생성을 위해 직접 최적화된 것이 아님에도 불구하고, supervised 모델과 DINO 사이에는 Jaccard 유사도 측면에서 명확한 차이가 존재한다.
Transfer learning on downstream tasks
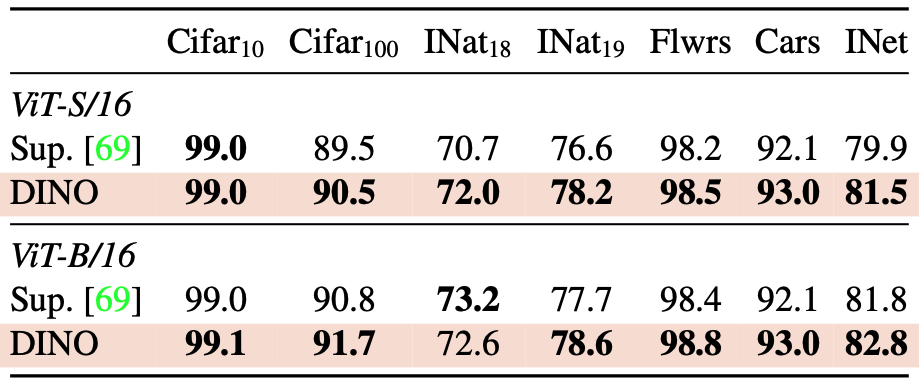
DINO로 사전 훈련된 feature를 다양한 downstream task에서 평가한다.
- 비교군 : ImageNet 에서 supervised learning으로 훈련된 동일한 아키텍처의 feature
- Transfer learning 대상 데이터셋
- CIFAR-10 / CIFAR-100
- iNaturalist (2018 / 2019)
- Flowers, Cars
- ImageNet
- Fine-tuning 방식
- ImageNet 으로 pretrain한 가중치를 초기값으로 사용
- 전체 ViT 모델을 end-to-end로 학습
ViT 아키텍처에서 self-supervised learning을 통한 사전 훈련은 supervised learning으로 훈련된 feature보다 더 잘 전이된다.
과거 컨볼루션 네트워크에 대한 관찰 결과와 일치
자기지도학습으로 학습된 feature representation이 더 일반적이고 유용하다는 사실은 이미 CNN 구조에서도 잘 알려져 있었음
Ablation Study
논문 후반부에서는 DINO의 성능에 기여하는 다양한 설계 요소들을 하나씩 제거하거나 변형하여 그 영향을 분석하였다.
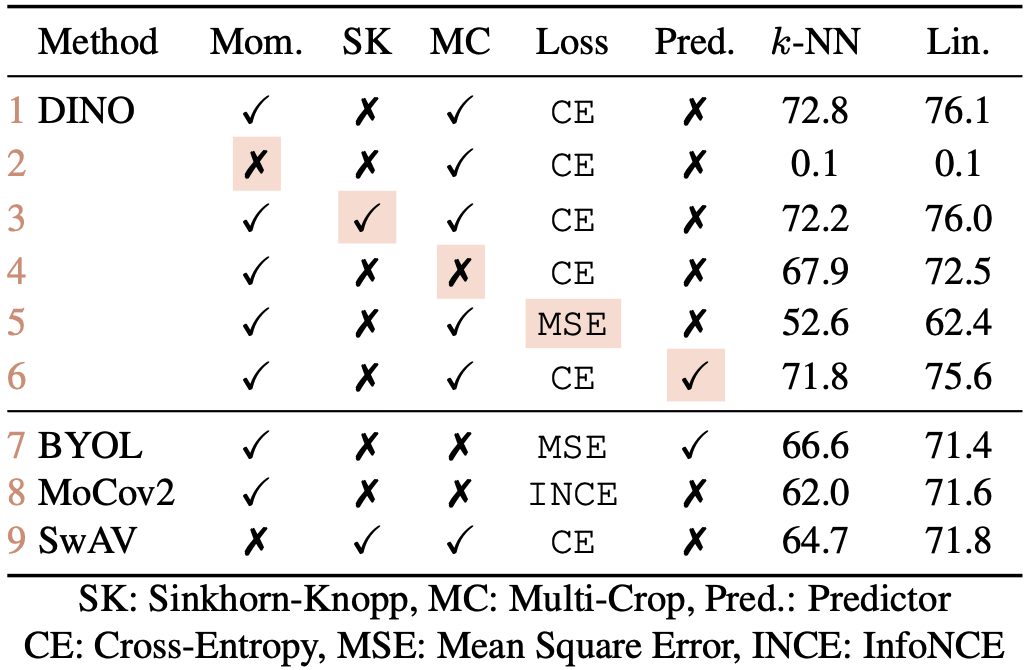
모멘텀 teacher (Momentum Encoder) : 2, 3번 행
매번 student 자체를 teacher로 삼는 구조(모멘텀 계수 $\lambda = 0$)로 실험해보면 모델이 제대로 학습되지 못하고 붕괴를 일으켜, 성능이 크게 저하된다. - 2번 행
이 경우 성능을 겨우 높이기 위해 Sinkhorn-Knopp 클러스터링 등의 고급 기법을 도입해야함
모멘텀 teacher를 사용하면 Sinkhorn-Knopp 없이도 안정적 훈련이 가능 - 3번 행
행 3과 9를 비교하면, 모멘텀 인코더가 성능에 중대한 영향을 미치는 것을 확인 가능
결국 EMA 기반의 teacher가 knowledge distillation 과정에 안정성을 부여하고 표현 품질도 향상시키는 데 필수적임이 확인되었다.
Multi-crop, Cross entropy loss, Predictor : 4, 5, 6 번:
Multi-crop 전략은 DINO에서 가장 큰 성능 향상 요인 중 하나로 지목되었다.
- 행 4, 5를 보면, DINO에서 Multi-Crop 학습과 Cross-Entropy loss는 좋은 feature를 얻기 위해 필수적인 요소
특히 DINO와 MoCo-v2 같이 contrastive한 요소가 있는 프레임워크는 multi-crop의 수혜가 크다.
MoCo-v2 : Query-Positive-Negative 구조를 유지하며 학습
DINO : 명시적으로 negative를 사용하지 않음
하지만, teacher-student 간 확률 분포를 맞추는 과정이 contrastive하게 작용
반면 BYOL의 경우 multi-crop을 단순 적용하면 오히려 학습이 불안정해져 별도의 조정이 필요하다고 보고되었는데, 이는 multi-crop의 효과가 프레임워크별로 다르게 나타나며 만능이 아님을 시사한다.
전체적으로 볼 때, DINO에서 local-global view를 병행하는 multi-crop 훈련이 feature 품질 향상에 큰 기여를 하며, 모멘텀 teacher와 함께 우수한 k-NN 성능을 만들어낸 핵심 요소임을 알 수 있다.
또한,
- student에 predictor를 추가해도 큰 영향은 없다 (6행과 1행 비교)
- BYOL에서는 predictor가 collapse를 방지하는 데 필수적
- BYOL에서 예측기 MLP는 student이 단순 모방만 하지 않고 자체적 feature space을 형성하도록 돕는 장치
DINO는 추가 예측기 없이 centering, sharpening만으로도 잘 작동한다는 점에서 BYOL 대비 구조적 단순성을 가진다는 것을 알 수 있다.
Patch Size
기본 ViT는 16×16 픽셀 patch를 사용하지만, 8×8 혹은 5×5 등 더 작은 patch로 설정하면 어떻게 될지 실험한 결과 patch 크기를 작게 할수록 성능이 눈에 띄게 향상되었다.
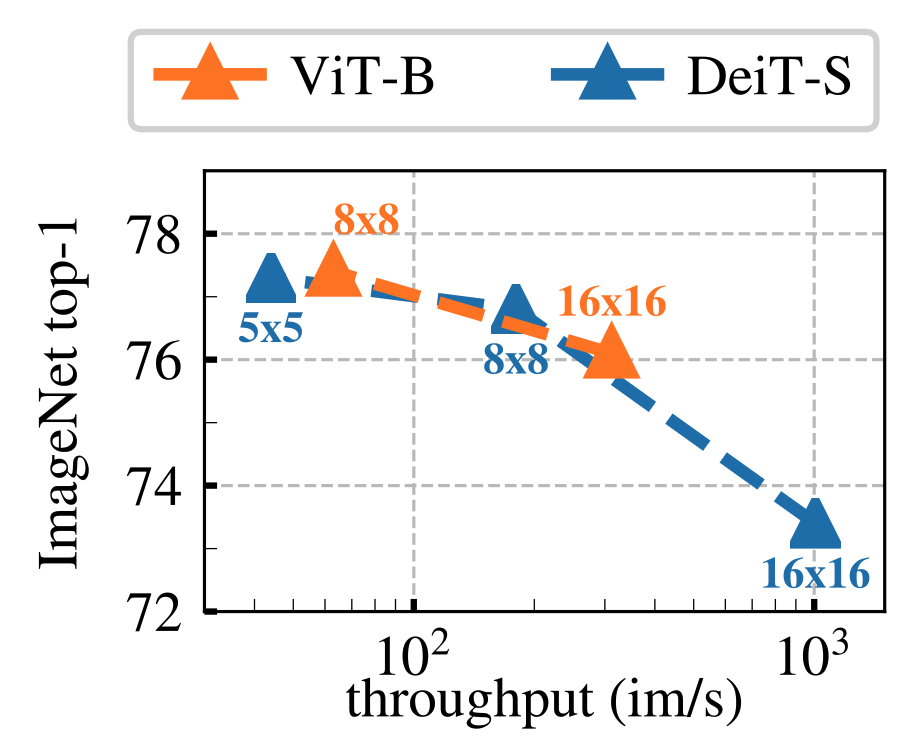
예를 들어 ViT-S에서 /16, /8, /5 patch로 학습한 경우 patch가 작아질수록 k-NN 및 선형 정확도가 대폭 상승했고, 동일 파라미터로 성능을 높이는 효과를 얻었다.
특히 ViT-B/16 대비 ViT-B/8은 파라미터 수 변화 없이도 ImageNet 선형 평가를 78.2% → 80.1%로 끌어올려 주목받았다.
작은 patch로 세분화할수록 이미지의 미세한 디테일까지 학습에 활용되기 때문으로 해석
다만 patch 수가 많아지면 self-attention 연산량이 늘어나 처리 속도가 감소한다.
patch 크기는 성능과 효율 사이의 trade-off 관계이며, 사용 가능 자원에 맞춰 적절히 선택해야 한다.
Teacher Network
모멘텀 teacher 외에도, 이전 student 인스턴스로부터 teacher를 구성하는 다양한 전략을 비교한다.
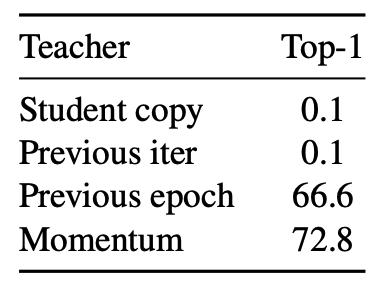
- Student copy : 현재 student의 복사본을 teacher
- 수렴하지 않음 (정규화 필요)
- Previous iter : 직전 iteration의 student 네트워크를 teacher로 사용
- 수렴하지 않음 (정규화 필요)
- Previous epoch : 이전 epoch의 student 네트워크를 teacher로 사용
- 기존 프레임워크와 경쟁력 있는 k-NN 성능을 보이지만, 여전히 teacher에 대한 대안 접근법을 탐색할 여지가 있음
Analyzing the training dynamic
왜 DINO에서의 모멘텀 기반 teacher가 효과적인지를 학습 동역학(dynamic) 관점에서 설명한다.
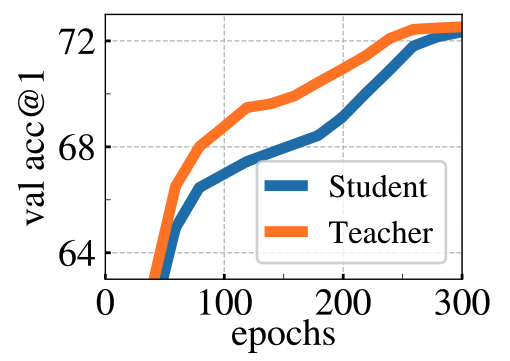
모멘텀 teacher는 학습 내내 항상 student보다 성능이 좋다
DINO에서는 teacher 모델이 student의 과거 파라미터를 EMA 방식으로 누적 반영해서 만들어지는데, 이 모델이 항상 현재의 student보다 성능이 더 좋게 나타난다는 것이 관찰됨.
이 현상은 단순히 ViT뿐 아니라 ResNet-50을 사용할 때도 동일하게 관찰됨.
다른 프레임워크에서는 이런 현상이 없음
예를 들어, MoCo나 BYOL 등도 모멘텀 기반 teacher를 쓰지만, 이와 같이 teacher가 항상 student보다 성능이 좋은 현상은 보고된 적이 없다.
또는 이전 epoch의 student를 teacher로 쓴 경우에도 이런 현상은 관찰되지 않음.
왜? → Polyak-Ruppert 평균화로 해석할 수 있다.
Polyak-Ruppert Averaging이란?
원래는 SGD 기반 학습에서, 모델이 수렴하는 과정에서 최종 파라미터 하나만 쓰지 않고,
중간 파라미터들을 평균내어 더 안정적이고 일반화 성능 좋은 결과를 얻는 기법.
일반적으로 학습 종료 시점에 여러 모델을 앙상블한 것과 비슷한 효과를 가짐.
DINO에서는 이를 학습 중 실시간으로 수행한다.
DINO의 모멘텀 teacher는 EMA을 계속해서 수행하므로, 일종의 실시간 Polyak-Ruppert 평균화 모델이 된다.
따라서 이 teacher는 항상 더 general한 성능을 가진 모델로 유지되고, 그런 더 나은 teacher로부터 student가 학습하기 때문에 학습의 안정성 및 성능이 향상됨.
DINO의 모멘텀 teacher와 Polyak-Ruppert Averaging(PRA)
Polyak-Ruppert Averaging(PRA)란?
- 기존의 모델 파라미터들을 일정 비율로 평균내는 방식
- 가장 유명한 형식은 SGD에서 다음과 같은 형태로 나타난다
→ 이 평균된 모델은 개별 $\theta_t$들보다 더 일반화 성능이 좋고, 진동이 줄어들고, 안정적
DINO의 Momentum Teacher = EMA(PRA의 변형)
DINO는 다음과 같은 식으로 teacher 파라미터 $\theta_t$를 업데이트:
\[\theta_t \leftarrow \lambda \theta_t + (1 - \lambda) \theta_s\]- 즉, teacher는 student 파라미터의 이동 평균
- $\lambda$가 0.996처럼 크면 과거의 정보가 오래 유지 → 일종의 지수 가중 평균 (Exponential Moving Average)
그런데 왜 EMA된 teacher가 현재 student보다 성능이 좋을까?
평균이기 때문에 진동이 줄고, 더 안정적임
student는 학습 초기에 진동이 심함
반면 teacher는 과거 여러 student들의 누적 결과이기 때문에 진동이 적고, 부드러운 방향으로 수렴
이로 인해 성능이 불안정한 student보다 더 일반화된 표현을 가짐
과거 student가 “성능이 낮다”는 건 절대적이지 않음
개별 시점의 student가 성능이 낮아도, 전체적인 평균은 노이즈를 제거하고 본질적인 구조를 더 잘 담을 수 있음.
특히 representation learning에서는 단일 스냅샷보다는 누적된 통계가 더 안정적 표현을 만드는 경향
실제로도 PRA는 최종 성능을 높이는 데 자주 쓰임
- 예: NLP의 SWAD (Stochastic Weight Averaging), EMA on model weights, Mean Teacher, 모두 이런 averaging을 사용해 성능이 상승됨이 실증됨.
Avoiding collapse
collapse를 방지하기 위한 Centering과 Target Sharpening의 보완적 역할을 분석한다.
모델 붕괴에는 두 가지 형태가 존재한다:
- 출력이 모든 차원에서 균등하게 나타나는 경우 (Uniform collapse)
- Sharpening : 출력을 날카롭게(선명하게) 만들어 uniform한 출력을 방지
- 하나의 차원이 출력에서 지배적으로 되는 경우 (Peaked collapse)
- Centering : 하나의 차원이 지배적인 현상을 방지
이 두 기법의 보완성은 아래의 크로스 엔트로피 분해 수식을 통해 분석할 수 있다:
\[H(P_t, P_s) = h(P_t) + D_{KL}(P_t \| P_s)\]- $H(P_t, P_s):$ teacher와 student의 cross-entropy loss
- $h(P_t):$ teacher 출력의 엔트로피
- $D_{KL}(P_t | P_s):$ teacher와 student 출력 분포 간의 KL divergence
수식 분해
두 확률분포 $P_t$, $P_s$ (예: teacher, student)의 cross entropy는 다음과 같이 정의된다.
\[H(P_t, P_s) = - \sum_{i=1}^K P_t(i) \log P_s(i)\]Student가 얼마나 teacher를 잘 따라가고 있는지에 대한 KL divergence는 다음과 같이 정의된다:
\[\begin{align} D_{KL}(P_t \| P_s) &= \sum_{i=1}^K P_t(i) \log \frac{P_t(i)}{P_s(i)} \\ &= \sum_{i=1}^K P_t(i) \log P_t(i) - \sum_{i=1}^K P_t(i) \log P_s(i) \\ &= - h(P_t) + H(P_t, P_s) \end{align}\]$h(P_t) = -\sum_i P_t(i) \log P_t(i)$는 teacher 분포의 엔트로피이기 때문에 가능한 전개이다.
이를 통해
- 엔트로피가 너무 낮으면 → teacher가 collapse 상태
- KL이 0에 수렴하면 → student가 항상 같은 출력을 냄 → collapse
Sharpening : teacher의 엔트로피 $h(P_t)$ 를 낮춤
teacher의 출력이 flat하면 $h(P_t)$가 크고,
sharpening (softmax 온도 $\tau_t \downarrow$)을 하면,
→ teacher의 분포가 뾰족해짐 (특정 클래스에 확률 몰빵) → $h(P_t) \downarrow$ → student가 구체적인 목표 분포를 따라가게 됨
Centering : → teacher 출력의 평균을 조절해 특정 클래스 하나가 항상 높은 확률을 갖는 dominant collapse 방지
- 분포가 너무 뾰족하게 고정되지 않도록 유도
- 즉, 엔트로피를 인위적으로 유지
만약 KL 값이 0이 되면, 이는 teacher와 student가 항상 같은 상수 출력을 낸다는 뜻이고, 이는 곧 collapse 발생을 의미한다.
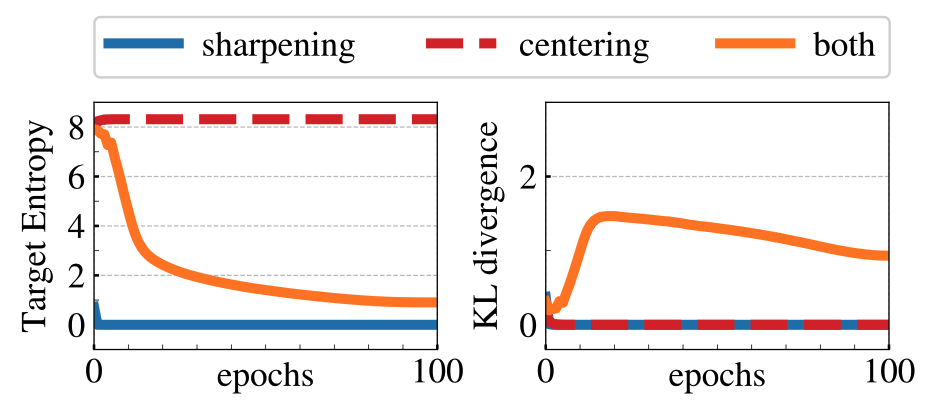
위 그래프를 보자.
Centering 없음 → peaked collapse
- 하나의 차원에만 확률 집중 : 엔트로피 $h \to 0$
- KL은 초반에 조금 있다가 0으로 수렴 : collapse
Sharpening 없음 → flat collapse
- 모든 차원에 같은 확률 → 엔트로피 $h \to \log K$
- 역시 KL은 0으로 수렴 → collapse
Both → 균형 잡힌 분포 유지
- 엔트로피도 안정, KL도 일정하게 유지됨 → collapse 없이 학습 유지
Conclusion
Self-supervised learning된 ViT의 emergent 특성으로서, 이 논문은 다음 두 가지를 부각시켰다.
attention을 통한 자율적 객체 분할 능력
뛰어난 최근접 이웃 분류 성능
이러한 특성들은 추후 다양한 응용 분야에서 활용 가치가 높을 것으로 기대된다.
예를 들어,
k-NN 분류에서 입증된 우수한 feature 품질은 곧 이미지 검색/중복 탐지와 같이 feature 간 유사도 매칭이 중요한 작업에 직결되어, label 없이 사전학습한 ViT feature으로도 높은 성능의 검색 시스템을 구축할 수 있음을 시사한다.
Attention map에 내포된 scene 구성 정보는 weakly supervised 혹은 half-supervised segmentation 등에서 유용하게 쓰일 수 있다.
나아가 인간 관찰자에게 모델의 판단 근거를 설명(Explainability)하는 측면에서도 도움이 될 수 있다 .
무엇보다, 이 연구의 궁극적 함의는 “self-supervised ViT로 비전 분야의 BERT를 실현할 수 있다”는 전망이다.
NLP 분야에서 거대한 자율 pre-training 모델이 언어 이해의 판도를 바꾸었듯이, 대규모 비정제 이미지를 대상으로 DINO 방식의 Self-supervised learning을 적용하면 기존보다 훨씬 일반화되고 강력한 시각 모델을 얻을 수 있으리라는 것이다 .
실제로 저자들은 추후 방대한 비디오/이미지 데이터에 DINO를 적용한 거대 ViT 모델을 연구하여 Vision representation 학습의 한계를 더욱 확장해볼 계획을 밝히고 있다.
이러한 노력은 label에 의존하지 않는 범용 Vision intelligent로 가는 중요한 발걸음이 될 것이며, Self-supervised learning과 Transformer의 시너지가 컴퓨터 비전의 새로운 장을 열 것으로 기대된다.
Limitations
후속 연구들에서는 DINO의 한계점을 다음과 같이 말한다.
학습 안정화 기법에 대한 높은 의존성
- DINO는 collapse(출력이 무의미하게 되는 현상)를 막기 위해 여러 기법에 의존:
- Centering
- Sharpening
- Momentum teacher
이들 기법이 복합적으로 작동하지 않으면 학습이 실패하거나 collapse 발생 가능성이 큼.
- 즉, 구조적으로 불안정한 학습이며, 구현 실수나 하이퍼파라미터 세팅 오류에 민감함.
- DINO는 collapse(출력이 무의미하게 되는 현상)를 막기 위해 여러 기법에 의존:
복잡한 구현 및 높은 자원 요구
- DINO는 다음과 같은 요구사항을 가짐:
- Dual networks (Student & Teacher)
- Multi-crop augmentation (다양한 크기의 이미지 입력)
- EMA(Exponential Moving Average) 유지
- 이로 인해 학습 시:
- 메모리 사용량이 많고
- 병렬 처리 효율이 떨어지며
- 소형 장비에서 학습이 어렵다
- DINO는 다음과 같은 요구사항을 가짐:
학습 속도 느림
ViT 기반 모델은 CNN보다 학습에 훨씬 긴 시간이 걸림.
Multi-crop augmentation도 계산량을 증가시킴.
→ 학습 속도, 전력 소모 측면에서 CNN 기반 SSL 방법들보다 비효율적일 수 있음.
Multi-crop에 과도한 성능 의존
Ablation study에서 확인되듯, multi-crop이 빠지면 성능이 3~4%p 이상 급감함.
하지만 multi-crop은 실시간 응용 시스템에 적용하기 어렵고, GPU 메모리 소모도 크기 때문에, 실용성에 제약이 있음.
Transfer learning에 제한적 실험
- DINO는 linear probing과 일부 downstream task에서 좋은 성능을 보이지만,
- object detection, segmentation, video understanding 등 다양한 task로의 일반화 실험은 부족함.
- 특히 CNN보다 공간 해상도(spatial resolution)가 낮은 ViT 특성상 dense prediction task에는 제한이 있음.
- DINO는 linear probing과 일부 downstream task에서 좋은 성능을 보이지만,
기초적인 contrastive loss 없이 성능 확보
- contrastive loss 없이도 collapse를 방지하지만,
- 그만큼 디자인 복잡성이 증가하고,
- 왜 이런 구조가 잘 작동하는지에 대한 이론적 분석은 부족함.
- (후속 연구인 iBOT, DINOv2 등에서 일부 보완됨)
- contrastive loss 없이도 collapse를 방지하지만,
쓰면서 생긴 Question
BYOL vs DINO
BYOL과 DINO 둘 다 momentum encoder를 사용하지만,
두 프레임워크에서 이 모듈이 동작하는 방식과 학습 목표에는 중요한 차이가 있습니다.
1. 공통점
- 둘 다 teacher 네트워크를 momentum encoder로 구현
- teacher 파라미터 = EMA(teacher 파라미터, student 파라미터)
- 보통 m ≈ 0.996 ~ 0.999 로 매우 느리게 변화
- 목적: teacher를 안정적인 타겟 생성기로 유지하여 collapse 방지
2. 차이점
| 항목 | BYOL | DINO |
|---|---|---|
| 타겟 형태 | feature vector (projector 출력) | 확률 분포 (projection head → softmax) |
| Loss 형태 | L2 loss (cosine similarity 기반), feature alignment | Cross-entropy loss, 확률 분포 일치 |
| Negative 사용 | 없음 | 없음 (확률 기반이지만 contrastive-like 효과 존재) |
| 추가 모듈 | Predictor (student 쪽에만) 추가하여 collapse 방지 | Predictor 없음, 대신 teacher 출력에 centering + sharpening 적용 |
| multi-crop | 기본 설계에는 없음 | 핵심 구성요소 중 하나 (local-global alignment 학습) |
| backbone 주 사용처 | ResNet 계열 | ViT + ResNet 모두 가능, ViT에서 특히 성능 두드러짐 |
3. Momentum encoder의 역할 차이
BYOL
- teacher는 feature space에서 “안정적인 representation target”을 제공
- predictor가 student feature를 변환시켜 teacher feature와 맞추게 함
- momentum encoder는 주로 feature drift를 완화하고 collapse를 막는 안전장치 역할
DINO
teacher는 softmax 확률 분포 형태의 target을 제공
momentum encoder 덕분에 teacher의 확률 분포가 batch noise에 덜 민감해지고,
multi-crop에서 다양한 뷰가 들어와도 일관된 target 유지
centering과 sharpening이 함께 작동해서 teacher entropy를 제어
4. 핵심 차이 요약
BYOL: “feature-level” target alignment + predictor
DINO: “probability distribution-level” target alignment + centering/sharpening
Momentum encoder의 존재 이유는 비슷하지만,
BYOL은 feature 안정화, DINO는 확률 분포 안정화에 특화됨
왜 Multi-crop 방식은 DINO에서만 효과가 있었을까
Multi-crop이 DINO에서 특히 효과가 있었던 건 DINO의 학습 구조와 목표 때문이에요.
다른 SSL 기법에도 crop augmentation은 있었지만, DINO의 teacher–student self-distillation 구조와 결합되면서 시너지가 크게 났습니다.
다양한 해상도의 뷰를 통한 강한 불변성 학습
- Multi-crop은 고해상도 메인 뷰 2개 + 저해상도 서브 뷰 여러 개를 생성
- Teacher: 항상 고해상도 뷰만 입력받음
- Student: 모든 뷰(고해상도+저해상도)를 입력받음
- 이렇게 하면 student가 다양한 크기·시야의 입력에서도 teacher 분포를 맞추는 능력을 학습하게 됨 → 강한 scale & viewpoint 불변성 확보
DINO의 loss 구조가 다양한 crop 간 관계를 활용
DINO의 cross-entropy loss는 teacher view ↔ student view 간 soft target 매칭을 모든 조합에서 계산
Multi-crop을 쓰면 조합 수가 기하급수적으로 늘어남 → 동일 데이터로도 훨씬 많은 contrastive-like 관계가 만들어짐
다른 SSL(예: SimCLR, BYOL)도 augmentation은 쓰지만,
SimCLR: 동일 해상도 view 간 contrastive
BYOL: 2-view 구조만 활용
→ Multi-crop에서 오는 뷰 다양성에 따른 추가 학습 신호가 DINO처럼 극대화되지 않음
Teacher–student 역할 분리 덕분에 작은 crop도 유용
- Contrastive 기반 메서드에선 작은 crop이 anchor/positive로 쓰이면 정보가 너무 적어 학습이 불안정해짐
- DINO는 teacher가 항상 큰 crop을 보므로, 작은 crop(student 입력)이 정보가 적어도 큰 crop의 분포를 따라가면 됨
- 즉, 작은 crop이 “정보 부족” 문제가 아니라 일관성 강화를 위한 훈련 재료로 작용
결과적으로 DINO에서만 큰 성능 향상
- MoCo-v2, SimCLR 같은 방법에선 Multi-crop이 구조적으로 잘 안 맞음
- DINO에선 Multi-crop이 teacher–student 구조와 CE loss 매칭 방식 덕에 데이터 효율을 극대화
- 논문에서도 “Multi-crop benefits frameworks with contrastive-like matching between multiple views, such as DINO” 라고 언급
Multi-crop이 DINO에서만 크게 효과가 난 이유는 (1) teacher–student 구조, (2) cross-entropy 기반 view-to-view 매칭, (3) teacher가 큰 crop만 보도록 설계 덕분에 작은 crop도 안정적으로 불변성 학습에 기여할 수 있었기 때문입니다.