[Paper Review] Diffusion Models Beat GANs on Image Synthesis
[논문 리뷰] Diffusion Models Beat GANs on Image Synthesis
논문 링크 arxiv
Introduction

Image generation 분야에서 SOTA(state of the art)를 달성한 모델은 GAN이다. 하지만 GAN은 fidelity와 diversity의 trade-off에서 fidelity를 선택하여 다양성이 부족하다는 것과 적절한 hyperparameter없이는 훈련이 어렵고 Mode Collapse 현상이 발생한다.
Diversity(다양성)과 Fidelity(충실도)의 trade-off는 생성 모델에서 중요한 개념이다.
Diversity은 모델이 실제 데이터 분포의 다양성을 잘 포착하고, 신규 sample 생성 시 다양한 결과를 내놓는 것을 의미한다.
Fidelity는 생성된 sample이 실제 데이터와 얼마나 유사한지를 의미한다. 높은 충실도를 가진 모델은 실제 데이터와 구별하기 어려운 sample을 생성한다.
GAN은 Fidelity를 선택하여 SOTA를 달성하였다.
Diffusion 모델은 최근 높은 품질의 이미지를 생성하며 다양한 이점을 보이는 모델이다. 하지만, LSUN, ImageNet과 같은 어려운 generative 데이터셋에서는 GAN에 뒤처진다.
논문에서는 Diffusion 모델을 개선, fidelity과 diversity을 절충하여 GAN을 여러 측정 기준과 데이터셋에서 능가하는 모델을 제안한다.
이 논문이 발표되면서 Image generation 분야에 SOTA는 이 논문이 되었다.
Background
이 섹션에서는 Diffusion모델과 DDPM, DDIM에 대해 간단히 요약한 후 넘어가자.
자세한 내용을 알고싶으면 다음 링크를 참고
Diffusion 모델은 noise를 추가하는 foward process를 뒤집어 sampling을 진행한다. sampling은 noise인 $x_T$에서 시작하고 $x_{T-1}$, $x_{T-2}$, … 와 같이 점진적으로 noise를 제거하여 최종 sample인 $x_0$을 생성한다. 대부분의 Diffusion 모델에서는 noise $\epsilon$을 Gaussian nosie로 가정한다.
DDPM
Diffusion 모델은 $x_t$에서 약간 denoising된 $x_{t-1}$을 생성하는 것을 학습하는데, DDPM의 경우 $x_t$의 noise 정도를 예측하는 함수인 $\epsilon_\theta (x_t, t)$로 parameterize한다. $x_t$는 $x_0$와 $t$, noise $\epsilon$를 이용해 다음과 같이 정의할 수 있다.
\[\begin{align} q(x_{t}|x_{0}) &= N(x_{t}; \sqrt{\overline{\alpha}_{t}}x_{0}, (1-\overline{\alpha}_{t})\text{I}) \nonumber \\ &= \sqrt{\overline{\alpha}_t}x_0 + \sqrt{1 - \overline{\alpha}_t}\epsilon, \;\epsilon \sim N(0,\text{I}) \nonumber \end{align}\]Train Objective는 다음과 같이 간단화된 Loss식이 더 성능이 좋게 나오는것을 확인한다.
\[L_{simple}(\theta) = \mathbb{E}_{t, x_0, \epsilon}\left[\left|\left| \epsilon - \epsilon_\theta(\sqrt{\overline{\alpha}_t}x_0 + \sqrt{1 - \overline{\alpha}_t}\epsilon, t)\right|\right|^2 \right]\]DDPM은 $x_t$가 주어졌을 때 $x_{t-1}$의 분포인 $p_\theta(x_{t-1} | x_t)$를 Gaussian인 $N(x_{t-1}; \mu_\theta(x_t, t), \sum_\theta(x_t, t))$로 모델링 할 수 있으며 평균인 $\mu_\theta(x_t, t)$은 함수 $\epsilon_\theta(x_t, t)$로 계산할 수 있음을 보인다.
또한 실제 variational lower bound $L_{vlb}$보다 $L_{simple}$이 더 좋은 결과를 나타낸다.
Improved denoising diffusion probabilistic models
이 논문에서는 DDPM처럼 $\Sigma_\theta(x_t,t)$를 상수로 fix하는 것이 적은 step으로 sampling하는 것이 효과적이지 않으며 $\Sigma_\theta(x_t,t)$를 다음과 같이 output $v$가 inpolation되는 Neural Network로 Parameterization하는 것을 제안한다.
\[\Sigma_\theta(x_t,t) = \text{exp}(v \log \beta_t + (1-v)\log \widetilde{\beta}_t)\]Training Objective 역시$L_{simple} + \lambda L_{vlb}$를 사용하여 $\epsilon_\theta(x_t, t)$와 $\sum_\theta(x_t, t))$을 동시에 Training하는 하이브리드 방식을 제안하여 적은 step으로 sampling해도 품질이 떨어지지 않는다.
이번 논문에서는 이러한 Objective와 Parameterization을 채택하여 Experiment에 사용하였다고 한다.
DDIM
DDIM은 DDPM과 동일한 foward process를 가지지만 reverse process에서 non-Markovian으로 대체하여 deterministic한 mapping을 학습한다. 이를 통해 매우 적은 step으로 sampling할 수 있는 방법을 제안한다.
Architecture Improvements
이 섹션에서는 Diffusion 모델에 적합한 Architecture를 찾는 과정을 수행한다.
DDPM 등 여러 연구를 통해 U-net 구조가 sample의 품질을 향상시킨다는 것을 발견했다.
다른 연구들을 통해 U-net 구조에 대한 약간의 변형이 CIFAR-10과 CelebA-64, ImageNet 128*128에서 높은 품질의 sample을 생성할 수 있음을 발견하였다.
논문에서는 다음과 같은 변형을 사용하였다.
- 모델 크기를 상대적으로 유지하며 깊이와 폭 size를 늘린다.
- attention head의 수를 늘린다.
- 다양한 해상도(32*32, 16*16, 8*8)에서 attention기법을 사용한다.
- BigGAN의 Residual block을 사용하여 Up/Down sampling진행
- Residual connection을 $\frac{1}{\sqrt{2}}$로 rescaling한다.
이 섹션의 모든 비교를 위해 batch size 256의 ImageNet 128×128 데이터셋에서 모델을 train하고 sampling step을 250으로 하여 진행한다.
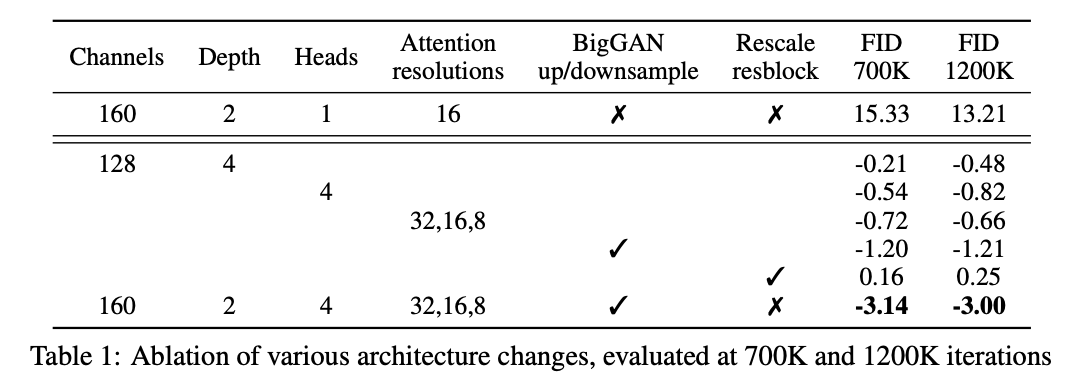
위 표는 700,000와 1,200,000 iter로 평가한 다양한 변형 조건 제거에 따른 결과이다. 모든 조건을 사용하였을 때 성능이 증가함을 보였다.
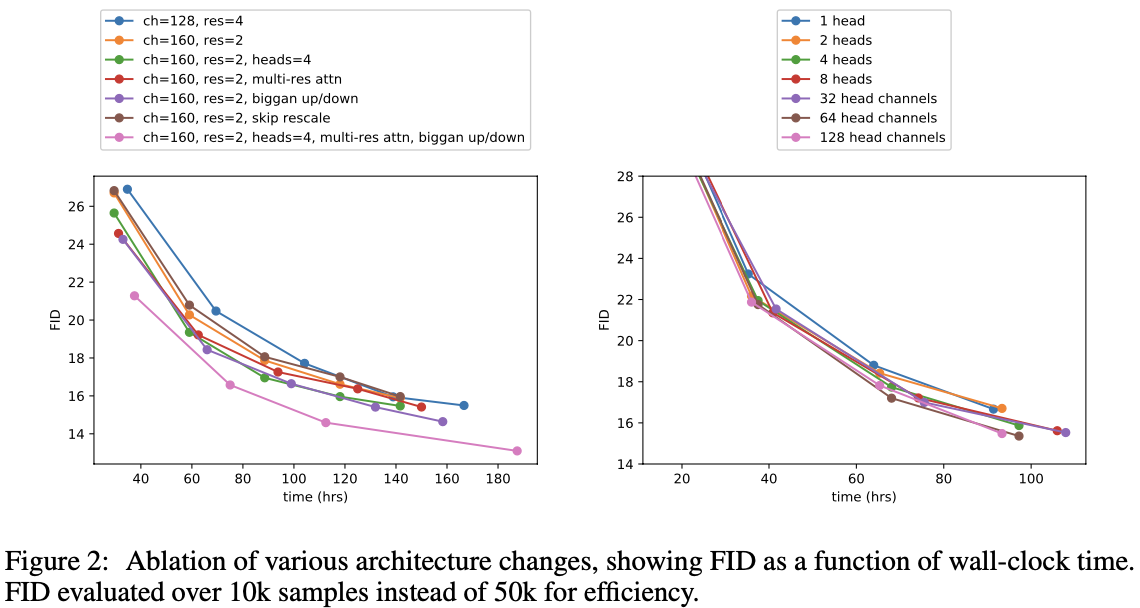
그림 2에서 볼수있듯이 깊이가 증가하면 성능은 증가하지만 train 시간이 늘어나고 더 넓은 모델과 같은 성능을 내기 위해 train 시간이 더 걸리기 때문에 추가 실험에서 이 변경 사항을 사용하지 않는다고 한다.

그림 2와 표 2를 보면 head당 64개의 channel이 wall-clock time에 가장 적합하다는 것을 알 수 있으므로, default값으로 64개의 channel을 사용하였다. 논문에서는 이 method가 최신 Transformer 구조와 더 잘 일치하다고 한다.
Adaptive Group Normalization
논문에서는 AdaIN(adaptive instance norm), FiLM과 유사한 AdaGN(adaptive group normalization) layer를 사용한다. AdaGN은 Group Normalization을 진행한 후, 각 Residual block에 timestep과 class embedding의 정보를 전달한다.
\[\text{AdaGN}(h, y) = y_s \text{GroupNorm}(h) + y_b\]여기서 $h$는 첫 Convolution layer에 따른 Residual block의 중간 activation이며 $y=[y_s, y_b]$는 timestep과 class embedding의 linear projection으로부터 얻는다.

위 표를 보면 AdaGN을 사용함으로써 FID값이 개선된 것을 확인할 수 있다.
최종적으로 실험에 사용한 setting은 다음과 같다.
- Variable width with 2 residual blocks per resolution
- Multiple heads with 64 channels per head
- Attention at 32, 16 and 8 resolutions
- BigGAN residual blocks for up and downsampling
- adaptive group normalization(AdaGN)
Classifier Guidance
GAN의 조건부 생성에는 class label이 사용된다. GAN에서는 Discriminator를 Classifier $p(y|x)$처럼 사용하거나 class-conditional normalization 방법을 사용하여 conditional 생성을 수행한다.
논문에서는 이러한 방식을 채용하여 Classifier $p(y|x)$를 활용하여 Diffusion 모델의 개선을 시도한다. 앞에서 AdaGN을 통해 class embedding 정보를 전달하고 있다. 앞선 연구(1, 2)에서는 Classifier의 gradient를 이용해 pre-train된 Diffusion모델을 조절한다. noise 이미지 $x_t$로 Classifier $p_\phi (y|x_t, t)$를 학습한 후, 기울기 $\triangledown_{x_t} \log p_\phi (y|x_t, t)$를 사용해 어떤 class label $y$을 생성하도록 diffusion sampling process를 유도할 수 있다.
지금부터 Classifier를 사용하여 conditional sampling process를 도출하는 2가지 방법에 대해 살펴본 후, 이러한 Classifier를 사용하여 sample의 품질을 향상시키는 방법을 알아보자.
논문에서는 간결성을 위해 $p_\phi (y|x_t, t)$는 $p_\phi (y|x_t)$로, $\epsilon_\theta(x_t, t)$는 $\epsilon_\theta(x_t)$로 표기한다.
위 표기는 각 timestep $t$에 대한 함수를 나타내며, train할때 모델이 input $t$에 대한 조건부임을 유의해야한다.
Conditional Reverse Noising Process
unconditional reverse process인 $p_\theta(x_t | x_{t+1})$에 label $y$의 condition을 부여하기 위해서는 다음과 같이 각 transition을 sampling 해야한다. ($Z$는 정규화 상수)
\[p_{\theta,\phi}(x_t|x_{t+1}, y) = Zp_\theta(x_t|x_{t+1})p_\phi(y|x_t) \tag{2}\]이러한 분포에서 sampling하는 것은 어렵지만, Sohl-Dickstein et al.은 이 분포가 Gaussian 분포에 근사화된다는 것을 보여준다.
Diffusion 모델이 $x_{t+1}$에서 $x_t$를 예측할 때 Gaussian 분포를 사용한다는 것을 상기하면서 다음 식을 보자.
\[\begin{align} p_\theta(x_t|x_{t+1}) &= \textit{N}(\mu, \Sigma) \tag{3}\\ \log p_\theta(x_t|x_{t+1}) &= -\frac{1}{2}(x_t - \mu)^T \Sigma^{-1}(x_t, - \mu) + C \tag{4} \end{align}\]우리는 $\log p_\phi(y_t|x_{t})$이 $\Sigma_{-1}$보다 낮은 곡률을 가지고 있다고 가정할 수 있으며, 이는 무한한 diffusion step을 가질때 $||\Sigma|| \rightarrow 0$이 되어 reasonable하게 된다. 이러한 경우에 $\log p_\phi(y_t|x_{t})$는 $x_t = \mu$ 근처에서 Taylor 전개를 사용하여 다음과 같이 근사화될 수 있다.
\[\begin{align} \log p_\phi(y_t|x_{t}) &\approx \log p_\phi(y|x_t)\mid_{x_t=\mu} + (x_t - \mu) \bigtriangledown_{x_t} \log p_\phi(y|x_t)\mid_{x_t=\mu} \tag{5} \\ &= (x_t - \mu)g + C_1 \tag{6} \\ \end{align}\]Taylor expansion(테일러 전개)와 Taylor series(테일러 급수)는 같은 뜻이다.
여기서 $g = \bigtriangledown_{x_t} \log p_\phi(y|x_t)\mid_{x_t=\mu}$이며 $C_1$은 상수이다. 이를 통해 다음과 같이 전개할 수 있다.
\[\begin{align} \log (p_\theta(x_t|x_{t+1})p_\phi(y|x_t)) &\approx -\frac{1}{2}(x_t-\mu)^T\Sigma^{-1}(x_t-\mu) + (x_t-\mu)g + C_2 \tag{7}\\ &= -\frac{1}{2}(x_t-\mu-\Sigma g)^T\Sigma^{-1}(x_t-\mu-\Sigma g) + \frac{1}{2}g^T\Sigma g + C_2 \tag{8}\\ &= -\frac{1}{2}(x_t-\mu-\Sigma g)^T\Sigma^{-1}(x_t-\mu-\Sigma g) + C_3 \tag{9} \\ &= \log p(z) + C_4, \;z\sim \textit{N}(\mu + \Sigma g, \Sigma) \tag{10} \end{align}\]마지막 줄에서 $C_4$는 Eq .2의 $Z$처럼 정규화 계수이므로 무시할 수 있다. 따라서 conditional transition operator는 unconditional과 유사하며, 평균이 $\Sigma g$만큼 이동한 Gaussian으로 근사화할 수 있음을 알 수 있다.
이러한 sampling 알고리즘을 요약하여 Algorithm 1로 표현할 수 있다.

여기서 $s$는 gradient에 대한 optional scale 계수이며 이는 추후 Scaling Classifier Gradients에서 자세히 다룬다.
Conditional Sampling for DDIM
위 섹션에서의 유도는 DDPM과 같은 stochastic한 diffusion process에만 유효하며, DDIM과 같이 deterministic한 sampling 방법에는 적용할 수 없다.
이를 위해 논문에서는 Score-based conditioning trick을 사용한다. sample에 추가된 noise를 예측하는 모델인 $\epsilon_\theta(x_t)$가 있는 경우, 이를 사용하여 Score function을 유도할 수 있다.
\[\bigtriangledown_{x_t} \log p_\theta(x_t) = -\frac{1}{\sqrt{1-\overline{\alpha}_t}}\epsilon_\theta(x_t) \tag{11}\]Score-based conditioning trick는 Score-based generative models에서 사용하는 방법으로, conditional generate 문제에 사용된다.
Score-based generative models은 각 데이터 sample의 “score”를 계산하는 function, 즉 score function을 학습한다. 여기서 “score”는 sample이 얼마나 모델이 학습한 데이터 분포에 부합하는지를 나타낸다.
Score-based conditioning trick은 학습한 score function을 특정 조건을 만족하는 sample을 생성하도록 유도하여 특정 condition을 만족하는 sample을 생성하도록 유도하는 trick이다.
위 식을 Score function에 대입하여 $p(x_t)p(y|x)$를 구할수 있다.
\[\begin{align} \bigtriangledown_{x_t}\log (p_\theta(x_t)p_\phi(y|x_t)) &= \bigtriangledown_{x_t} \log p_\theta(x_t) + \bigtriangledown_{x_t}\log p_\phi(y|x_t) \tag{12}\\ &= -\frac{1}{\sqrt{1-\overline{\alpha}_t}}\epsilon_\theta(x_t) + \bigtriangledown_{x_t}\log p_\phi(y|x_t) \tag{13} \end{align}\]마지막으로, joint distribution의 score에 해당하는 새로운 epsilon prediction $\hat{\epsilon}(x_t)$을 정의할 수 있다.
\[\begin{align} \hat{\epsilon}(x_t) := \epsilon_\theta(x_t) - \sqrt{1-\overline{\alpha}_t} \bigtriangledown_{x_t} \log p_\phi(y|x_t) \tag{14} \end{align}\]DDIM에 사용되는 sampling process를 사용하되, $\epsilon_\theta(x_t)$대신 $\hat{\epsilon}_\theta(x_t)$를 사용하면된다.
이러한 sampling 과정은 Algorithm 2에 요약되어있다.

Scaling Classifier Gradients
대규모 generative task에 Classifier guidance를 적용하기 위해 ImageNet을 Classifier에 train한다. Classifier 구조는 8×8 layer에 attention pool이 있는 U-net 모델의 downsampling 하는 부분을 사용하였다. Diffusion 모델과 동일한 noise distribution으로 train하고, overfitting을 방지하기 위해 무작위 crop을 추가하였다. 훈련 후에서는 Algorithm 1에 Eq. 10을 사용하여 Classifier를 sampling process에 적용시켰다.

unconditional ImageNet 모델을 사용할 때, classifier의 gradient를 1보다 큰 계수로 설정해야한다는 것을 발견했다. 1로 하였을 때 classifier는 최종 sample의 class에 대해 50%의 적절한 확률을 할당했지만, 실제 이미지를 확인한 결과 의도한 class와 맞지 않는다는 것을 발견하였다고 한다. 이를 해결하기 위해 gradient를 1보다 크게 하였고, 확률이 거의 100%까지 증가했다고 한다.
위 사진은 Pembroke Welsh corgi라는 class로 생성한 결과이며 왼쪽은 classifier scale가 1, 오른쪽은 10으로 조정한 sample이다.
Classifier gradient의 scaling을 이해하려면 아래 식을 참고해야한다. ($Z$는 상수)
\[s \cdot \bigtriangledown_x \log p(y|x) = \bigtriangledown_x \log \frac{1}{Z}p(y|x)^s\]conditioning process는 $p(y|x)^s$에 비례하는 nomalized된 classifier distribution에 기반을 두고 있다. $s > 1$일때, 이 분포는 $p(y|x)$보다 선명해진다.
Gradient scale이 커질수록 classifier에 기능이 집중되며 diverse가 낮지만 fidelity가 높은 sample을 생성할 수 있다.
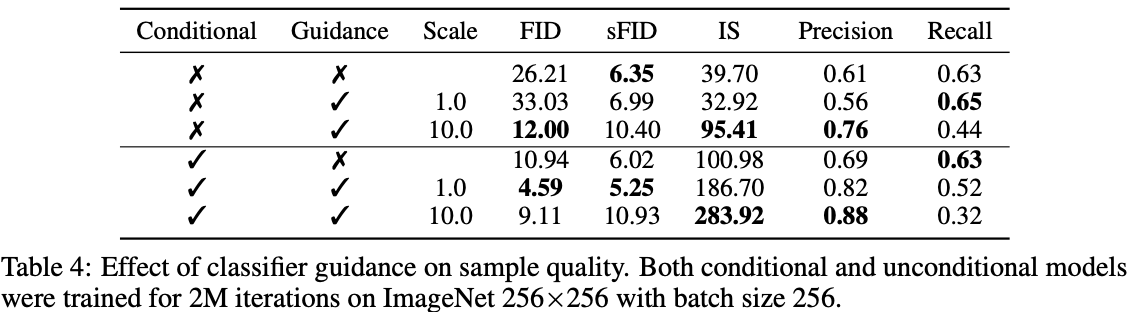
위 표는 classifier guidance를 통해 conditional/unconditional 모델의 sample 품질이 크게 향상됨을 보여주며, conditional model의 sample 품질이 더 좋다는 것을 알 수 있다.
unconditional 모델은 AdaGN으로 class 정보를 전달하지 않은 모델이다.
Result
다음 2가지에 대한 Evaluate를 진행한다.
unconditional 모델 아키텍처를 평가하기 위해 침실, 말, 고양이의 세 가지 LSUN class에 대해 별도의 Diffusion 모델을 train
Classifier Guidance에 대해 평가하기 위해 128×128, 256×256, 512×512 해상도의 ImageNet 데이터셋에서 conditional diffusion 모델을 train