[Paper Review] DiffusionBridge
[논문 리뷰] Diffusion Bridge: Leveraging Diffusion Model to Reduce the Modality Gap Between Text and Vision for Zero-Shot Image Captioning
Diffusion Bridge: Leveraging Diffusion Model to Reduce the Modality Gap Between Text and Vision for Zero-Shot Image Captioning
Jeong Ryong Lee et al,.
CVPR 2025
Background
Modality Gap in Contrastive Embedding Space
대규모 vision-언어 모델은 이미지와 텍스트를 각각 인코딩해 같은 embedding 공간에서 비교하도록 학습된다. 대표적으로 CLIP은 (이미지, 텍스트) pair을 대조학습(contrastive learning)으로 학습해, pair은 가깝게, 비pair은 멀게 만든다.
그런데 “같은 공간”에 놓였다고 해서 두 모달리티(이미지/텍스트) embedding 분포가 완전히 섞이는 것은 아니다. 실제로는 이미지 embedding과 텍스트 embedding이 공간에서 구조적으로 분리되는 현상이 관찰되며, 이를 modality gap이라 부른다. 이 gap은 모델 초기화와 대조학습 최적화가 결합되며 유지될 수 있다는 분석이 있다.
Diffusion Bridge 논문은 이 modality gap이 zero-shot Image captioning에서 특히 치명적이라고 본다. 디코더(언어 모델)가 텍스트 embedding 분포에서 학습되었다면, 추론 시 입력으로 들어오는 이미지 embedding 분포가 다를 때 생성 품질이 흔들리기 때문이다.
Zero-shot Image Captioning with Text-only Training
zero-shot Image captioning(text-only training 기반)은 “(이미지, 캡션) 페어를 학습에 쓰지 않고” 텍스트 데이터만으로 디코더를 학습한 뒤, 추론 시 이미지 embedding을 조건으로 캡션을 생성하는 흐름을 의미한다. Diffusion Bridge는 이 전형을 따른다.
이 계열에서 modality gap을 다루는 대표 전략은 크게 두 가지로 자주 등장한다.
- Noise injection: 텍스트 embedding에 가우시안 노이즈를 더해 디코더가 “조금 다른 분포의 입력”에도 견디게 만드는 방식이다. CapDec 류가 대표적이다.
- Memory-based retrieval/projection: 학습 텍스트 embedding을 메모리 뱅크로 두고, 이미지 embedding을 텍스트 공간으로 사상하면서 관련 텍스트를 검색/투영하는 방식이다. DeCap/MeaCap 류가 대표적이다.
Diffusion Bridge의 문제의식은 “노이즈 주입은 강건성은 올리지만 근본 정렬(alignment)은 아니고, 메모리 기반은 계산/리소스 의존이 크다”는 쪽에 가깝다.
DDPM & DDIM
Diffusion Bridge는 텍스트 embedding 분포를 학습하기 위해 DDPM을 사용한다. DDPM은 데이터를 점점 노이즈로 만드는 정방향(forward) 확산과, 노이즈에서 데이터를 복원하는 역방향(reverse) 과정을 학습한다.
또한 역과정 sampling을 빠르게 하기 위해 DDIM이 자주 쓰이며, 논문도 디코더 학습용 증강 과정에서 DDIM을 사용했다고 명시한다.
Introduction
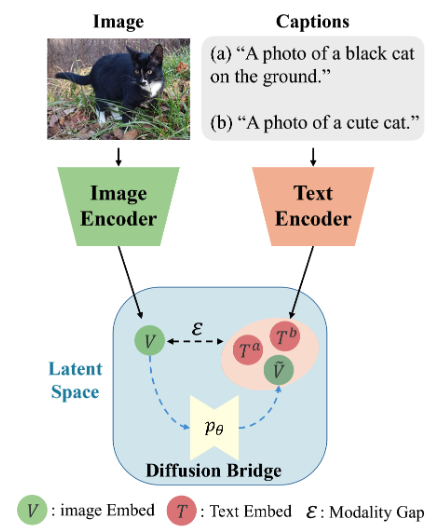
Diffusion Bridge는 CLIP embedding 공간에서 이미지/텍스트가 구조적으로 분리되는 modality gap을 “모달 간 매핑에 존재하는 잡음(noise)”으로 해석하고, 텍스트 embedding만으로 학습한 diffusion 모델을 텍스트 분포의 prior(끌어당기는 힘)로 삼아 추론 시 이미지 embedding을 역확산 과정의 중간 시점에 삽입해 점진적으로 텍스트처럼 정제함으로써 zero-shot 캡셔닝 성능을 높이는 접근을 제안한다.
- Goal
- CLIP 기반 zero-shot 캡셔닝에서 이미지 embedding을 텍스트 embedding 분포로 정렬해 modality gap을 줄이는 것이 목표가 된다.
- Motivations
- 대조학습과 초기화로 인해 이미지/텍스트 embedding이 같은 공간에서도 서로 다른 영역을 점유해 직접 호환이 어렵다고 본다.
- 기존 noise injection은 직접 정렬이 아니고, retrieval/memory 방식은 리소스 의존이 크다고 본다.
- Contributions
- 텍스트 embedding 분포를 DDPM으로 학습하고, 추론에서 이미지 embedding을 역확산 중간 단계에 삽입해 텍스트-라이크 embedding으로 정제하는 diffusion-bridging을 제안한다.
- 디코더가 역확산으로 생기는 미세한 랜덤성/비단사성을 견디도록 diffusion-augmented 텍스트 embedding으로 학습하는 전략을 포함한다.
- MSCOCO/Flickr30K에서 메모리 뱅크 없이 경쟁력 있는 성능과 교차 domain generalization를 보고한다.
Related Work
Late-Guidance Decoding
Late-Guidance는 디코딩 결과를 후반에 수정/가이드해 시각 정보를 반영시키는 계열로 소개된다. Diffusion Bridge는 이 계열이 embedding 공간의 gap을 근본적으로 줄이기보다는 “간접 조정”에 가깝다고 정리한다.
Early-Guidance Decoding
Early-Guidance는 디코딩 초반(또는 입력 embedding 단계)에서 gap을 다루려는 계열로, noise-injected 학습(CapDec 등)과 memory-based projection(DeCap 등)이 대표로 언급된다.
Diffusion Bridge는 자신의 위치를 이 Early-Guidance 범주로 두되, “노이즈로 디코더 강건성을 키우는 것”을 넘어 “이미지 embedding 자체를 텍스트 분포로 직접 정제”하는 데 초점을 둔다.
Keywords-Guidance Decoding
Keywords/Entities 기반 방법은 엔티티를 뽑아 hard prompt로 언어 모델을 제약해 환각(hallucination)을 줄이려는 계열이다. ViECap/MeaCap 같은 접근이 이 범주로 언급된다.
Diffusion Bridge는 이 계열이 “문장 생성 단계에서의 제약”에 강점이 있다고 보면서도, 자기 방법은 embedding 레벨 정렬이라 서로 보완 가능하다고 본다.
Method
Background on Denoising Diffusion Probabilistic Models
Diffusion Bridge는 DDPM의 표준 수식을 텍스트 embedding 벡터에 그대로 적용한다. 다음 수식들은 논문에 제시된 DDPM의 정의이다.
\[q(z_t \mid z_{t-1}) := \mathcal{N}\!\left(z_t;\sqrt{1-\beta_t}\,z_{t-1},\beta_t I\right) \tag{1}\] \[q(z_t \mid z_0)=\mathcal{N}\!\left(z_t;\sqrt{\bar\alpha_t}z_0,(1-\bar\alpha_t)I\right) \tag{2}\] \[p_\theta(z_{t-1}\mid z_t):=\mathcal{N}\!\left(z_{t-1};\mu_\theta(z_t,t),\sigma_t^2 I\right) \tag{3}\] \[\mu_\theta(z_t,t)=\frac{1}{\sqrt{\alpha_t}}\left(z_t-\frac{\beta_t}{\sqrt{1-\bar\alpha_t}}\epsilon_\theta(z_t,t)\right) \tag{4}\] \[L_{\text{DDPM}}(\theta)=\mathbb{E}_{t,z_0,\epsilon}\left[\left\|\epsilon-\epsilon_\theta\!\left(\sqrt{\bar\alpha_t}z_0+\sqrt{1-\bar\alpha_t}\epsilon,\,t\right)\right\|^2\right] \tag{5}\]- $z_0$ : 원본 데이터 벡터(본 논문에서는 “전처리된 텍스트 embedding”)
- $z_t$ : $t$번째 확산 단계의 벡터
- $q(\cdot)$ : 정방향(노이즈 추가) 분포
- $p_\theta(\cdot)$ : 역방향(노이즈 제거) 분포이며 파라미터 $\theta$를 학습
- $\beta_t$ : $t$에서의 노이즈 분산 스케줄
- $\alpha_t := 1-\beta_t$ : (논문에서 사용되는) 보조 변수 정의
- $\bar\alpha_t := \prod_{s=1}^{t}\alpha_s$ : 누적 곱으로 정의되는 스케줄
- $\epsilon_\theta(z_t,t)$ : 모델이 예측하는 노이즈
- $\mu_\theta(z_t,t)$ : 역과정 가우시안의 평균, $\epsilon_\theta$로 계산
논문은 마지막 단계에서 $z_T$가 순수 가우시안과 거의 구분되지 않는 상태가 되며 $z_T \sim \mathcal{N}(0,I)$로 기술된다고 설명한다.
이 DDPM 수식 자체는 표준이지만, Diffusion Bridge의 핵심은 “이 과정을 이미지 픽셀이 아니라 텍스트 embedding 벡터 분포에 대해 학습한다”는 점에 있다.
Diffusion Training with Text Embeddings

이 절의 핵심은 “텍스트 embedding만으로 diffusion 모델을 학습해 텍스트 embedding 분포의 구조를 학습한다”는 설계이다.
논문은 CLIP 텍스트 embedding $e^{text}$를 전처리해 $z_0$를 만든다. 최종 전처리식은 다음과 같다.
\[z_0 = C \times \frac{e^{text}-\bar e^{text}}{\|e^{text}-\bar e^{text}\|_2} \tag{6}\]- $e^{text}$ : CLIP 텍스트 인코더가 만든 텍스트 embedding
- $\bar e^{text}$ : 학습 텍스트 embedding들의 평균 벡터(centering용)
- $C$ : 스케일링 상수 (논문은 실험에서 $C=5$를 사용)
왜 L2 정규화와 mean-centering을 하는가
- 텍스트 embedding의 magnitude를 통제하기 위해 L2 정규화를 전제로 둔다
- mean-centering으로 분포를 정렬된 공간에서 다루기 좋게 만든다
- 그리고 L2 정규화된 embedding은 평균 스케일이 작아 DDPM에서 signal/noise 구분이 흐려질 수 있어 $C$로 스케일 증가
Modality gap을 “정렬 잡음(alignment noise)”으로 보는 관점
Diffusion Bridge는 C3의 분석을 계승해, CLIP에서 vision-텍스트 간 차이를 “가우시안 잡음”으로 근사할 수 있다고 서술한다.
\[z^{vision} = z^{text} + \epsilon,\quad \epsilon \sim \mathcal{N}(0,\sigma^2 I)\]
- $z^{text}$ : 텍스트 embedding(또는 텍스트 embedding에서 유도된 representation)
- $z^{vision}$ : vision embedding(또는 vision embedding에서 유도된 representation)
- $\epsilon$ : 모달리티 간 gap를 noise
이 관점에서 diffusion의 역확산은 “잡음이 섞인 벡터를 텍스트 분포의 고밀도 영역으로 되돌리는 과정”처럼 해석된다.
텍스트 embedding 분포의 score function을 $\nabla_{z^{text}}\log p(z^{text})$로 표기
Decoder Training
이 절에서 논문은 디코더를 “텍스트 embedding을 prefix 입력으로 받아 캡션을 autoregressive로 생성”하도록 학습한다.
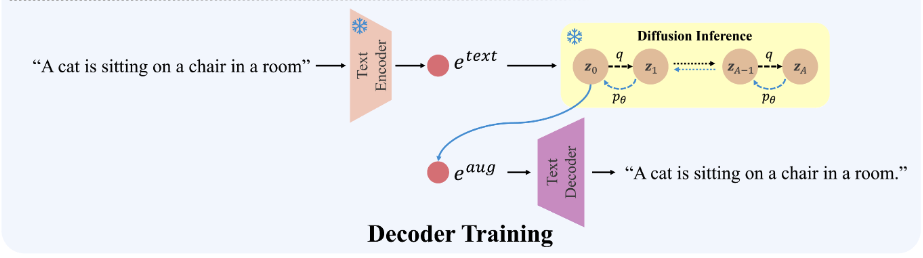
Diffusion-Augmented Text Embeddings
역확산을 거친 embedding이 원본과 완전히 같지 않을 수 있고, 또한 “하나의 vision embedding이 하나의 텍스트 embedding으로 일대일 매핑되지 않을 수 있다”는 이유로 디코더 학습에 증강 embedding을 포함한다.
증강은 다음 두 단계로 구성된다.
1) $z_0$를 정방향 확산으로 timestep $A$까지 Noise 추가
\[q(z_A\mid z_0)=\mathcal{N}\!\left(z_A;\sqrt{\bar\alpha_A}z_0,(1-\bar\alpha_A)I\right) \tag{7}\]$z_A$를 reverse process로 복원해 증강 embedding $e^{aug}$를 만들고, 이를 prefix로 디코더를 학습
이때 빠른 denoising을 위해 DDIM을 사용
디코더의 학습 loss은 다음과 같이 정리된다.
\[L_{AR}=-\sum_{t=1}^{L}\log p(y_t\mid y_{<t}, e^{aug}) \tag{8}\]Decoder 입력 어댑터: projection layer, prefix projector, soft prompts
논문 구현 상세는 디코더 측 입력 모듈을 다음처럼 둔다고 적는다.
- projection layer: CLIP embedding 512차원을 768차원으로 투영
- prefix projector: 2층 fully connected로 구성
- learnable soft prompts
이 구성은 “CLIP embedding을 GPT-2 hidden size에 맞추고, 디코더가 잘 쓰는 형태(프리픽스 token열)로 변환하며, 소프트 프롬프트로 캡셔닝 모드 컨텍스트를 준다”는 목적에 맞는 전형적인 어댑터 설계로 해석된다.
Inference Process

추론의 핵심은 이미지 embedding을 역확산 과정의 중간 시점 $M$에 삽입하는 것이다. 논문은 $T > M > 0$에서, $t=M$부터 역확산을 시작해 이미지 embedding을 텍스트 분포로 점진적으로 정제하며, 이 과정을 diffusion-bridging이라 부른다.
이 설계의 직관은 다음 한 줄로 정리된다.
완전 노이즈 $z_T$에서 시작할 필요가 없다
“paired vision/text embedding이 완전히 멀리 있지 않고 상대적으로 가깝다”는 관찰 때문그래서 이미지 embedding을 “텍스트 embedding에 잡음이 섞인 상태”로 보고 중간 step에서부터 denoise하면 Text-like embedding으로 이동시킬 수 있다고 본다
Experiments
Evaluation on Modality Gap
이 절의 실험 목적은 “Diffusion Bridge가 실제로 modality gap을 줄였는가”를 시각화(UMAP)와 정량화(cosine similarity)로 입증하는 데 있다.
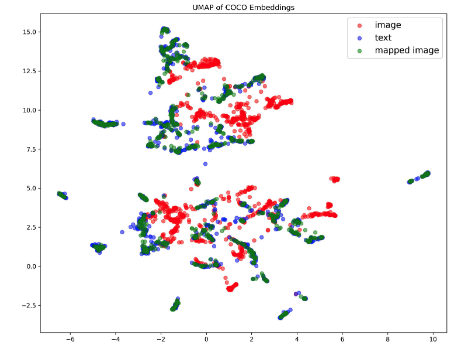
위는 COCO validation에서 $\hat e_{img}$(빨강), $\hat e_{text}$(파랑), $\tilde e_{img}$(초록)를 UMAP으로 시각화한다. 이미지/텍스트가 분리 클러스터를 만들고, diffusion으로 매핑된 초록 점이 파랑(텍스트) 클러스터에 겹치면 gap이 줄었다는 정성적 증거가 된다.

Table 1은 다양한 pair에 대한 평균 코사인 유사도를 보고한다. 핵심 수치는 다음처럼 해석된다.
- (a) paired text–image 유사도(Embedding): 0.306으로 낮다
(c) paired text–text 유사도(Embedding): 0.652로 높다
→ 같은 이미지에 대해 텍스트끼리는 훨씬 더 가깝지만, 이미지-텍스트는 멀다는 것이 gap의 정량적 근거가 된다.- (d) text–(bridged image) 유사도(Embedding): 0.606으로 크게 상승한다
→ diffusion-bridging이 이미지 embedding을 텍스트 쪽으로 이동시킨다는 정량 증거가 된다.
또한 Table은 “Projector를 통과시키면 유사도가 전반적으로 올라가지만 unpaired에서도 함께 올라 환각 위험이 생길 수 있다”는 논문 해석을 담고 있다.
왜 Projector가 unpaired 유사도까지 끌어올릴 수 있는가
논문은 현상을 관찰하고 환각 가능성을 언급한다.
이를 기하 관점에서 설명하면, projector는 $x \mapsto Wx$ 같은 변환으로 embedding 공간의 내적(metric)을 사실상 $W^\top W$로 바꾼다.
이때 특정 방향 성분을 강하게 강조하는 형태로 학습되면(“좁은 원뿔로 몰림” 같은 현상), paired만이 아니라 unpaired도 함께 각도가 좁아져 코사인이 전반적으로 상승할 수 있다.
Table의 (e)(f)에서 unpaired 유사도 자체가 크게 올라가는 것이 이 직관과 부합한다.
Zero-shot Image Captioning
In-Domain Captioning
이 실험의 목적은 “gap을 줄인 embedding 정렬이 실제 캡션 품질로 이어지는가”를 입증하는 데 있다. Diffusion Bridge는 MSCOCO에서 여러 지표에서 강한 결과를 보고하며, 논문은 이를 “큰/다양한 데이터에서 텍스트 분포를 잘 학습해 정렬이 잘 된다”는 방향으로 해석한다.
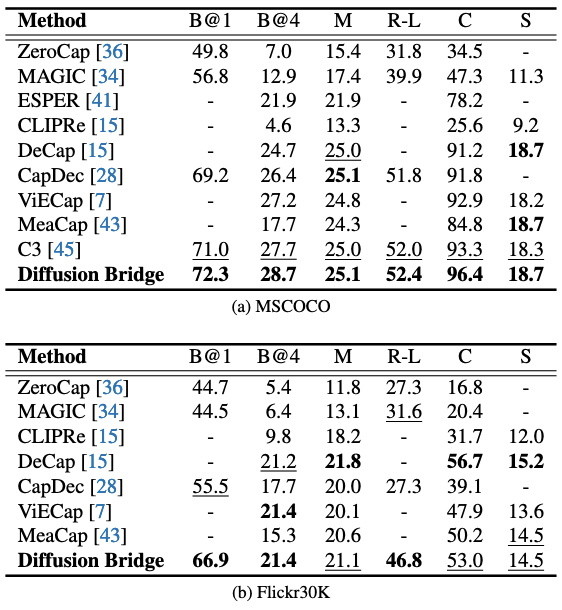
위에서 Diffusion Bridge는 MSCOCO에서 C3 및 다른 방법들과 비교해 상위 성능을 제시한다.
Flickr30K에서는 DeCap 같은 메모리/투영 기반 방법이 상대적으로 강할 수 있으며, 논문은 Flickr30K의 작은 규모 때문에 diffusion이 텍스트 분포를 충분히 포착하지 못할 가능성을 언급한다.
Cross-Domain Captioning
이 실험의 목적은 “텍스트 분포 prior로 학습한 정렬이 도메인이 바뀌어도 일반화되는가”를 입증하는 데 있다.
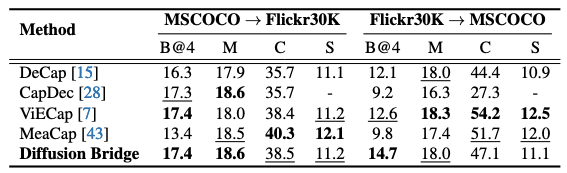
MSCOCO→Flickr30K, Flickr30K→MSCOCO 설정의 성능을 비교하며, Diffusion Bridge가 경쟁력 있는 수준을 유지한다.
또한 논문은 CIDEr/SPICE 같은 “더 세밀한 의미/내용 정합” 지표에서 entity-hard-prompt 계열(ViECap 등)이 강할 수 있다고 해석하며, 양자가 보완적일 수 있다고 말한다.
보충자료의 plug-and-play 실험은 이 보완성을 실제로 보여준다. Diffusion Bridge와 ViECap을 결합하면 두 방향(MSCOCO→Flickr30K, Flickr30K→MSCOCO) 모두에서 여러 지표가 개선되었다고 보고한다.
Ablation studies
Effectiveness of each component
이 절의 실험 목적은 “성능 향상이 어떤 구성요소에서 오는가”를 분해해 입증하는 데 있다.
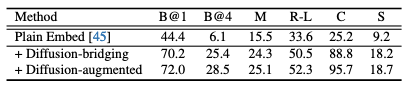
(1) Plain Embed(텍스트 embedding만 학습), (2) +Diffusion-bridging(추론에서만 정렬), (3) +Diffusion-augmented(정렬+증강학습)을 비교한다.
bridging만 추가해도 성능이 크게 상승하고, 증강까지 추가하면 추가 향상이 나타난다.
이는 (a) “추론에서 embedding을 정렬하는 것”이 핵심이고, (b) “디코더 강건화(증강학습)”가 추가 이득을 준다는 것을 보여준다.
The Effect of Inference Steps
이 절의 실험 목적은 “중간 삽입 step $M$이 정렬의 강도/품질을 좌우하는가”를 보이는 데 있다.
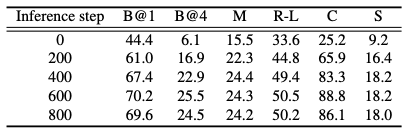
Table 5에서 inference step을 0→600 으로 늘리면 전반적으로 성능이 증가하고, 800에서 일부 지표가 소폭 하락한다. 논문은 과도한 step이 불필요한 노이즈/과처리로 매핑 정밀도를 해칠 수 있다고 해석한다.
즉 $M$은 “얼마나 깊게 denoise하여 텍스트 분포로 끌어갈지”를 조절하는 hyperparameter가 된다.
Conclusion
Diffusion Bridge는 텍스트 embedding 분포를 diffusion(DDPM)으로 학습한 뒤, 추론에서 이미지 embedding을 역확산 중간 단계에 삽입해 텍스트-라이크 embedding으로 점진 정제함으로써 CLIP의 modality gap을 줄이고 zero-shot Image captioning 성능을 향상시키는 방법이 된다.