[Paper Review] DreamBooth
[논문 리뷰] DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation : arxiv
구글과 보스턴 연구진이 2022년에 발표한 논문으로, Diffusion 논문에 대한 새로운 Fine-tuning 기법을 제시하였다. 특정 피사체에 대해 적은 데이터만으로도 대상의 사실적인 이미지를 생성할 수 있다. 대상의 핵심 특징을 보존하여 합성하고, 기존의 모델의 큰 오염 없이 새로운 피사체에 대해 이미지를 생성할 수 있다.
Introduction
이 연구는 특정 대상을 새로운 관점에서 자연스럽게 재구성하는 것에 집중한다. 최근 많이 연구되는 text-to-image 모델은 대규모 image-caption 데이터셋으로 semetic하고 prior하게 학습하여 다양한 고품질 이미지를 생성하는 것이 장점이다.
prior하다는 것은 “개”라는 단어를 다양한 상황과 포즈에서 나타날 수 있는 개의 여러 instance와 연결시키는 것

이 연구에서는 text-to-image diffusion 모델의 “개인화(personalization)“에 집중한다. 모델의 language-vision dictionary를 확장하여 사용자가 특정 subject를 자신이 원하는 새로운 단어와 결합하여 생성할 수 있도록 한다. 사용자가 생성하고자 하는 특정 대상에 새로운 단어를 연결하여 대상의 key feature를 high fidelity로 유지하면서 다양한 context 이미지를 합성할 수 있다.
본 논문에서는 특정 subject의 3~5장 이미지를 사용하여 대상을 rare token identifier로 나타내고 이를 모델의 ouput domain에 삽입하고, subject와 연결된 unique identifier를 사용하여 이미지를 합성한다.
이를 subject-driven generation이라 하며, 본 논문에서 이러한 새로운 문제를 정의하였다.
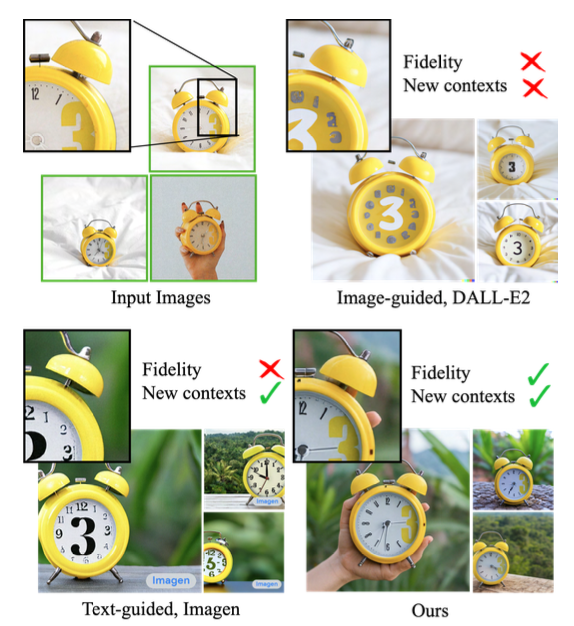
위 이미지는 DALL-E2, Imagen과 함께 본 논문에서 제안한 기법을 비교한다.
Input images에 있는 시계의 key feature(숫자 3이 특이한 글씨체로 쓰여진 시계)를 유지했는지 (fidelity), 다양한 context 이미지를 생성하였는지(New contexts)를 보여준다.
이 논문에서는 위와 같이 pretrain된 diffusion 기반의 text-to-image 모델에 대해 새로운 fine-tuning 기법을 제안한다.
Method
이 논문에서는 text 설명 없이s ubject에 대한 이미지 3~5장 만 주여지면, text prompt에 따라 detail fidelity가 높고 다양한 context로 이미지를 생성하는 것을 목표로 한다.
1. Text-to-Image Diffusion Models
text encoder $\Gamma$와 text prompt $\textbf{P}$로 만들어진 conditioning vector $c = \Gamma (\textbf{P})$가 있다. 이 $c$와 초기 $\epsilon \sim \mathcal{N}(0, \textit{I})$가 주어졌을 때, $\mathbf{x}_{\text{gen}} = \hat{ \mathbf{x}}_\theta (\epsilon, c)$를 생성한다.
또한 이 $\hat{ \mathbf{x}}_\theta$는 다음과 같이 noise 이미지 $\mathbf{z}_t := \alpha_t\mathbf{x} + \sigma_t\mathbf{\epsilon}$의 noise를 제거하도록 학습한다.
\[\mathbb{E}_{\mathbf{x},c, \epsilon, t} \left[w_t || \hat{\mathbf{x}_\theta}(\alpha_t\mathbf{x} + \sigma_t\epsilon, c) - \mathbf{x}||^2_2\right] \tag{1}\]2. Personalization of Text-to-Image Models
첫번째 task는 subject의 instance를 모델의 output domain에 삽입하는 것이다. 몇장 안되는 subject의 이미지로 생성 모델을 fine-tuning 할 때 가장 핵심적인 문제는 target distribution을 잘 학습하지 못하는 것이다. (그밖에도 overfitting, mode-collapse가 있음)
이를 해결하기 위해 Eq. 1의 diffusion loss를 fine-tuning하여 새로운 정보를 domain에 삽입하는 데 효과가 좋다는 것을 발견하였다고 한다.
Designing Prompts for Few-Shot Personalization
목표는 diffusion 모델의 dictionary(사전)에 새로운 (unique identifier, subject) 쌍을 이식하는 것이다. subject의 모든 input image에 “a [identifier] [class noun]”라는 label을 지정해준다.
[identifier]는 subject에 연결된 고유값이며, [class noun]는 dog, cat과 같은 class를 말한다.
[class noun]의 경우 classifier를 사용하거나, 사용자가 직접 붙여준다.
즉, 논문에서는 모델의 특정 class의 prior를 subject의 unique identifier embedding과 연결하여 다양한 context에서 subject를 생성할 수 있도록 한다.
Rare-token Identifiers
먼저 영어에서 각 문자를 tokenize하여 rare한 token을 찾는다. 이 token을 text space로 변환하여 identifier가 강력한 prior를 가질 확률을 최소화한다. 이를 rare-token lookup이라 하며, 이를 수행하여 rare-token identifier $f(\hat{\textbf{V}})$ sequence를 얻는다. 그런 다음, $f(\hat{\textbf{V}})$를 de-tokenize하여 text $\hat{\textbf{V}}$를 얻는다.
$f$는 문자 sequences를 token에 mapping하는 tokenizer이고, $\hat{\textbf{V} }$는 $f(\hat{\textbf{V}})$에서 decoding된 text를 의미한다. 논문에서 token은 3자 이하의 unicode로 구성된 문자일 때 성능이 가장 좋다고 언급한다.
3. Class-specific Prior Preservation Loss
논문에서는 subject의 fidelity를 극대화 하기 위해서는 model의 모든 layer를 fine-tuning 해야함을 경험적으로 알 수 있었다고 한다. 여기에는 text-embedding을 condition으로 하는 fine-tuning layer가 포함되며, 이로 인하여 language drift문제가 발생한다고 한다.
language drift
language drift란 language model fine-tuning에서 관찰되는 문제로, 특정 task에 맞게 fine-tuning된 모델이 task에 대한 성능을 올리기 위해 점차 언어에 대한 syntactic and semantic knowledge을 잃어버리는 현상이다.
논문에서는 위와 같이 언어 모델에서 나타나는 유사한 문제가 diffusion 모델에 영향을 미치는 것을 자기네들이 처음 발견하였다고 한다.
또 다른 문제는 output의 다양성이 감소할 수 있다는 것이다. text-to-image diffusion 모델은 다양성이 높지만, 적은 image 데이터셋으로 fine-tuning 할 때 variability(가변성)이 줄어들 위험이 있다.
위 언급한 2가지 문제를 해결하기 위해 Class-specific Prior Preservation Loss를 제안한다. 자체적으로 생성된 sample로 모델을 가두어 여러번의 fine-tuning이 시작되어도 prior를 유지하도록 하는 것이다.
randon initial noise $\mathbf{z}_{t_1} \sim \mathcal{N}(0, \textbf{I})$과 conditioning vector $\textbf{c}_{pr} := \Gamma(f(\text{“a [class noun]”}))$로 고정된 pretrained diffusion model에서 $\mathbf{x}_{pr} = \hat{\mathbf{x}}(\mathbf{z}_{t_1}, \mathbf{c}_{pr})$을 생성한다.
해당 loss는 다음과 같다.
\[\mathbb{E}_{\mathbf{x},c, \epsilon, \epsilon', t} \left[w_t || \hat{\mathbf{x}_\theta}(\alpha_t\mathbf{x} + \sigma_t\epsilon, c) - \mathbf{x}||^2_2 + \lambda w_{t'}|| \hat{\mathbf{x}_\theta}(\alpha_{t'}\mathbf{x}_{\text{pr}} + \sigma_{t'}\epsilon', c_{\text{pr}}) - \mathbf{x}_\text{pr}||^2_2 \right] \tag{2}\]여기서 추가된 2번째 term은 생성된 sample로 모델을 supervise하는 prior-preservation term이며, $\lambda$는 이 term의 가중치를 조절한다.
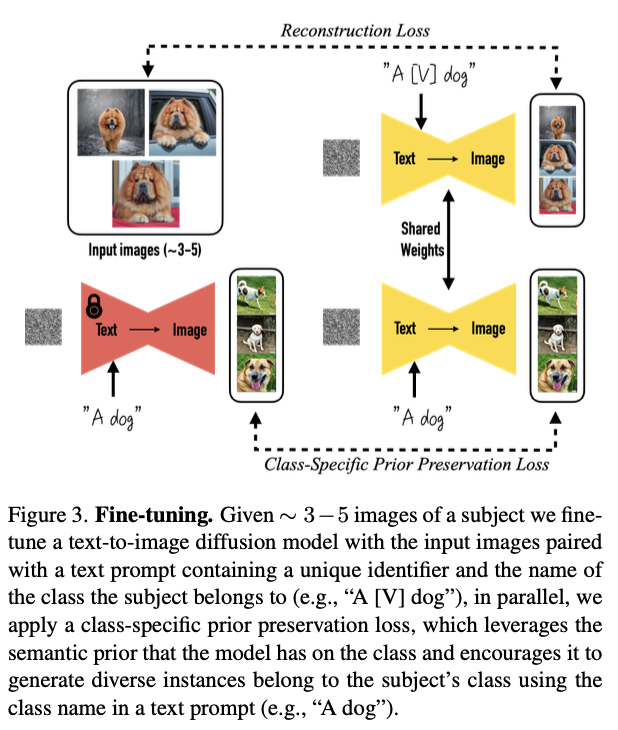
위 사진은 class에서 생성된 sample과 Prior Preservation Loss로 모델을 fine-tuning하는 과정을 보여준다.