[Paper Review] Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs
[논문 리뷰] Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs
Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, Saining Xie
CVPR 2024 (Highlight)
[Arxiv]
CVPR2024에서 Highlight를 받은 논문이다.
Multimodal LLMs의 시각적 한계에 대한 연구이며 특히 CLIP과 통합될 때의 한계를 중점적으로 다룬다. 연구는 CLIP가 시각적으로 확연히 다른 이미지를 유사하게 인식하는 “CLIP-blind 쌍”을 식별하는 데 초점을 둔다.
Introduction

Multimodal LLM(MLLMs)은 최근 급격히 발전해왔지만, 여전히 위와 같이 visual적인 결함이 존재한다. 논문에서는 문제의 원인을 탐구하고자 하며, visual representations과 관련이 있다고 제안한다.
저자들은 다음과 같은 연구를 진행한다.
- CLIP-blind pairs(CLIP이 비슷하다고 인식하지만 시각적으로는 다른 이미지들)를 사용하여, MultiModal Visual Patterns(MMVP) 벤치마크를 구성
- 다양한 CLIP based Vision-Language 모델을 평가하고 CLIP이 어려워하는 시각 패턴과 MLLM의 성능 사이에 상관관계 탐구
- MLLM의 시각적 근거 능력을 상당히 향상시킬 수 있는 Mixture of Features(MoF) 접근 방식을 제안
대부분의 MLLM은 Vision Encoder로 CLIP을 채택한다. CLIP이 잘 인코딩하지 못하는 경우를 찾고(2장), <Mass- producing failures of multimodal systems with language models>에서처럼 Embedding space에서의 erroneous agreements를 이용한다.
만약 두 이미지가 시각적으로 다르지만 CLIP Vision Encoder에 의해 유사하게 인코딩된다면, 적어도 하나의 이미지는 모호하게 인코딩될 가능성이 있다. 이를 CLIP-blind pairs이라고 부르기로 하고, 이미지 간의 시각적 유사성을 측정하기 위해, DINOv2와 같은 vision-only self-supervised encoder를 사용한다.
저자들은 CLIP-blind pairs가 실제로 downstream MLLM에서 오류로 이어짐을 발견하였고, MultiModal Visual Patterns 벤치마크를 도입한다. 또한 MLLM의 실패 사례를 찾고, MMVP에서 CLIP이 어려워하는 시각 패턴을 탐구하고(3장), 대규모 CLIP 기반 모델로 이를 완화할 수 있는지 여부를 평가한다.
9개의 확인된 패턴 중 7개가 어떠한 대규모 CLIP 기반 모델로도 해결될 수 없음을 발견한다. 게다가, CLIP이 특정 패턴, 예를 들어 방향에 어려움을 겪는 경우, MLLM도 비슷한 단점을 보일 가능성이 높다는 것을 발견한다. 이는 CLIP 시각 인코더가 이러한 시스템에서 병목 현상이 될 수 있음을 보여준다.
마지막으로, 우리는 MLLM의 시각적 근거를 개선하기 위한 단계를 밟는다. MLLM의 시각적 결함이 CLIP 모델에 의존하기 때문에, 우리는 시각 중심 표현을 MLLM에 통합하는 영향을 조사한다(4장). 구체적으로, 우리는 오직 시각적 자기지도 모델인 DINOv2 [42]와 같은 시각 전용 자기지도 모델을 통합하는 방법을 탐구한다. 우리는 이 기술을 ‘특징 혼합’(MoF)이라고 부른다. 우선, 우리는 CLIP 및 DINOv2 기능을 다양한 비율로 선형 혼합하는 것을 참조로서 첨가-MoF(A-MoF)를 도입한다. 이 과정은 DINOv2 기능이 시각적 근거에 더 효과적이지만, 지시를 따르는 능력이 감소하는 비용을 초래함을 밝힌다. 이를 해결하기 위해, 우리는 CLIP 및 DINOv2 모델의 시각적
MMVP Benchmark

1. CLIP-blind Pairs
CLIP vision encoder가 잘 인코딩하지 못하는 이미지를 직접 찾기 위해, 우리는 Tong et al.에서 제안된 아이디어를 확장하여 Vision model에서 blind 쌍을 자동으로 찾는다.
기본 원리는 간단하다:
두 이미지가 눈에 띄게 시각적으로 다르지만 CLIP vision encoder에 의해 유사하게 인코딩된다면, 그 중 하나는 모호하게 인코딩될 것이다(figure 왼쪽).
두 이미지 간의 시각적 차이를 측정하기 위해, 우리는 reference 모델 내에서 이미지 representations을 검토한다:
vision- only self-supervised model인 DINOv2
ImageNet과 LAION-Aesthetics에서 CLIP-blind pairs를 수집한다.
CLIP-ViT-L-14 를 사용하여 embedding을 계산하고 DINOv2-ViT-L-14를 사용하여 DINOv2 embedding을 계산하여 cosine similiarity가 CLIP은 0.95 이상이고 DINOv2은 0.6 미만인 pairs을 수집한다.
2. Designing Benchmark from CLIP-blind Pairs
Multimodal Visual Patterns(MMVP) 벤치마크를 소개하고 Visual Question Answering (VQA) 벤치마크를 사용한다.
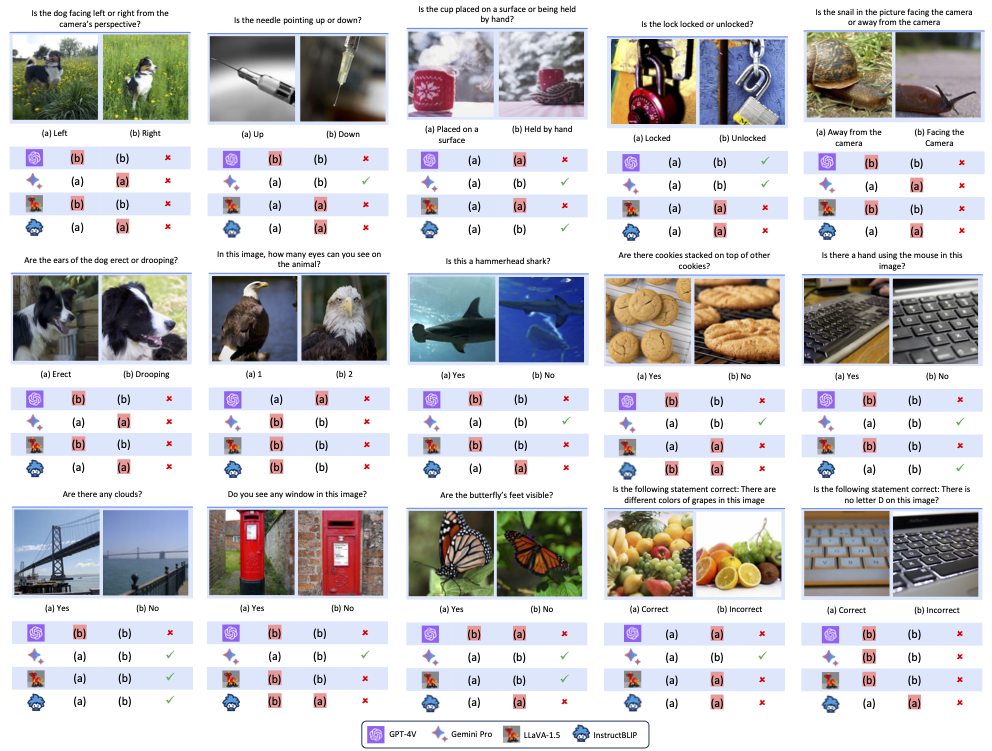
수집된 CLIP-blind pairs를 활용하여, 150쌍의 이미지와 300개의 질문을 신중하게 디자인한다. 각 pair에 대해, 우리는 CLIP vision encoder가 간과하는 detail을 직접 찾고(위 그림 중앙), 이러한 detail을 탐구하는 질문을 만든다.
예를 들어 “Is the dog facing left or right?”(위 figure 오른쪽, 아래 figure). 주 목적은 MLLM 모델이 비교적 간단하고 명확한 질문에 실패하고, 결정적인 detail을 간과할 것인지를 결정하는 것이다. 따라서 질문은 단순하고 모호하지 않게 제작된다.
3. Benchmark Results
SOTA 오픈 소스 모델인 LLaVA-1.5, InstructBLIP, Mini-GPT4와 폐쇄 소스 모델인 GPT-4V, Gemini, Bard를 평가하였다.
평가에서 각 질문은 독립적으로 질문되어 채팅 이력에서의 bias를 제거하였고, user 연구를 통해 인간의 성능도 포함시켰다.
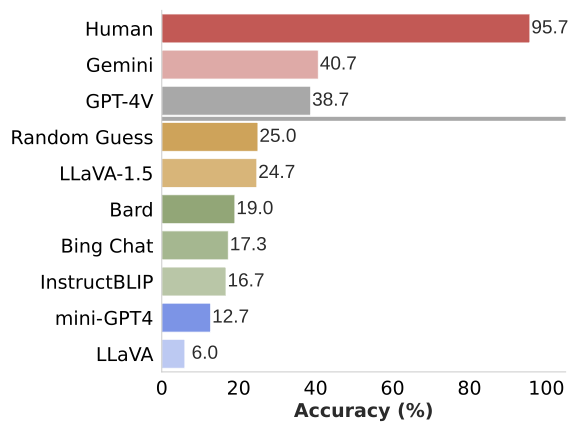
인간과 MLLM 모델 사이에는 상당한 성능 격차가 있다. MLLM은 종종 인상적인 결과를 보여주지만, GPT-4V와 Gemini를 제외한 모델은 Random Guess인 25% 미만 점수를 얻었다. 가장 진보된 GPT-4V와 Gemini도 기본적인 시각적 근거 질문에 도전을 받는다. 그 결과가 Instroduction의 이미지와 2. Designing Benchmark from CLIP-blind Pairs에 있는 이미지이다. 이는 모델의 크기나 훈련 데이터에 관계없이 시각적 detail을 처리하는 데 어려움을 겪는다는 것을 시사한다.
Systematic Failures in CLIP
다음과 같은 탐구를 수행한다.
- CLIP-blind pairs에서 시스템적인 시각 패턴의 등장 여부
- 시각 패턴이 CLIP과 MLLM 모델의 성능에 미치는 영향
1. Visual Patterns in CLIP-blind Pairs
CLIP-blind pairs에서 시스템적인 시각 패턴을 직접 포착하기는 너무 추상적이기 때문에, MMVP 벤치마크에서 질문과 옵션을 활용한다. 이 질문들을 사용하여, 이미지에서 추상적인 시각 패턴을 더 명확한 언어 기반 설명으로 변환하여 쉽게 분류할 수 있다.
GPT-4 요청 Prompt
I am analyzing an image embedding model. Can you go through the questions and options, trying to figure out some general patterns that the embedding model strug- gles with? Please focus on the visual features and gener- alize patterns that are important to vision models [MMVP Questions and Options]
번역 : 나는 이미지 임베딩 모델을 분석하고 있다. 질문과 옵션을 검토하면서, 임베딩 모델이 어려워하는 일반적인 패턴을 찾아보라. 시각적 특징에 집중하고 시각 모델에 중요한 패턴을 일반화하라.
저자들은 9가지 패턴을 식별하였는데, 다음과 같다.
🧭 Orientation and Direction: 이 패턴은 이미지 내 객체의 방향을 인식하는 데 CLIP이 어려움을 겪는다는 것을 나타낸다. 예를 들어, 동일한 객체가 다른 방향을 향하고 있을 때 이를 구분하는 데 실패한다.
🔍 Presence of Specific Features: CLIP은 특정한 물리적 특징이나 속성의 존재를 간과하거나 잘못 인식하는 경우가 많다. 예를 들어, 이미지에 나타난 특정 유형의 꽃이나 동물의 특징을 인식하지 못한다.
🔄 State and Condition: 이 패턴은 객체의 상태나 조건의 변화를 인식하는 데 CLIP이 실패한다는 것을 나타낸다. 예를 들어, 열려 있는 창문과 닫힌 창문을 구분하지 못한다.
🔢 Quantity and Count: CLIP은 이미지 내의 객체 수를 정확히 계수하는 데 어려움을 겪는다. 예를 들어, 여러 개의 과일이나 동물을 정확히 세는 데 실패한다.
📍Positional and Relational Context: 이 패턴은 객체 간의 공간적 관계를 인식하는 데 CLIP이 어려움을 겪는다는 것을 나타낸다. 예를 들어, 한 객체가 다른 객체 옆에 있는지 아래에 있는지를 구분하지 못한다.
🎨 Color and Appearance: CLIP은 때때로 색상이나 객체의 외관을 잘못 해석한다. 예를 들어, 밝은 색과 어두운 색을 구분하지 못하거나, 특정 색상의 꽃을 다른 색상으로 잘못 인식한다.
⚙️ Structural and Physical Characteristics: 이 패턴은 CLIP이 객체의 구조적, 물리적 특성을 인식하는 데 실패한다는 것을 나타낸다. 예를 들어, 부러진 가지나 찌그러진 캔을 정상적인 상태로 잘못 인식한다.
🅰 Text: 텍스트 패턴은 CLIP이 이미지 내의 텍스트를 인식하거나 해석하는 데 오류를 범한다는 것을 보여준다. 예를 들어, 특정 단어나 숫자를 잘못 읽거나 해석한다.
📷 Viewpoint and Perspective: 이 패턴은 CLIP이 이미지의 촬영 각도나 관점을 올바르게 해석하지 못한다는 것을 나타낸다. 예를 들어, 위에서 본 꽃과 옆에서 본 꽃을 구분하지 못한다.
2. The MMVP-VLM Benchmark
MMVP-VLM 벤치마크는 CLIP이 처리하기 어려운 시각 패턴을 체계적으로 연구하고자 하는 목적으로 만들어졌다.
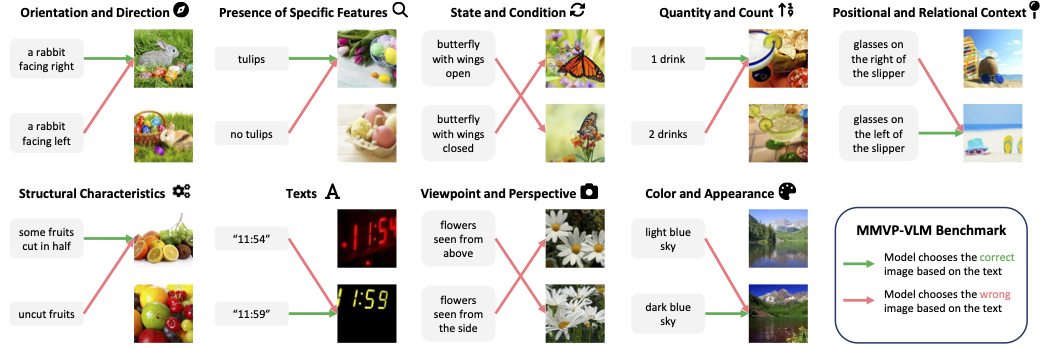
MMVP 벤치마크에서 추출한 질문들을 더 단순한 언어로 재분류하여 각각의 시각 패턴별로 질문을 구성한다. 각 시각 패턴을 대표할 수 있도록 균형 잡힌 질문 수를 유지하기 위해 필요한 경우 몇 가지 질문을 추가한다. 위 예시들은 시각 패턴에 따라 이미지 쌍을 보여준다. 각 쌍은 모델이 텍스트 설명을 바탕으로 올바른 이미지를 선택하는지 여부를 평가하는데 사용된다.
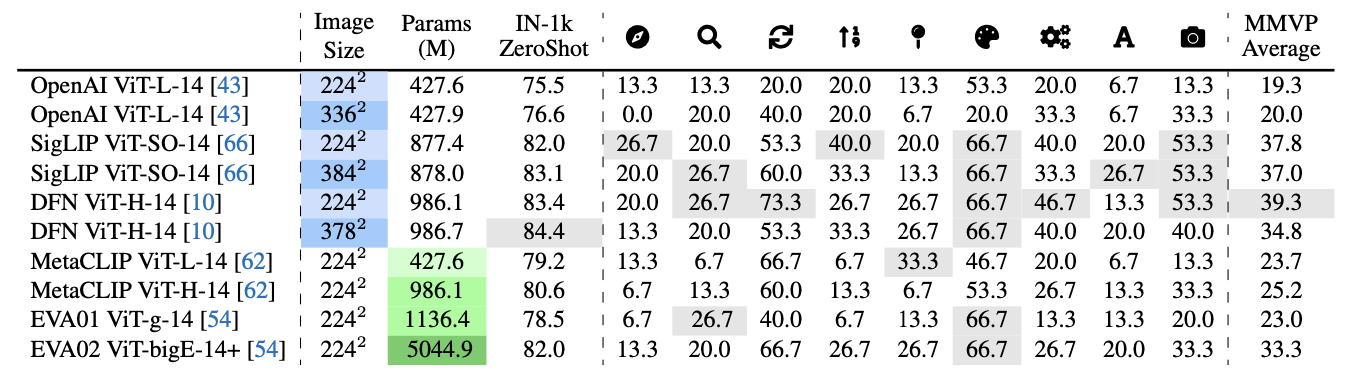
이 벤치마크를 통해 다양한 CLIP 모델들을 평가한다. 표 1에서 이러한 모델들의 네트워크 크기와 훈련 데이터를 증가시키는 것이 🎨Color and Appearance 및 🔄State and Condition과 같은 두 가지 시각 패턴을 식별하는 데 도움이 되는 것을 발견했다.
그러나 나머지 시각 패턴들은 모든 CLIP 기반 모델들에게 계속해서 도전 과제를 제시한다. 또한, ImageNet-1k zero-shot 정확도가 시각 패턴 성능의 결정적인 지표가 되지 않는 것을 발견했다. 이는 모델의 능력을 정확하게 평가하기 위해 MMVP-VLM과 같은 추가 평가 지표가 필요하다는 것을 강조한다.
3. How CLIP’s Errors Affect MLLMs
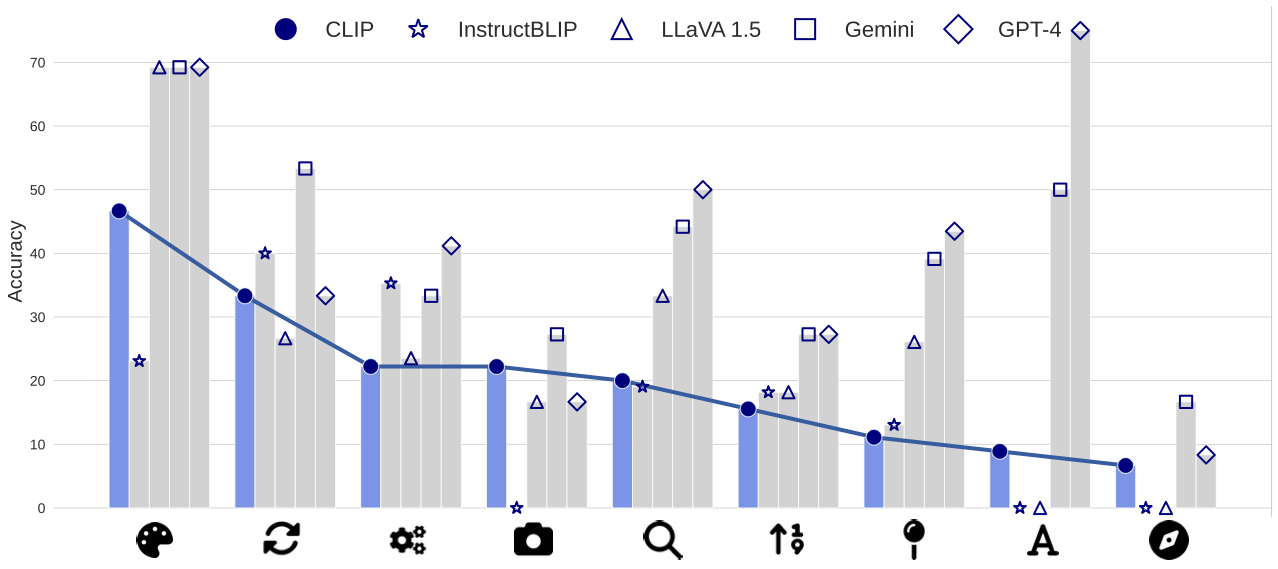
위 도표는 각 시각 패턴에 대해 CLIP과 MLLM의 성능을 나타낸다. CLIP Vision Encoder가 특정 시각 패턴에서 성능이 떨어질 때, MLLM도 비슷한 양상을 보인다. LLaVA 1.5 와 InstructBLIP의 경우 성능의 상관관계가 강하게 나타난다.
또한 CLIP과 MLLM의 각 시각 패턴에 대한 성능 사이의 피어슨 상관 계수를 계산한다. 결과는 LLaVA 1.5와 InstructBLIP 모두에서 0.7 이상의 계수 점수를 보여준다. 이는 CLIP에서 시각 패턴 인식의 약점이 MLLM으로 전이된다는 것을 의미한다.
Mixture-of-Features (MoF) for MLLM
앞서 설명한 MLLM의 문제점이 CLIP Vision Encoder에서 비롯된다면, 어떻게 성능이 더 향상된 Vision Encoder를 만들 수 있을까?
이 섹션에서 이를 위해 CLIP 기능과 vision-only SSL model 기능을 혼합 Mixture-of-Features (MoF)를 소개한다.
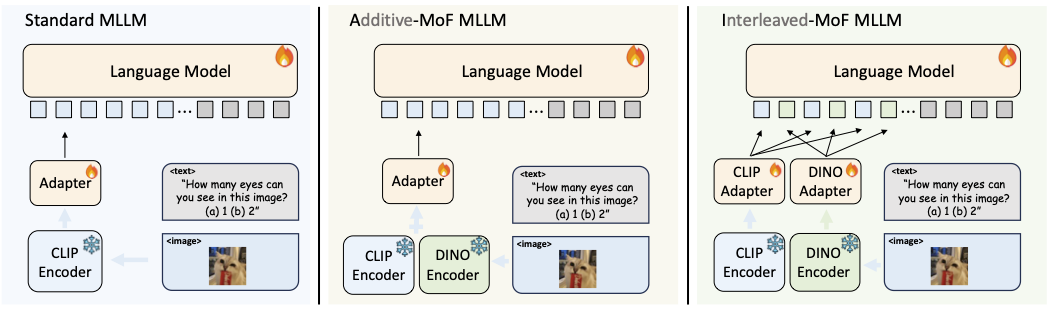
Experiment Setting
LLaVA 를 사용하여 MLLM에서 Vision Encoder를 연구한다. LLaVA는 pretrained CLIP Encoder를 사용하고 Adapter를 훈련하여 이미지 토큰을 언어 토큰과 정렬한다(그림 왼쪽).
vision-only SSL mode로는 DINOv2를 사용한다.
Additive MoF
MLLM에 pretrained DINOv2 Encoder를 추가하고, CLIP pretrained Encoder와 혼합한다. $α$ 계수를 사용하여 CLIP의 비율을 제어하고 $1 - α$로 DINOv2를 제어하여 이를 선형적으로 추가한다(그림 중간 참조).
모델의 시각적 근거 능력을 MMVP로 평가하고, LLaVA 벤치마크로 지시를 따르는 능력을 평가한다. 처음에는 CLIP 100% 사용에서 DINOv2 100% 사용으로 전환하는 실험을 수행한다. 이 테스트에서 우리의 발견은 다음 통찰력을 제공한다:
DINOv2 비율 ⇧ - MLLM의 지시를 따르는 능력 ⇩ - 시각적 근거 능력 ⇧
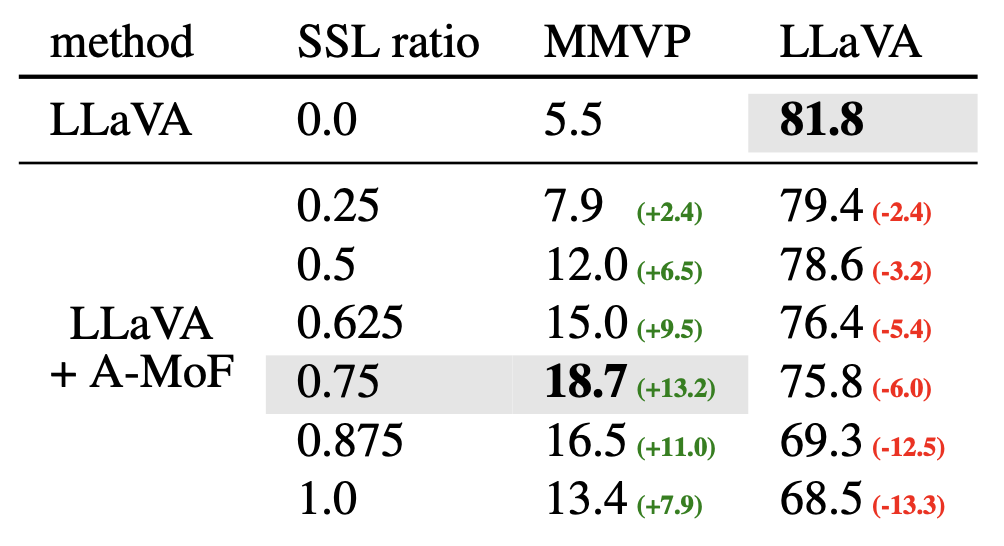
DINOv2 비율이 87.5%에 도달하면 급격한 감소 발생.⇩
DINOv2 비율이 75%를 초과하면 지시를 따르는 능력이 현저히 저하
DINOv2 기능을 추가하거나 대체하면 시각적 근거와 지시 따르기 사이의 trade-off가 발생한다.
- DINOv2 기능 비율 ⇧ - 시각적 인식 ⇧ - 언어적 지시를 따르는 능력 ⇩
- CLIP 기능 ⇧ - 언어 이해 능력 ⇧ - 시각적 인식 ⇩
Interleaved MoF
위 Additive MoF와 달리 CLIP 및 DINOv2 Encoder를 동시에 통과한 임베딩은 각각 Adapter를 거치며 처리된다. 처리된 특징들은 원래의 공간적 순서를 유지하면서 교차 혼합된다. 그 후, 교차 혼합된 특징들은 LLM에 공급된다(그림 오른쪽 참조).
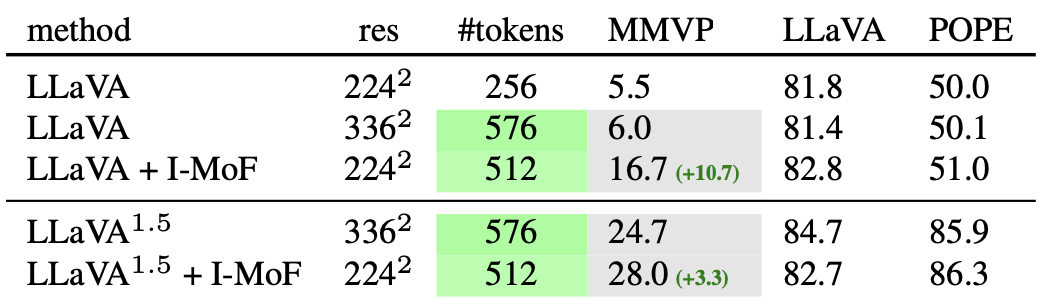
LLaVA 셋팅에서 Interleaved MoF는 MMVP에서 시각적 근거 능력을 향상시키며, 10.7%의 증가를 보여주며 LLaVA-1.5 세팅에서도 유사한 증가를 보인다.
또한, POPE 벤치마크에서도 평가하여, Interleaved-MoF가 원래의 LLaVA 모델에 비해 일관된 개선을 보여주는 것을 확인한다. vision-only SSL 모델과 VLM 모델 간의 MoF를 교차하는 것이 시각적 근거 작업에서 성능을 개선하는 데 도움이 된다.
Discussion
Vision representation 모델인 VLM과 vision-only SSL 모델이 각각 다른 측면에서 뛰어나다는 것을 알 수 있다. MoF 실험에서 보여진 것처럼, CLIP VIsion 모델과 vision-only SSL 모델은 상호 보완적인 특징을 학습한다. 이는 visual representation learning에 대한 evaluation metrics을 다양화할 필요가 있다는 것을 시사한다.