[Paper Review] 🦩 Flamingo: a Visual Language Model for Few-Shot Learning
[논문 리뷰]🦩 Flamingo: a Visual Language Model for Few-Shot Learning
🦩 Flamingo: a Visual Language Model for Few-Shot Learning
Jean-Baptiste Alayrac et al
NeurIPS 2022
[arXiv]
구글 DeepMind에서 개발한 Vision-Language Model이다.
Background
Multimodal learning은 이미지와 텍스트를 동시에 이해하여 VQA(Vision Question Anwsering), Image Captioning 등의 task를 수행하는 것을 목표로 한다.
기존의 VLM들은 주로 대량의 Image-Text 데이터로 pretrain한 후, 각 downstream task별로 fine-tuning하는 Supervised Learning을 사용한다.
→ task마다 수천 개의 라벨링된 데이터를 수집하고 모델을 재학습해야 한다는 점에서 확장성의 한계
예를 들어, CLIP과 같은 contrastive learning 기반 모델들은 웹으로부터 대규모 Image-Text를 학습하여 zero-shot Classification을 보여주었지만, 출력이 Image-Text similarity score 형태에 한정되어 있어 Generation이 필요한 개방형 질문(예: captioning, Q&A)에는 그대로 적용하기 어렵다.
ViLT 등 이미지와 텍스트를 함께 입력으로 받아 Transformer로 처리하는 생성형 VLM은 다음과 같은 한계가 존재한다.
- 크기가 제한적
- 소량의 예시만으로 새로운 task에 generalization 불가
요약하면, 기존 VLM들은 거대하지만 비생성적 모델(예: CLIP) 또는 생성은 가능해도 태스크 적응을 위해 추가 학습이 필요한 모델(예: ViLT 등)로 구분되며, 사람처럼 몇 가지 예시만 보고도 새로운 시각 언어 task를 수행할 수 있는 범용 모델은 부재했다.
Contrastive Learning \(L_{\text{contrastive:txt2im}} = -\frac1N\sum_{i=1}^N \log\frac{\exp\bigl(L_i^\top V_i\beta\bigr)} {\sum_{j=1}^N\exp\bigl(L_i^\top V_j\beta\bigr)}\)
\[L_{\text{contrastive:I2T}} = -\frac1N\sum_{i=1}^N \log\frac{\exp\bigl(V_i^\top L_i\beta\bigr)} {\sum_{j=1}^N\exp\bigl(V_i^\top L_j\beta\bigr)}\]- 분자에 들어가는 $\exp(L_i^\top V_i/\tau)$ 항은 positive 쌍의 유사도를 높임
- 분모에 있는 $\sum_j \exp(L_i^\top V_j/\tau)$ 항은 “negative 쌍과의 유사도를 상대적으로 낮춤
“올바른(pair) 임베딩만 골라내도록” 크로스엔트로피를 최소화하고, 다른 모든 임베딩와는 거리를 벌리도록 학습하는 Loss
Introduction
Flamingo는 Few-Shot 학습에 특화된 VLM로서, 몇 가지 예시(Text-Image pair)만으로도 새로운 Multimodal task를 해결할 수 있도록 설계되었다. Flamingo는 이미지/비디오와 텍스트가 섞인 시퀀스를 입력 받아 다음에 이어질 텍스트를 생성함으로써 VQA, 이미지 캡션 생성, 비디오 설명 등 다양한 작업을 하나의 모델로 수행한다.
Flamingo의 핵심 아이디어는 강력한 pretrained (Vision, LLM)을 연결하는 것이다.
Flamingo에서는 이 둘을 효과적으로 결합하기 위해 새로운 아키텍처 요소들을 도입했다.
- Pretrained Vision and LLM을 연결 module
- Image-Text가 임의로 배치된 시퀀스 처리 메커니즘
- 이미지뿐 아니라 동영상까지 Input
이러한 구조 덕분에 Flamingo는 인터넷에서 수집한 대규모 이미지/텍스트 혼합 데이터로 멀티모달 사전학습을 수행할 수 있었다.
그 결과 별도 fine-tuning 없이 다양한 Vision-Language task에서 뛰어난 few-shot 성능을 보여주었다 .
Flamingo는 LLM의 범용적 이해력과 Vision 모델의 인지 능력을 결합하여, 적은 예시만으로 새 multimodal task들을 학습할 수 있는 범용 VLM이다.
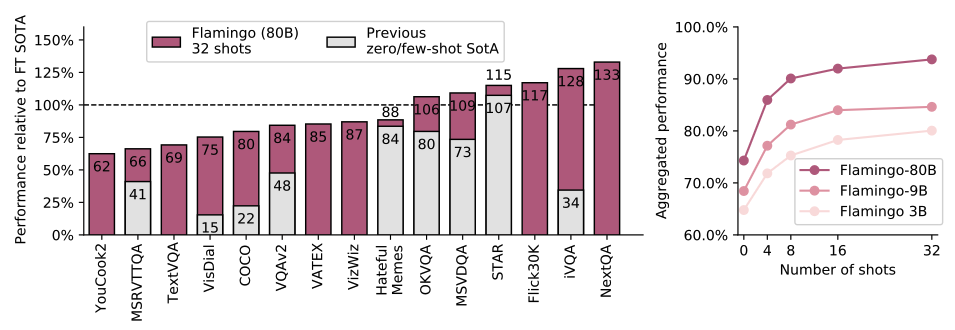
좌 : 여러 데이터셋에서 이전까지 SOTA 성능과 Flamingo의 성능 비교 그래프
우 : Flamingo 모델 사이즈와 shot (데이터) 수에 따른 성능 그래프
Goal
few-shot만으로 새로운 Vision-Language task를 추가 학습 없이 수행할 수 있는 범용 VLM을 만드는 것.
Motivation
기존 VLM들은
- Contrastive learning(CLIP)
- zero-shot classification은 가능, text generation 능력 부재
- Generative 모델(ViLT)
- text generation은 가능, task별 fine-tuning 필수
두 방식 모두 새로운 task마다 대량의 labeled 데이터와 모델 재학습이 필요하므로, “사람처럼 몇 가지 예시만 보고도 즉시 적응”하는 Few-Shot 멀티모달 학습을 구현할 필요가 있었다.
Contributions
Flamingo 아키텍처 제안
강력한 pretrain Vision 모델(NFNet-F6)과 Language 모델(Chinchilla)을 freeze한 채
두 모델 사이에 Perceiver Resampler와 게이트된 cross-attention-dense(XATTN-Dense) layer 삽입
“이미지/비디오 ↔ 텍스트”를 임의로 교차한 시퀀스를 처리하고 자유형 텍스트를 생성
In-context Few-Shot learning
- 별도 fine-tuning 없이, 4~32개의 예시(Image text pair)를 프롬프트로 제공하면 새로운 task에 즉시 적응
- VQA, Captioning, Video QA 등 16개 벤치마크에서 기존 zero/few-shot SOTA 달성
- 6개 task에서는 파인튜닝된 SOTA도 능가
In-context learning
- 모델에게 **추가 fine-tuning **없이, 입력 프롬프트(문제 설명+예시)만 보여 줌으로써 새로운 task를 수행하도록 하는 방식
Few-shot learning
- “소수(몇 개)의 labeled 예시만으로” 새로운 태스크를 학습하거나 적응하는 능력
- 일반적으로 1~32개 정도의 예시(shots)를 프롬프트에 포함시켜 모델이 패턴을 파악하도록 한다.
- 별도 fine-tuning 없이, 4~32개의 예시(Image text pair)를 프롬프트로 제공하면 새로운 task에 즉시 적응
효율적 Pretrain multi-modal 전략
- unlabeling 데이터를 사용
- 웹페이지에서 추출한 “image-text interleaved” 대규모 코퍼스(M3W)
- 수십억 쌍의 Image-text 및 Video-text pair
- 이를 혼합 학습하여, 멀티모달 문맥에서의 다음 token 예측 능력을 확보
- unlabeling 데이터를 사용
혁신적 기술 요소
- Perceiver Resampler: 가변 길이 Vision 특징을 64개 token으로 압축
- 게이트된 XATTN-Dense: tanh 게이트로 안정화된 cross-attention 삽입 기법
- 이미지별 어텐션 마스킹: 각 텍스트 token이 직전 이미지 token만 참조하도록 제한
Method
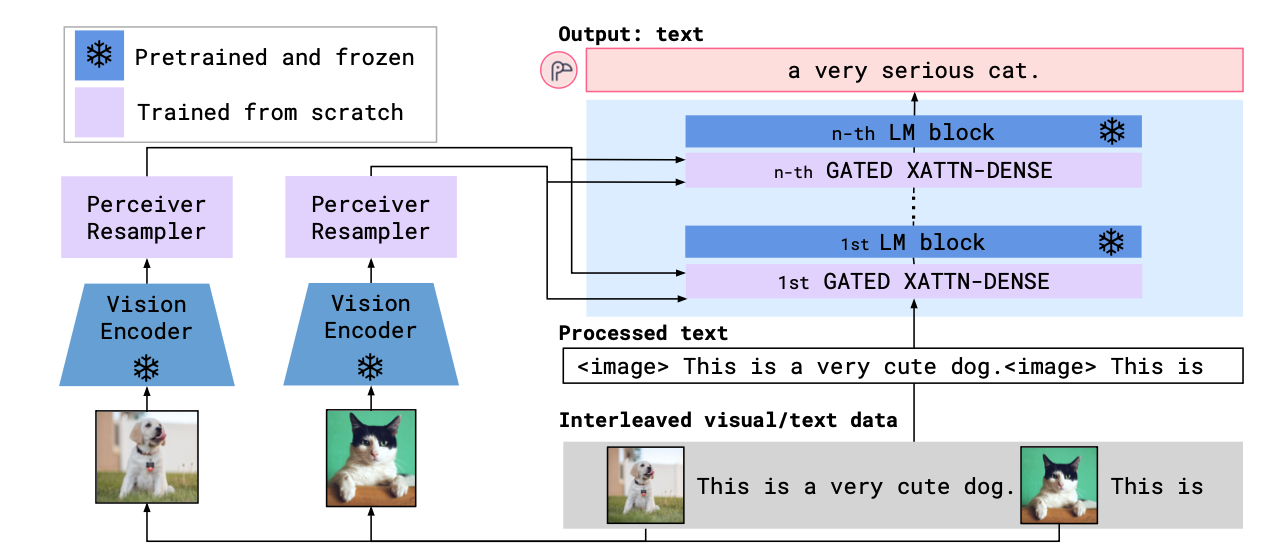
Flamingo는 이미지/비디오와 텍스트가 교차된 시퀀스를 입력으로 받아 Autoregressive text generation을 수행하는 모델이다.
- (frozen) Vision encoder가 픽셀 이미지를 고차원 feature으로 변환
- Perceiver Resampler가 이 가변 길이의 visoin feature들을 고정 길이의 token으로 요약
- (frozen) LLM 내부에 cross-attention layer들을 삽입
- 이미지/비디오로부터 얻은 정보를 텍스트 생성에 활용
Perceiver Resampler와 Cross-Attention 모듈만 학습
Flamingo는 삽입된 이미지 및 비디오 $𝑥$에 조건부로 텍스트 $𝑦$의 확률을 다음과 같이 모델링한다.
\[p(y|x) = \prod^{L}_{\ell = 1} p(y_\ell | y_{<\ell}, x_{ \leq \ell})\]- $y_\ell$: 입력 text의 $\ell$ 번째 token
- $y<\ell$: 이전 text token 집합
- $x \leq \ell$: 이전에 위치한 이미지/비디오 집합
이를 통해 원래 사전학습 모델들이 지닌 지식과 능력을 최대한 보존하면서 멀티모달 처리를 가능하게한다.
Visual processing
Vision Encoder : NFNet-F6
Vision Encoder는 Normalizer-Free ResNet (NFNet) 계열의 F6 모델을 사용한다.
ImageNet 등에서 높은 성능을 보이는 강력한 이미지 feauter extractor
NFNet-F6 Encoder는 Flamingo 학습 이전에 별도로 대규모 Image-text pair 데이터에 대해 contrastive learning으로 pretrain되었으며 freeze하여 사용한다.
CLIP과 유사하며, 학습 과정에서 Image/Video의 feature만 제공
별도 학습 과정에서 BERT 인코더를 사용하여 대조학습함 → “문장 전체 → 하나의 고정 길이 벡터”를 잘 뽑아내려면 양방향 컨텍스트가 중요
Vision 인코더를 contrastive 방식으로 튜닝하여 좋은 Vision 임베딩을 얻는 것”과 “얻은 Vision 임베딩을 나중에 Chinchilla 기반 생성 모델에 주입하는 것”을 완전히 분리
Flamingo는 NFNet-F6의 마지막 layer 출력을 feature map으로 받아들인다.
구체적으로,
- 이미지
- NFNet으로 $H×W$ 크기의 2D feature map으로 변환, flatten → 하나의 1D token 시퀀스
- 동영상
- 1초당 1 frame을 샘플링하여 각각 NFNet으로 인코딩
- 시간 축까지 포함한 3D feature map을 얻고 여기에 학습된 time embedding을 더해준다.
- 모든 frame의 공간-시간 feautre들을 flatten하여 1D 시퀀스로 변환
이렇게 나온 1D 시퀀스는 Perceiver Resampler에 전달된다.
Perceiver Resampler
Vision Encoder가 출력하는 가변 길이의 방대한 feature 시퀀스를 일정한 길이로 요약하는 역할을 한다.
- Input : NFNet에서 추출된 visual feature
- Output: 64개의 visual token
이미지/동영상 크기가 어떻든, Perceiver Resampler는 64개의 token으로 그 정보를 압축해서 언어 모델 쪽으로 전달한다.
LM과 visual feature를 cross-attention할 때 비용이 크게 절감
Perceiver Resampler의 구조는 Transformer encoder의 한 블록 정도로 볼 수 있다.
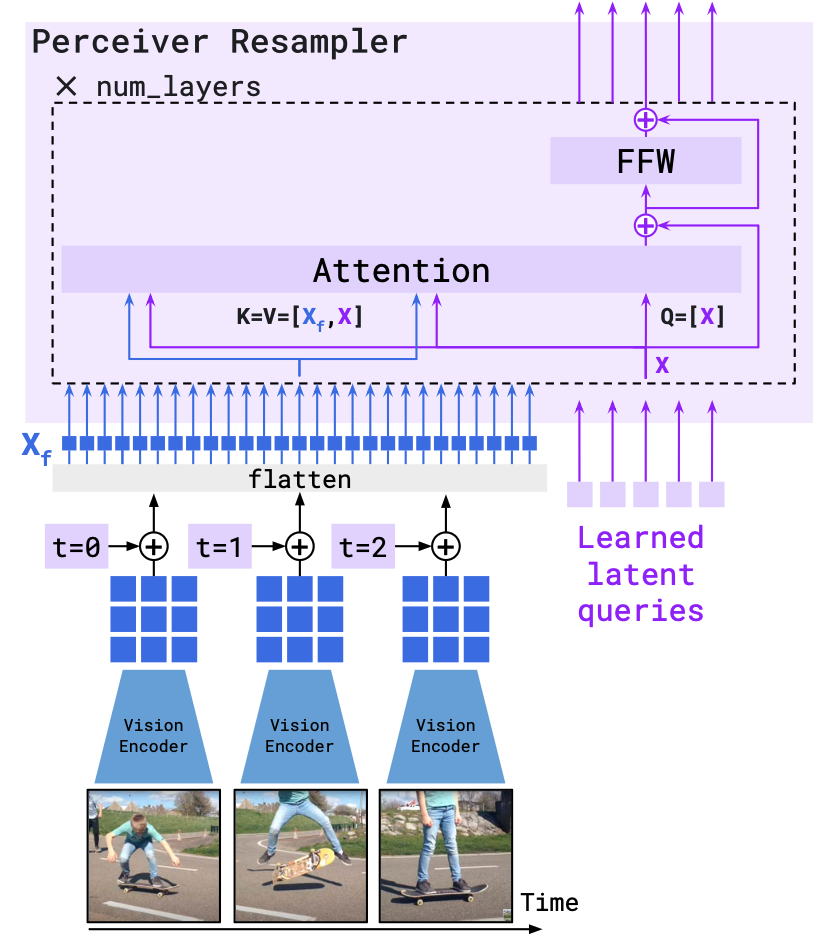
64개의 learnable한 latent query 벡터를 준비하고, 이를 visual feature들에 대해 cross-attention 시키는 방식이다 .
쉽게 말해, 수백 개에 이르는 Image feautre 중 가장 중요한 정보만 뽑아 64개 벡터에 담는 역할
저자들은 이렇게 Resampler 전용 모듈을 사용하는 것이 단순히 flattened feature를 바로 줄이기 위한 MLP나 Transformer를 쓰는 것보다 성능이 우수했다고 한다
결과적으로, Resampler를 통해 압축된 64개의 token은 이후 언어 모델이 참고할 시각적 context로 활용된다.
Conditioning frozen LM on visual representations
Flamingo의 언어 이해 및 생성 능력은 DeepMind가 개발한 LLM인 Chinchilla로부터 나온다.
Flamingo에서는 Chinchilla 모델을 크기별로 3가지 사용한다:
- Flamingo-3B
- Flamingo-9B
- Flamingo-80B
LM 역시 학습 시 frozen되어, 원래의 언어 지식을 그대로 간직한 채 사용된다.
대신 Flamingo는 이 LM 내부에 시각 정보를 끼워넣을 수 있는 새로운 layer들을 추가한다.
Gated XATTN-Dense layers
Flamingo에서는 learnable한 cross-attention 블록들을 pretrained LM의 중간에 삽입하여, LM이 생성 과정에서 Visual token에 주의를 기울이도록 한다.
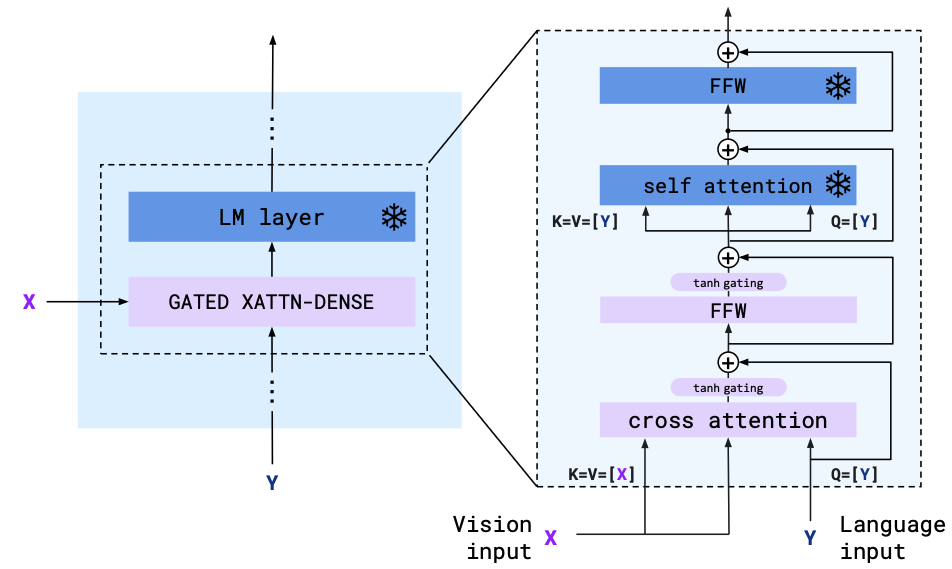
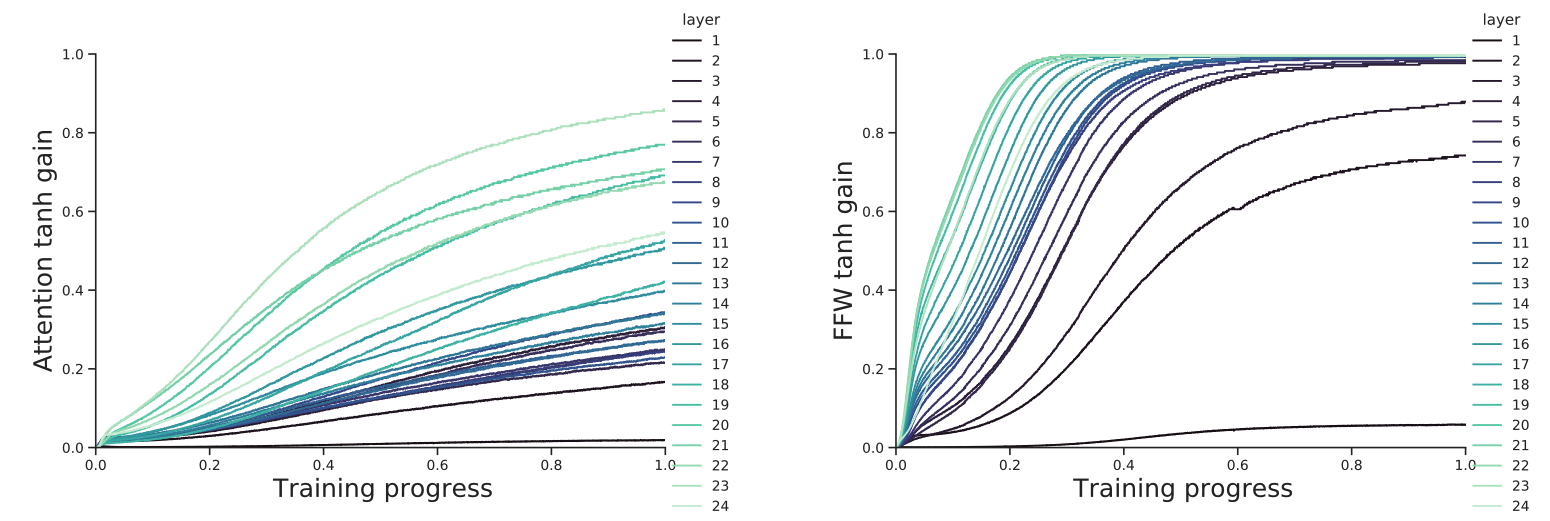
위 그림과 같이 Cross Attention layer와 feed-forward layer로 구성되며, tanh 게이트가 곱해진다.
- Cross Attention layer
- Query : LM의 중간 hidden state
- Key, Value : 64개 visual token
- 언어 모델은 현재까지 생성된 텍스트 맥락에 맞추어 시각 정보에 질의(query)를 보내 필요한 내용을 얻어올 수 있다.
- Feed-Forward(Dense) layer :시각 정보를 반영한 표현을 각 위치별로 변환
이렇게 추가된 레이어들의 출력은 tanh 게이트를 통해 스케일이 조정된 후, 원래 언어 모델의 레이어 출력과 합쳐진다.
gate에서는 학습 가능한 스칼라 $\alpha$를 통해 $\tanh(\alpha)$만큼 스케일을 조정한다.
처음엔 $\alpha=0$으로 설정하여 $\tanh(0)=0$, 즉 학습 초반에는 새로운 레이어가 언어 모델에 영향을 주지 않는다.
시간이 지남에 따라 $\alpha$가 학습되면서 gate가 열려 시각 정보가 점진적으로 통합된다.
위 이미지는 tahn 게이트의 값이 학습 과정에서 어떻게 변하는지 나타낸 그래프이다.
Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def gated_xattn_dense(y, x, alpha_xattn, alpha_dense):
# y: 언어 모델의 중간 히든(queries)
# x: Vision token(key, value) – Perceiver Resampler 출력
# alpha_xattn, alpha_dense: 학습 가능한 스칼라(게이트 파라미터)
# 1) Cross-Attention with tanh gating
y = y + tanh(alpha_xattn) * Attention(q=y, kv=x)
# 2) Feed-Forward Dense layer with tanh gating
y = y + tanh(alpha_dense) * FeedForward(y)
# 3) 기존 언어 모델의 Self-Attention + FFN (동결된 파라미터)
y = y + FrozenSelfAttention(q=y, kv=y)
y = y + FrozenFeedForward(y)
return y
- Attention(
q=y, kv=x): 쿼리y가 Vision tokenx에 cross-attention을 수행 - FeedForward(
y): Transformer의 일반적인 position-wise FFN(Dense) - 뒤의 FrozenSelfAttention과 FrozenFeedForward는 사전학습된 언어 모델 파라미터를 그대로 사용하며, 학습되지 않은 채 frozen되어 있다 .
효율성과 표현력 사이 trade-off를 맞추기 위해 몇 개 layer마다 한 번씩 삽입하는 전략을 택한다.
이렇게 함으로써 파라미터 수와 계산량을 늘리지 않으면서도 시각 정보가 충분히 언어 모델에 주입된다.
Multi-visual input support
per-image attention masking을 통해 하나의 대화 내에 여러 이미지/비디오가 interleaved된 경우도 자연스럽게 처리할 수 있게 된다.
{이미지 A - 질문 X - 이미지 B - 질문 Y} 처럼 텍스트와 이미지가 번갈아 여러 개 등장해도 일관성 있게 이해하고 대답할 수 있다.
Cross-Attention 단계에서, 각 text token이 볼 수 있는 Vision token에 제한을 거는 것이다.
구체적으로 Flamingo는 특정 위치의 텍스트 token이 오직 직전에 등장한 한 장의 이미지로부터 나온 Vision token들만 참조하도록 어텐션 마스크를 적용한다 .
예를 들어 대화 프롬프트가 <Image1><Question1><Image2><Question2> 라면, <Question2>에 대한 생성 시에는 Image2 token에만 attention을 적용
이렇게 하면 각 질문에 해당하는 이미지 정보만 집중하여 답을 생성하게 되고, 여러 이미지가 있는 경우에도 문맥이 섞여 혼동되는 것을 막을 수 있다.
LM 내부의 self-attention은 모든 token를 활용하므로 간접적으로 다른 token들과 이어질 수 있지만, 직접적인 cross-attention 연결을 한 이미지씩으로 제한함으로써, Flamingo는 훈련 시 사용된 이미지 개수보다 더 많은 이미지가 들어와도 잘 대응할 수 있게 되었다 .
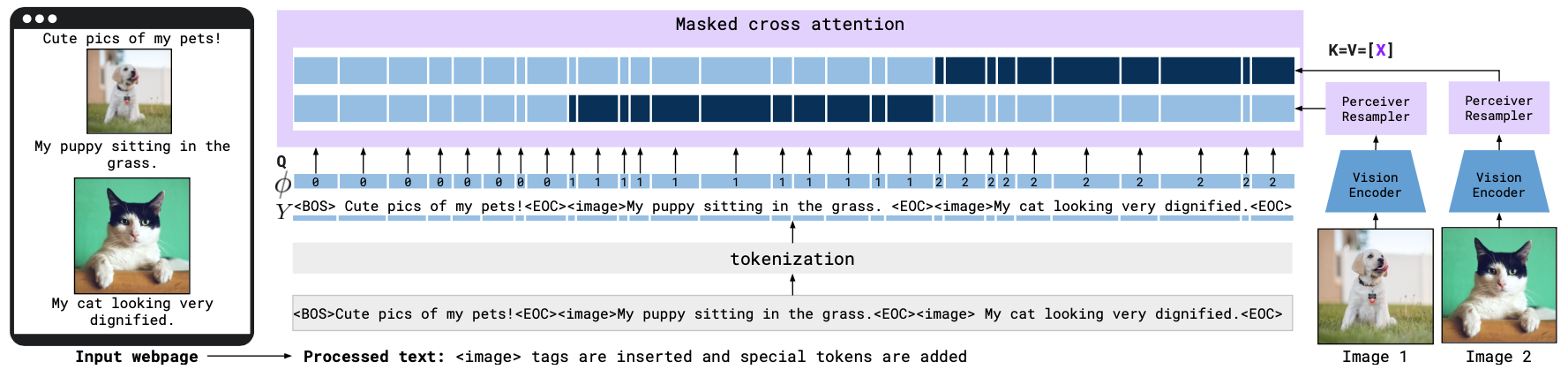
이 덕분에 학습 때 한 시퀀스당 최대 5장의 이미지만 사용했지만, Test 시에는 최대 32개의 Image-Text pair까지 다룰 수 있었다.
참고로, 저자들은 대안 실험으로 “텍스트가 모든 이전 이미지들에 cross-attend하도록” 해본 경우 오히려 성능이 떨어졌다고 보고한다 . 이는 한꺼번에 여러 이미지를 모두 참고하면 모델이 어느 정보를 어디에 써야 할지 혼란스러워하기 때문으로 추정된다.
결국 이미지-인과적(image-causal) 어텐션 마스킹을 적용한 현재의 방식이 가장 효과적이었다고 한다.
Training on a mixture of vision and language datasets
Flamingo의 사전학습(Pretraining)에는 대규모 unlabeled multi-modal 웹 데이터가 활용되었다.
데이터는 3가지로 구성되어있다.
- M3W (MultiModal MassiveWeb)
- 웹페이지로부터 추출한 이미지-텍스트 혼합 시퀀스 데이터셋이다.
- 각 페이지에서 이미지가 등장한 자리에 <image> token을 삽입하고, 문서의 섹션이 끝날 때 <EOC> token을 넣는 식으로 시퀀스화
- Image-Text Pairs
- ALIGN 데이터셋 + 추가로 수집한 LTIP (Long Text Image Pairs) 데이터셋
- Flamingo 입력 형식에 맞추기 위해 캡션 앞에는 <image> token을, 끝에는 <EOC> token을 붙여 구성
- Video-Text Pairs
- 자체 수집한 동영상 설명 데이터
- 평균 22초 분량 동영상 - 한 문장짜리 설명
- 마찬가지로 <image> (또는 동영상 프레임의 placeholder)와 <EOC> token을 활용해 입력 시퀀스를 구성
이 세 가지 데이터를 섞어 모델을 학습할 때, 단순히 한 데이터셋씩 번갈아 훈련하는 것보다 weight를 주며 batch에 섞어 gradient를 누적하는 방식이 더 효과적이었다고 한다.
Training strategy
Flamingo 모델은 위 거대한 웹 멀티모달 corpora에서 다음 단어 예측 task를 수행하며 사전학습되었다.
즉, 주어진 시퀀스에서 한 token씩 autoregressive하게 예측하는 방식으로, 이미지/텍스트 혼합 문맥에서 텍스트 생성 확률 $P(\text{텍스트} \mid \text{이전 텍스트+이미지})$ 을 최대화하도록 훈련되었다 . 훈련 결과, Flamingo는 텍스트와 이미지가 섞인 긴 시퀀스를 보고도 다음에 올 단어를 자연스럽게 만들어내는 능력을 획득했다. 이러한 능력을 바탕으로, 모델이 학습에 사용되지 않은 새로운 벤치마크에 대해 few-shot 설정으로 빠르게 적응할 수 있음을 논문에서 실험으로 증명하였다.
Loss
- 세 데이터셋 $\mathcal{D}_m $ 각각에 대한 negative log-likelihood 손실을 가중치$\lambda_m$로 합산:
- 여기서 $x$는 Vision 입력(이미지/비디오), $y$는 텍스트 token
- 가중치 튜닝을 통해, 모델이 세 소스 모두에서 고른 성능을 내도록 균형을 맞춘다.
Gradient 누적
- 각 step마다 모든 데이터셋에 걸쳐 gradient를 누적(accumulate)하고 한 번에 업데이트
Task adaption with few-shot in-context learning
사전학습을 마친 Flamingo는, task별 fine-tuning 없이 “프롬프트에 몇 개의 예시만 보여 줌으로써” 새로운 task에 즉시 적용할 수 있다.
In-context learning
Prompt 구성

- Support set: 해당 task의 ${(x_1,y_1),\dots,(x_K,y_K)}$ 예시 $K$개(보통 $K=4,8,16,32$).
- $x$ : Image or Video
- Query: “새로운 입력” $x_{q}$ (이미지·영상)
- 최종 입력 시퀀스
예상 응답 앞에 “Output:”을 추가
시각적 QA task에는
“Question: {question} Answer: {answer}”형식으로 프롬프트를 구성
Decoding method
Open-ended task(캡션·자유 응답): Beam Search로 텍스트 생성
Beam Search
생성 모델에서 가장 확률이 높은 출력 시퀀스를 찾기 위한 탐색 알고리즘이다. 후보를 무작위 하나만 뽑는 greedy search에 비해, 다양한 가능성을 고려해 최종 문장을 생성하므로 품질 좋은 텍스트를 얻기 쉽다.
초기화
- 빈 시퀀스 []를 유일한 후보로 두고, 그 점수(log-prob) $s=0$
- 빔 크기(beam width) $B$를 미리 정함 (예: $B=5$ 또는 $B=10$)
반복(매 타임스텝 t)
각 후보 시퀀스 $y_{1:t-1}$에 대해, 모델이 생성할 수 있는 다음 token $v$들과 그 로그 확률 $\log p(v\mid y_{1:t-1},\,x)$을 계산
모든 후보 × 모든 token 쌍에 대해, 확장된 시퀀스와 누적 점수를 구함:
$\bigl(y_{1:t-1},\,v\bigr)\quad,\quad s_{\text{new}} = s_{\text{old}} + \log p(v \mid y_{1:t-1},\,x)$
이들 중 가장 점수가 높은 상위 B개 후보만을 다음 단계의 후보로 유지
이 과정에서 “종결 token”(</s>)이 나온 후보는 별도에 저장해 놓을 수 있음
종료 조건
- 모든 후보가 종결 token을 뽑았거나, 미리 정한 최대 길이에 도달하면 종료
- 저장해둔 “완성된” 후보들 중 가장 높은 점수를 가진 시퀀스를 최종 출력
Closed-ended task(선다형): 가능한 모든 정답 후보를 질의 이미지 뒤에 각각 하나씩 붙여 log-likelihood를 계산해 가장 높은 옵션 선택
Zero-shot Generalization
논문에서는 Zero-shot 성능을 측정할 때, 예시 없이 텍스트 예시 두 개만 주고(이미지는 제거) prompt를 다음과 같이 구성한다.
1 2 3 4
<BOS> Output: This is a cat wearing sunglasses.<EOC> Output: Three elephants walking in the savanna.<EOC> <image> Output:
1 개 예시만 보여 주면 모델이 과도하게 편향되므로, 2 개 예시를 사용하며, 그 이상은 성능 향상이 미미해 두 개로 고정했다.
Retrieval-based In-Context Example Selection (RICES)
대규모 예시 집합에서는 프롬프트 길이 제한 때문에 모두 넣기 어렵고, 시퀀스 길이가 너무 길면 일반화 성능이 저하된다.
이럴 때 An Empirical Study of GPT-3 for Few-Shot Knowledge-Based VQA의 RICES 방식을 따라,
- 질의 이미지와 visual feature 벡터를 비교해 가장 유사한 상위 $N$개의 예시만 선택
- 유사도 순, 즉 가장 비슷한 예시가 Query 직전에 오도록 프롬프트를 구성한다.
이렇게 하면 길이를 제한하면서도 프롬프트 품질을 높여 성능을 개선할 수 있다.
Experiments
Flamingo 모델이 얼마나 다양한 새로운 Vision-language task에 빠르게 적응(fast adaptation)하는지 평가한다. 이를 위해 총 16개의 대표 multimodal image/video - language benchmark를 선정했고, 이들 중 5개는 모델 설계·하이퍼파라미터 튜닝(DEV set) 과정에서, 나머지 11개는 오직 최종 평가(held-out) 용도로만 사용했다.
DEV 벤치마크(모델 개발에 사용)
- COCO Captions, OK-VQA, VQAv2, MSVDQA, VATEX
Held-out 벤치마크(최종 성능 측정)
- Flickr30k, YouCook2 VideoQA, Visual Dialogue, Hateful Memes, TextVQA, STAR, NextQA, RareAct 등 11개
평가 방식 통일
Few-shot in-context learning으로만 모델을 적용
Open-ended는 Beam Search(beam size=3)
Closed-ended는 log-likelihood scoring 방식으로 정답 선택
하이퍼파라미터, promt구성, beam size 등은 전 벤치마크에 걸쳐 고정해 평가 편향을 최소화
Ablation study
- 부록 B.2: Flamingo 모델의 fine-tuning 성능(VQAv2, VATEX, VizWiz 등 9개 task)
- 부록 B.2: ImageNet·Kinetics700 분류 성능, contrastive 비전 인코더 성능
- 부록 C: 질의응답·캡션·대화 등 다양한 정성적 예시
Few-shot learning
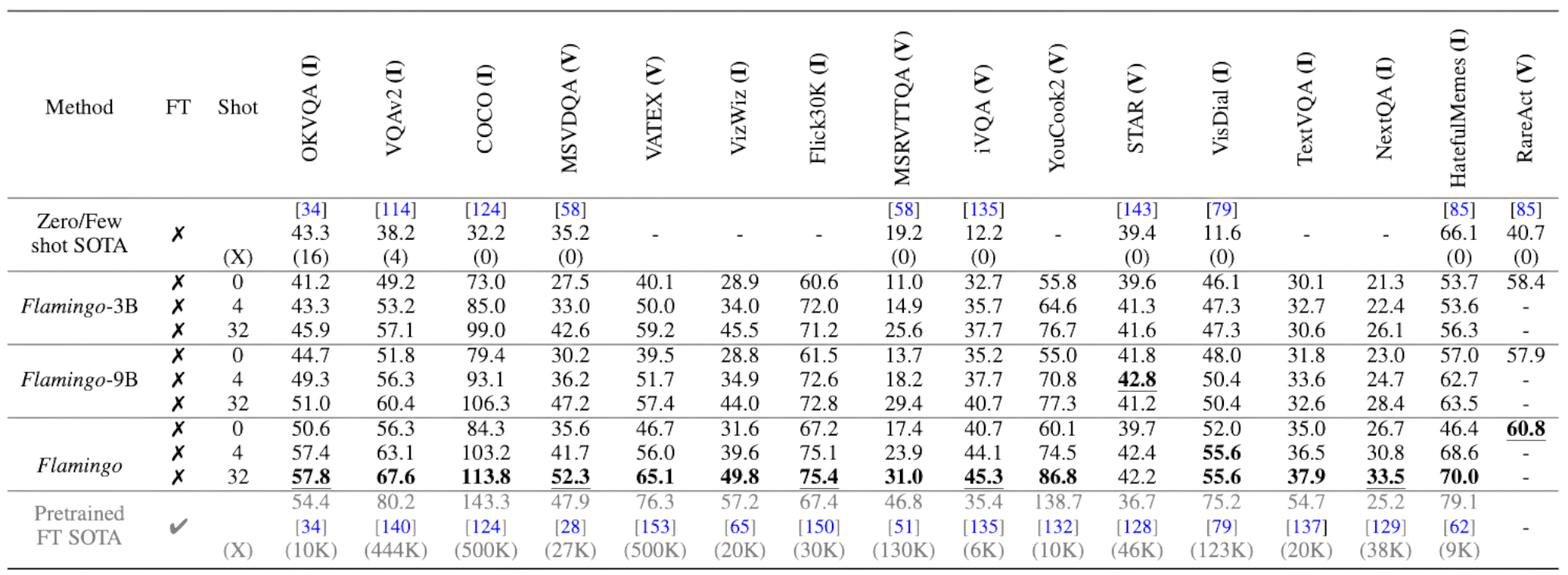
Flamingo(80B) 모델은 16개 벤치마크 모두에서,
- 기존 Zero/Few-shot SOTA 보다 좋은 성능
6개 task(OK-VQA, MSVDQA 등)에서는 32-shot으로 fine-tuning SOTA 능가
모델 크기(3B→9B→80B)와 샷 수(0→4→32)를 늘릴수록 성능이 일관되게 향상
Fine-tuning
Flamingo를 pretrained VLM으로 여기고 labeling된 fine-tuning하는 방법으로 task에 적용하기도 한다.
- 모델 구조
- Chinchilla와 Flamingo의 cross-attention 및 Perceiver Resampler 모듈까지 모두 미세조정
- NFNet-F6는 “더 높은 해상도 입력”을 받도록 unfreeze하여 학습

fine-tuning 후 Flamingo는 Few-shot 결과를 크게 뛰어넘어, 기존의 fine-tuning SOTA와 비교했을 때 VQAv2, VATEX, VizWiz, MSRVTTQA, Hateful Memes 5개 task에서 새 SOTA를 달성했다.
이는 Flamingo가 “단일 가중치”로 few-shot 및 fine-tuning 두 가지 모두에 대응 가능하다는 것을 입증한다.
Ablation Studies
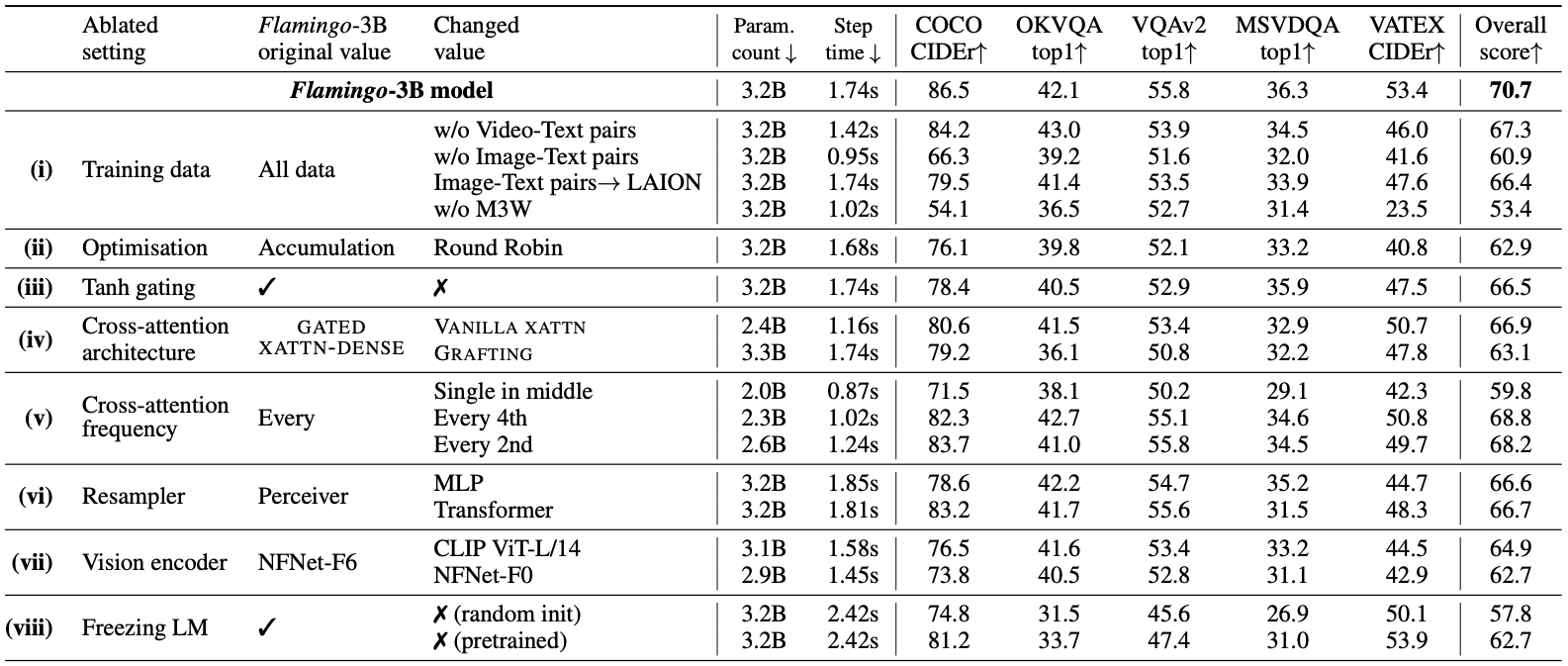
Training data
- 원본: M3W(크롤링) + Image–Text pair (ALIGN+LTIP) + Video–Text pair(VTP)
- w/o M3W : 전체 17.3% 하락
- w/o Image-text pair : 전체 9.8% 하락
- w/o Video-text pair : video task 성능 하락
- Image-text pair → LAION dataset으로 교체 : 4.3% 하락
- 원본: M3W(크롤링) + Image–Text pair (ALIGN+LTIP) + Video–Text pair(VTP)
Optimisation
- 원본: 모든 데이터셋의 그래디언트를 한 스텝에 누적(accumulate)
- 비교: “round-robin” 사용 시 전체 점수 70.7% → 62.9%
Tanh gating
원본: gate $\tanh(α)$ 의 $α$를 0으로 초기화하고 XATTN-Dense 출력을 스케일
비교: 게이팅 없이 : 전체 점수 70.7 → 66.5 (–4.2)
게이팅이 없으면 초기화 시 pretrained LM 출력과 일치하지 않아 훈련 불안정 초래 .
Cross-attention architecture
- 원본: GATED XATTN-DENSE
- 비교:
- VANILLA XATTN (기존 Transformer cross-attn만 삽입) : 70.7 → 66.9
- GRAFTING (frozen LM 위에 cross+self-attn 층 덧붙임) : 70.7 → 63.1
Cross-attention frequency
- 원본: GATED XATTN-DENSE를 매 층마다 삽입 (cost 증가)
- 비교:
- 매 2번째 층 : 70.7 → 68.2 (–2.5%)
- 매 4번째 층 : 70.7 → 68.8 (–1.9%)
- 한 번(중간) : 70.7 → 59.8 (–15.4%)
- 절충: trade-off를 고려해서 Flamingo-9B는 4층마다, Flamingo-80B는 7층마다 삽입
Perceiver Resampler
- 원본: Perceiver Resampler (64개 시각 토큰 출력)
- 비교:
- Transformer (동일 파라미터) : 70.7 → 66.7
- 단일 MLP : 70.7 → 66.6
Vision encoder
- 원본: NFNet-F6 (contrastive pre-trained)
- 비교:
- CLIP ViT-L/14 : 70.7 → 64.9 (–5.8)
- NFNet-F0 : 70.7 → 62.7 (–8.0)
- 결론: 강력한 contrastive pretrained NFNet-F6가 최상 .
Freezing LM
- 원본: Chinchilla LM 층 모두 freeze
- 비교:
- LM를 처음부터 학습(random init) : 70.7 → 57.8 (–12.9)
- LM를 pretrain된 상태로 fine-tuning(unfreeze) : 70.7 → 62.7 (–8.0)
CLIP vs NFNet-F6
CLIP ViT-L/14도 contrastive learning으로 학습된 강력한 비전 인코더지만, Flamingo에서는 NFNet-F6가 훨씬 더 좋은 성능을 보임
- 해상도와 아키텍처 설계의 차이
| 항목 | CLIP ViT-L/14 | NFNet-F6 |
|---|---|---|
| 기본 구조 | Vision Transformer (ViT-L/14) | Convolutional Feedforward Network (ResNet 계열) |
| 입력 해상도 | 보통 224×224 | 288×288로 학습 (Flamingo에서는 480×480까지 사용) |
| receptive field | 제한적 (patch 14×14 기준) | 더 넓고 dense (CNN 특성) |
| inductive bias | 거의 없음 (transformer) | 있음 (CNN: 지역성, 계층적 표현) |
- CLIP
- self-attention 기반이기 때문에 지역 패턴, low-level visual feature를 학습하기 어려움
NFNet
- 이미지의 local 구조, 계층적 feauture 추출에 매우 강함
→ Flamingo처럼 다양한 종류의 Vision-language task를 처리해야 할 경우, 일반적인 인식 능력이 뛰어난 NFNet이 더 효과적
학습 데이터와 스케일 차이
NFNet-F6
ALIGN + LTIP 데이터
ALIGN: 1.8B image-text pair (Google 내부 데이터)
LTIP: 4B text image pair (web-scale large-scale text–image pairs)
학습 스텝: 1.2M update steps, batch size 16,384, TPUv4 × 512 사용
CLIP
LAION-400M 수준의 웹 데이터
상대적으로 학습 규모가 작고, fine-grained noise도 더 많음
→ Flamingo의 NFNet은 더 양질의 데이터로 훨씬 더 오랫동안 학습되었기 때문에, CLIP보다 시각 표현이 훨씬 정교
Flamingo 아키텍처와의 적합성
Flamingo에서는 비전 인코더의 출력이 Perceiver Resampler를 통해 64개의 latent token으로 압축되어 언어 모델에 연결
CLIP ViT-L/14는 patch-wise token 출력이라 비선형 구조와 잘 맞지 않을 수 있음
반면 NFNet은 convolutional feature map 형태로 출력되기 때문에
→ Perceiver 구조와의 토큰 추출, 위치 독립성, 정보 압축에 훨씬 유리
Conclusion
Flamingo는 LLM의 few-shot learning 능력을 Image/Video 도메인으로 확장함으로써, 주어진 몇 개의 예시만으로 새로운 Vision-language task들을 신속히 학습할 수 있음을 입증했다.
Flamingo의 아키텍처는 사전학습된 Vision backbone과 Language model을 효과적으로 연결하여, 두 모델이 축적한 지식을 최대한 활용한다.
그 결과, 대규모 웹 데이터로 학습된 Flamingo는 Captioning, VQA, 영상 질문응답, 대화형 응답 등 다양한 task에서 SOTA 수준의 성능을 달성했다.
특히 Inference 시 추가 학습 없이도 높은 성능을 보였다는 점에서, 향후 Multimodal AI의 개발 및 응용 패러다임에 변화를 불러올 수 있다. 이전까지는 각 task마다 개별 모델을 훈련해야 했다면, 이제는 Flamingo 같은 범용 모델에 몇 가지 예시를 주는 것만으로 해결하는 방향으로 나아갈 가능성을 시사한 것이다.
Flamingo는 Few-Shot Multimodal Learning의 가능성을 열었으며, Multimodal AI가 어떻게 진화할지에 대한 하나의 방향성을 제공한다.
Limitations
LM의 약점을 계승 : hallucination and ungrounded guesses
- 이미지 내용과 무관하지만 텍스트 맥락상 그럴듯해 보이는 답변을 생성하는 현상
- 언어 모델의 사전지식에 과도하게 의존하기 때문
- train 때 본 적 없는 길이의 입력 시퀀스에 대해서는 일반화안됨
- 너무 많은 예시를 한 번에 넣으면 성능이 하락
높은 계산 비용
- Flamingo-80B에 NFNet-F6과 Resampler까지 결합되어 연산량과 메모리 요구량이 막대
- TPUv4 칩 512개
- 총 1.2 million update steps
- 추론 시 수십 샷의 예시를 입력하면 token 수가 길어져 계산 cost가 선형적으로 증가
- few-shot learning은 별도 fine-tuning이 필요 없다는 장점이 있는 대신 Inference cost 증가 .
- Flamingo-80B에 NFNet-F6과 Resampler까지 결합되어 연산량과 메모리 요구량이 막대
Prompt sensitive
- LLM처럼 프롬프트에 제공하는 예시의 구성과 표현에 민감
- 예를 들어, 동일한 4개의 예시라도 배열 순서나 설명 어투에 따라 모델 출력이 달라질 수 있다.
- few-shot에서 shot 수를 늘릴수록 어느 정도까지는 성능이 향상되지만, 일정 수준(수십 개 이상)을 넘어서면 오히려 모델이 혼란을 일으키거나 성능 개선이 정체되는 현상 발생
Classification task
Classification task에서는 최첨단 Contrastive model(CLIP)보다 성능 하락
ImageNet few-shot에서 CLIP 등 Image-text embedding 기반 classification 모델보다 하락
Flamingo는 text generation 확률을 최대화하도록 학습되었기 때문
Flamingo는 다양한 task를 폭넓게 다루기 위해 특화된 최적화는 포기