[Paper Review] GAN
[논문 리뷰] Generative Adversarial Nets
본 포스트는 GAN의 직관적인 개념을 다루는 것이 아닌, GAN이 탄생한 논문을 리뷰하며 어떻게 작동하는지를 알아보는 post이다.
Introduction
기존의 생성모델들에서는 Maximum likelihood estimation(최대 우도 추정)에서 발생하는 여러 불가능한 확률 계산을 근사화해야하는 어려움이 있었다. 이러한 문제를 우회하며 좋은 품질의 컨텐츠를 생성하기 위해 적대적 생성 네트워크인 GAN이라는 접근 방식을 제안한다.
Adversarial Nets
Adversarial 모델링을 진행하기 위해 두개의 다층 퍼셉트론 모델을 정의한다. 하나는 Generator(생성자 ; $G$), 다른 하나는 Discriminator(판별자 ; $D$)이다.
데이터 $x$에 대한 $G$의 분포 $p_g$를 학습하기 위해서 노이즈로 이루어진 변수 $p_z (z)$를 정의한다. 그런 다음, 데이터 공간과의 mapping을 $G(z;\theta_g)$로 표현한다.
또다른 다층 퍼셉트론 모델 $D$는 $D(x;\theta_d)$로 표현되며 $D(x)$는 $G$의 분포인 $p_g$가 아닌 데이터에서 $x$가 나올 확률을 출력한다. 즉, $G$가 만든 것인지, 실제 데이터에서 나온 것인지 구분하는 역할이다. $G$가 생성한 샘플이 실제와 유사할수록, $D$의 값은 커진다.
GAN은 두 모델을 다음과 같이 동시에 훈련한다.
- $D$는 실제 데이터와 $G$가 생성한 sample을 정확히 분류하는 방향으로 훈련.
- $G$는 $log(1-D(G(z)))$를 최소화하는 방향으로 훈련. 즉, 생성한 샘플 $G(z)$를 $D$가 분류하였을 때, $D$의 값이 커지는 방향으로 훈련한다.
이는 다음과 같은 Value function을 따르는 $minmax$ 게임을 진행한다. (Eq 1.)
\[\underset{G}{min}\underset{D}{max}\;V(D, G) = \mathbb{E}_{x \sim p_{data} (x)}[log\;D(x)] + \mathbb{E}_{z\sim p_z(z)}[log(1-D(G(z)))]\]$\mathbb{E}{x \sim p_{data}(x)}$의 의미는 Noise 분포인 $p_{data}(x)$를 따르는 $x$의 기댓값을 의미한다.
Adversarial Network를 학습하는 과정에서 $D$를 완벽하게 optimizing하는 것을 방지한다. 같은 step이 진행되었을 때 $D$의 성능이 $G$에 비하여 월등히 좋아지기 때문에 $G$의 학습이 원활하게 이루어지지 않기 때문이다. 이를 방지하기 위해, $D$의 Optimizing하는 $k$ 단계와 $G$를 Optimizing하는 하나의 단계를 묶어서 진행한다.
이는 SML/PCD 전략과 유사한데, Markov chain에서 Burn in 문제를 피하기 위해 Markov chain의 sample을 다음 스텝까지 유지하는 전략이다.
Markov chain이란 Markov 성질을 가진 이산 시간 확률 과정이며, Markov 성질은 미래 상태의 조건부 확률 분포는 과거 상태와는 무관하게 현재 상태에 의해서만 결정된다는 것이다. 즉 어떠한 time step $t$가 있다면 다음 time step인 $t+1$에는 1 ~ $t-1$에는 상관없이 현재 $t$에 대해서만 결정된다는 것이다.
Burn in 이란 Markov chain 특정 시점까지의 초기 상태 또는 관찰들을 무시하는 과정을 말한다. 이 과정은 마르코프 체인이 정상 분포에 수렴하는 데 필요한 시간을 나타내며 이 과정동안 생성된 샘플들은 폐기된다.
SML(Stochastic Maximum Likelihood)는 확률적 최대우도 추정법이라고 불린다. SML은 기본적으로 데이터의 우도를 최대화하는 모델의 파라미터 값을 찾는 기법이다.
PCD(Persistent Contrastive Divergence)는 특정한 유형의 확률적 네트워크 모델을 학습하는 데 사용되는 알고리즘이다.
SML과 PCD는 따로 공부하여 post를 추후 올릴 예정이다..
실제로 식 (1)은 초기 학습단계에서 $G$가 학습하기 충분한 gradient를 제공하지 못해 학습이 잘 이루어지지 않는다. $G$의 성능이 낮아 생성된 샘플을 $D$는 확신을 가지고 분류할 수 있으며, 이 과정이 반복되면 $G$가 minimize해야하는 $log(1-D(G(z)))$ 식은 포화상태에 이르러 gradient가 소실되는 문제가 발생한다. 이에 대한 대안으로 $log(1-D(G(z)))$를 minimize하는 대신, $log\;D(G(z))$를 maximize 하는 방향으로 목적함수를 개선하여 학습 초기에 더 강한 gradient를 제공한다.
Gradient의 변화가 있는 이유는 $log(1-D(G(z)))$를 minimize 할때 $G$의 성능이 안좋아 $D(G(z))$의 값이 0에 가까워지고, 결국 $log(1)$, 즉 0에 가까워져 Gradient 값이 완만하여 학습 속도가 많이 낮아지기 때문이다. $log\;D(G(z))$를 maximize할 시 gradient값이 가파르게 되어 학습이 빠르게 진행될 수 있다.
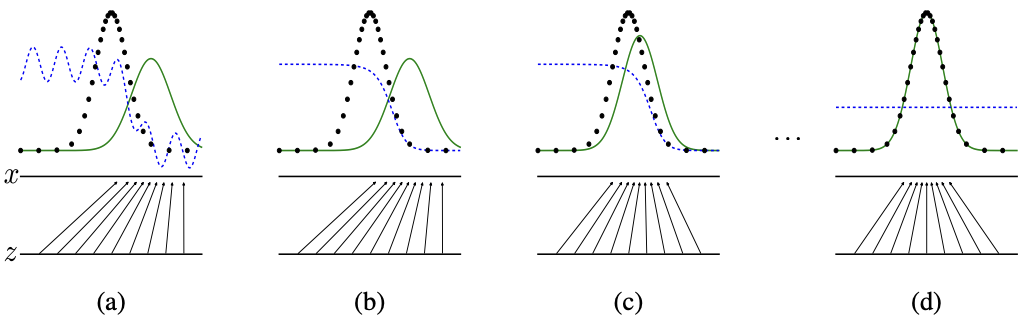
Figure 1: GAN은 generative 분포와 data generating 분포를 구별하기 위해 discriminative 분포를 동시에 학습하며 업데이트한다. 아래 수평선은 $z$가 sampling되는 영역(uniform)이며 위 수평선은 $x$ domain의 일부이다. 화살표는 $x = G(z)$ mapping이 변환된 sample에 어떻게 non-uniform 분포인 $p_g$가 적용되는지를 나타낸다.
a. $p_g$는 $p_{data}$와 유사, $D$는 부분적으로 정확한 Classifier임
→ 학습 초기 단계 : $D$(파란선)이 $G$가 생성한 분포(초록선)에서는 낮은 값을 출력
b. $D$는 학습 data의 sample을 분류하게끔 학습, $D^*(x) = \frac{p_{data}(x)}{p_{data}(x) + p_g(x)}$ 로 수렴
→ $D$ Train 후 : (a)보다는 안정되었으며 여전히 $G$가 생성한 분포는 낮은 값 출력
c. $G$를 업데이트하고 , G는$G(z)$($G$가 생성한 sample)이 data로 분류되도록 $D$의 gradient를 유도
→ $G$ Train 후 : $G$가 생성한 분포(초록선)가 학습 데이터 분포(검은선)과 유사해짐
d. 여러 훈련 step을 거친 후, $G$와 $D$는 $p_g = p_{data}$, 때문에 성능이 더 나아지지 않는 정도에 도달 → $D$는 더이상 두 분포를 구별할 수 없게 된다. ($D(x) = \frac{1}{2}$)
→ 여러 step을 반복하여 이상적인 $G$가 완성된 상태. $D$는 일정해지고 $G$가 생성한 분포는 학습데이터 분포와 동일
Theoretical Result
Algorithm 1
GAN은 Mini-batch Stochastic gradient descent(미니 배치 확률적 경사하강법)을 사용한다. $D$의 train step $k$가 하이퍼파라미터이며, 실험에서는 가장 작은 값인 $k=1$을 사용하였다.
for number of training iterations do
for k steps do
● Noise prior $p_g(z)$에서 $m$개의 Noise sample ${ z^{(1)}, …,z^{(m)} }$로 mini batch를 구성
● Data generating 분포 $p_{data}(x)$에서 $m$개의 sample ${ x^{(1)}, …,x^{(m)} }$로 mini batch를 구성
● $D$를 Stochastic gradient를 이용해 아래 수식을 maximize하도록 업데이트
\[\bigtriangledown_{\theta_d} \frac{1}{m} \sum_{i=1}^{m}\left [ log\;D(x^{(i)}) + log\; (1 - D(G(z^{(i)})))\right]\]end for
● Noise prior $p_g(z)$에서 $m$개의 Noise sample ${ z^{(1)}, …,z^{(m)} }$로 mini batch를 구성
● $G$를 Stochastic gradient를 이용해 아래 수식을 minimize하도록 업데이트
\[\bigtriangledown_{\theta_g} \frac{1}{m} \sum_{i=1}^{m}\left [ log\; (1 - D(G(z^{(i)})))\right]\]end for
4.1 Global Optimality of $p_g = p_{data}$
어떤 $G$에 최적인 $D$
Proposition 1. $G$를 고정할 때, 최적의 $D$는 다음과 같다.
\[D^*_G(x)= \frac{p_{data}(x)}{P_{data}(x)+p_g(x)}\]증명. 어떤 $G$가 주어졌을 때, $D$의 훈련 규칙은 $V(G,\;D)$를 $maximize$하는 것이다.
앞의 $V(G, D)$ 식에서 $\mathbb{E}$는 기댓값이며 Train data는 연속확률변수이다. 그러므로 연속확률변수의 기댓값을 구하는 공식인 $\mathbb{E} \left[X \right] = \int_{-\infty}^{\infty}xp(x)dx$를 적용하여 아래와 같은 식을 구할 수 있다.
\[\begin{align} V(G,\;D) &= \int_{x}p_{data}(x)log(D(x))dx + \int_{z}p_z(z)log(1-D(g(z)))dz \nonumber\\ &= \int_{x}\{p_{data}(x)log(D(x)) + p_g(x)log(1-D(x))\}dx \nonumber \end{align}\]어떤 $(a,b) \in \mathbb{R}^2$(${0,0}$제외)에서 함수 $y \to a\;log(y)+b\;log(1-y)$는 $[0,1]$에서 최댓값 $\frac{a}{a+b}$에 도달한다.
위 Proposition1이 완성된다.
- $p_{data}(x)$는 Train 데이터 분포, $p_g(x)$는 $G$가 생성한 데이터 분포이며 $z$는 생성모델의 입력인 Noise 데이터이다.
$D$의 Train 목표는 조건부 확률 $P(Y=y|x)$ 추정을 위해 log-likelihood를 $maximize$하는 것으로 해석될 수 있다.
여기서 $Y$는 $x$가 $p_{data}$(:$y=1$)에서 왔는지 또는 $p_g$(:$y=0$)에서 왔는지를 나타낸다. 그러므로 $minmax$식(Eq 1.)은 다음과 같이 재구성할 수 있다.
\(\begin{align} C(G) &= \underset{D}{max}\; V(G, D) \nonumber\\ &= \mathbb{E}_{x \sim p_{data}}\left[log\;D^*_G(x) \right] + \mathbb{E}_{z \sim p_z}\left[log(1-D^*_G(G(z))) \right] \nonumber\\ &= \mathbb{E}_{x \sim p_{data}}\left[log\;D^*_G(x) \right] + \mathbb{E}_{x \sim p_g}\left[log(1-D^*_G(x) \right] \nonumber\\ &= \mathbb{E}_{x \sim p_{data}}\left[log\;\frac{p_{data}(x)}{p_{data}(x)+p_g(x)} \right] + \mathbb{E}_{x \sim p_g}\left[log\frac{p_{g}(x)}{p_{data}(x)+p_g(x)} \right] \nonumber \end{align}\)
Theorem 1. 가상의 훈련 규칙 $C(G)$는 $p_g = p{data}$일때 최솟값에 도달하며 그 값은 $-log\;4$이다.
증명. $p_g=p{data}$ 일때, $D^*_G(x)=\frac{1}{2}$이다. 따라서 바로 위 식에서 역시 $D^*_G(x)=\frac{1}{2}$이므로, $C(G) = log\frac{1}{2} + log\frac{1}{2} = -log\;4$임을 알 수 있다.
이를 통해 우리는 다음과 같은 식을 얻을 수 있다.
\[\mathbb{E}_{x \sim p_{data}}\left[-log\;2 \right] + \mathbb{E}_{x \sim p_g}\left[-log\;2 \right] = -log\;4\]그리고 이 식을 $C(G) = V(D^*_G, G)$에서 빼면, 다음과 같은 식을 얻을 수 있다. 수식 유도 과정이 조금 알아보기 힘들어도 어려운 내용은 아니다
여기서 KL divergence를 적용한다. $KL(B \parallel A) = \mathbb{E}{x \sim B} \left [log\frac{B(x)}{A(x)} \right]$이므로 A를 $p_{data}(x)+p_g(x)$, B를 $p_{data}(x)$로 치환하면 다음과 같은 식을 얻을 수 있다.
\[C(G) = -log\;4+KL(p_{data}\parallel \frac{p_{data}+p_g}{2}) + KL(p_{g}\parallel \frac{p_{data}+p_g}{2})\]KL은 Kullback-Leibler divergence이다. KL Divergence는 두 확률분포의 차이를 계산할 수 있지만 대칭성이 성립되지 않는다. ($KL(A \parallel B) \neq KL(B \parallel A))$
우리는 위 식에서 모델의 분포와 data generating 분포 사이의 Jensen-Shannon Divergence를 계산할 수 있다. Jensen-Shannon Divergence 즉 JS Divergence는 KL Divergence와 유사하지만 대칭성을 갖는다는 특징이 차별점을 가진다. JS Divergence는 KL Divergence를 이용해 다음과 같이 구할 수 있다.
\[JS(A \parallel B) = \frac{1}{2}KL(A \parallel \frac{A+B}{2}) + \frac{1}{2}KL(B \parallel \frac{A+B}{2})\]위 식을 위에서 KL Divergence로 유도한 $C(G)$에 적용하면 (A는 $p_{data}$, B는 $p_g$) 다음과 같은 식을 얻을 수 있다.
\[C(G) = -\log{4} + 2 * JSD(p_{data} \parallel p_g)\]JS Divergence $\geq 0$이고 두 분포가 일치할때 0이 되기 때문에, $C^* = -log\;4$는 $C(G)$의 최솟값이며 $p_g = p_{data}$일때 성립한다. 이는 $G$가 데이터를 완벽하게 복제하여 생성하는 상태를 의미한다.
4.2 Convergence of Algorithm 1
Proposition 2. Algorithm 1의 각 step에서 $D$는 최적의 $G$에 도달하도록 하며, Train 규칙을 향상시키기 위해 $p_g$를 업데이트한다. 아래 수식을 통해 $p_g$는 업데이트할 수록, $p_{data}$에 수렴한다.
\[\mathbb{E}_{x \sim p_{data}} \left [log \;D^*_G(x) \right] + \mathbb{E}_{x \sim p_{g}} \left [log(1-D^*_G(x) )\right]\]증명. 위 규칙과 같이 $V(G, D) = U(p_g, D)$를 $p_g$의 함수로 정의한다. $U(p_g, D)$는 $p_g$에서 볼록(convex)하다. 볼록함수의 supremum(상한)의 subderivatives(하방미분)은 함수의 최대값에서의 도함수를 포함한다. $f(x) = sup_{\alpha \in A} f_\alpha (x)$이고, $x$에 대한 함수 $f_\alpha (x)$가 모든 $\alpha$에 대해 볼록하다면, $\beta = arg\;sup_{\alpha \in A}f_\alpha (x)$ 일때 $ \partial f_\beta (x) \in \partial f $이다.
- 여기서 $x$는 $p_g$, $\alpha$는 $D$, $\partial $는 하방미분을 의미한다.
즉 위 증명이 나타내는 것은 $U(p_g, D)$가 $p_g$에 대해 볼록함수라면, 최적의 모델 $D$의 하방미분값은 $U(p_g, D)$의 하방미분에 포함된다는 것이다.
Theorem 1에서 $U(p_g, D)$가 볼록함수이며 $U(p_g, D)$의 고유한 최적값은 $-log\;4$임을 알수있다. 따라서 $U(p_g, D)$는 최적의 모델 $D$에서 $p_g$의 최적값인 $-log\;4$를 가진다.
즉 $p_g$를 업데이트한다면, 고유한 최적값에 도달할 수 있음을 증명한다.
Theorical Results에서는 $G$의 분포인 $p_g$를 이용해 이론적인 증명을 완성하였다. 하지만 실제로 학습할 때에는 $p_g$가 아닌 모델의 파라미터인 $\theta _g$를 Optimizing한다. 다층 퍼셉트론으로 G를 정의하였을 때, 파라미터 공간에 여러 임계점이 생기지만, 실험적으로 다층 퍼셉트론이 뛰어난 성능을 보이기에 합리적인 모델임을 시사한다.
Experiments
우리는 적대적 신경망을 MNIST와 TFD, CIRAR-10이 포함된 데이터셋으로 훈련시켰다. #G#는 ReLU와 Sigmoid Activation Function을 혼합하였고, $D$는 Maxout Activation Function를 사용하였다. $G$의 입력으로는 Noise 데이터를 사용하였다.
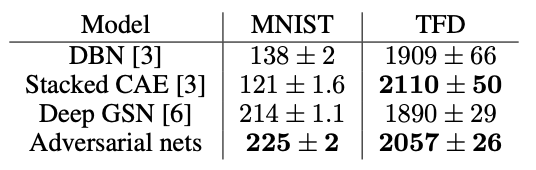
위는 Parzen window 기반의 log-likelihood 추정치이다. 이 Metric은 분산이 높고 고차원 공간에서는 잘 작동하지 않지만 당시로써는 가장 좋은 Metric이었다. 논문이 발표된 당시, 생성모델을 평가하기 충분한 Metric이 없어서 논문에는 생성모델을 평가하는 방법에 대한 추가 연구와 동기를 부여한다고 적혀있다.

a는 MNIST, b는 TFD, c는 CIFAR-10(fully-connected model), d는 CIFAR-10(convolutional discriminator and “deconvolutional” generator) 데이터셋이다.
Advantages and disadvantages
GAN의 단점은 $p_g(x)$가 명시적으로 표현되지 않는다는 것이며, $D$는 학습되는 $G$에 원활한 동기화가 이루어져야한다는 것이다. Helvetica scenario를 피하기 위해 $G$는 $D$의 업데이트 없이 너무 많은 학습이 이루어지면 안된다. Helvetica scenario는 $G$가 $p_{data}$를 모델링하기 위해 너무 많은 Noise data $z$를 동일한 데이터 $x$로 축소하는 것을 의미한다.
Helvetica scenario는 Model collapse라고도 불리며, $G$가 $D$에 비해 학습이 너무 많이 이루어져 $G$가 특정 domain만을 생성하는 경우를 말한다.
Conclusions and future work
이 프레임워크는 다양한 방향으로 확정성을 가진다.
- 조건부(conditional) 생성 모델 $p(x|c)$는 $G$와 $D$에 조건 $c$를 입력으로 추가하여 얻을 수 있다.
- 학습된 근사 추론(approximate inference)은 주어진 x를 예측하기 위해 보조 네트워크를 훈련함으로써 수행될 수 있다. 이는 wake-sleep 알고리즘으로 훈련된 추론 네트워크와 유사하지만, $G$ 훈련을 마친 후 고정된 $G$에 대해 추론 네트워크를 훈련할 수 있다는 장점이 있다.
- 파라미터를 공유하는 모든 조건부 생성 모델을 학습하여 $x$의 지수의 부분집합인 $S$에 대해 모든 조건부 $p(x_S \; | \; x_{\not S})$를 근사적으로 모델링할 수 있다.
- 준 지도학습 : $G$또는 $D$의 기능을 사용하여 제환된 labeling 데이터의 경우에서 Classifier의 성능을 향상시킬 수 있다.
- 효율성 향상 : $G$와 $D$를 더 나은 기법으로 조정하거나, Train 중 sample $z$에 더 좋은 분포를 결정하 훈련을 가속화시킬 수 있다.
지금까지 GAN이 처음 발표된 논문에 대하여 알아보았다. GAN의 구조와 작동 방식에 대해 대략적으로만 알았는데, 논문을 읽으며 자세히 수학적으로 접근하였을때 깨달은 것이 많았다. 이 포스팅을 시작으로 다양한 GAN 논문에 대해 Review를 하나씩 시작하려고 한다. 다음 논문은 GAN의 많은 발전을 이끌어낸 DCGAN이다.