[Paper Review] Pix2pix
[논문 리뷰] Image-to-Image Translation with Conditional Adversarial Networks - Pix2pix
Pix2pix는 Image-to-Image Translation을 수행하는 모델에 관한 연구로서, Conditional Generative Adversarial Network(CGAN)을 사용하여 하나의 structure을 이용한 이미지 간의 domain 변환을 수행하는 base model을 제공했다는 점에서 많은 인용 수를 자랑한다.
이번 논문에서 제안하는 network는 input 이미지 → ouput 이미지로의 mapping을 학습할 뿐만 아니라 mapping train을 위한 loss function도 학습한다. 따라서 기존에는 서로 다른 loss식이 필요했던 문제에도 동일한 방식을 적용할 수 있다. 이번 논문은 더 이상 mapping function을 직접 설계하지 않으며, loss function 역시 직접 설계하지 않고도 합리적인 결과를 얻을 수 있음을 시사한다.
Introduction

어떤 개념을 다양한 언어로 표현할 수 있는 것처럼, 이미지 역시 RGB, gradient field, edge map, sementic label map 등으로 표현할 수 있다. 위 figure 1처럼 이미지 간 translation은 충분한 train 데이터가 주어졌을 때 이미지에 내포된 domain 중 하나를 다른 domain으로 변환하는 작업으로 정의할 수 있다.
Image-to-Image Translation 역시 loss function을 minimize하는 것을 목표로 하는 CNN을 사용하여 많은 연구가 이루어졌다. predict된 sample과 실제 데이터 사이의 Euclidean distance를 minimize하면 흐릿(blur)한 이미지를 얻는다. Euclidean distance는 그럴듯한(?) output을 모두 평균내어 계산하기 때문이다.
이러한 문제를 해결하기 위해 이번 논문에서는 생성된 이미지가 fake인지 real인지 구별하는 GAN의 특성을 이용한다. blur 이미지는 fake로 분류될 것이고, GAN은 데이터에 맞는 loss function을 학습하기 때문에 다양한 loss가 필요한 task에 적용할 수 있기 때문이다.
특히 특정 조건을 가진 이미지를 학습하기 때문에 Conditional GAN, 즉 cGAN을 사용한다. 원래의 GAN은 생성되는 sample이 어떤 label을 가지는지 조절할수 없었다. 이에 대한 가이드라인을 $D$와 $G$의 input으로 넣어줌으로써 원하는 label에 대한 output을 도출하게 만든 모델이 cGAN이다.
Method
3.1 Objective
cGAN은 observed image인 $x$와 noise vector $z$를 output인 $y$로의 mappping을 학습한다. ($G : ( x,z ) \to y$)
cGAN의 Loss 식은 다음과 같다.
\[\underset{G}{\text{min}}\; \underset{D}{\text{max}}\;\mathrm{L}_{cGAN}(G, D) = \mathbb{E}_{x, y} \left[\log D(x, y) \right] + \mathbb{E}_{x, z} \left[1 - \log D(x, G(x, z)) \right] \tag {1}\]또한 원래 GAN의 objective와 L2 distance를 결합하는 것이 좋다는 것을 발견하였고, blurring이 덜한 L1 distance를 사용한다.
\[\mathrm{L}_{L1}(G) = \mathbb{E}_{x,y,z} \left[\| y - G(x,y)\|_1 \right] \tag{3} \\\]최종 Objective는 다음과 같다.
\[G^* = \text{arg}\;\underset{G}{\text{min}}\;\underset{D}{\text{max}}\; \mathrm{L}_{cGAN}(G, D)+ \lambda \mathrm{L}_{L1}(G) \tag{4}\]pix2pix는 noise $z$를 사용하지 않는다. $G$가 이 noise를 무시하도록 학습하며, 이때문에 mapping할 때 stochastic하지 않고 deterministic해진다.
3.2 Network Architecture
논문에서 제안하는 모델에서의 $G$와 $D$는 DCGAN(Deep Convolution GAN)을 베이스로 하였다. (Convolution, BatchNorm, ReLU 형식)
3.2.1 Generator with skip
image-to-image translation의 특징은 고해상도 input grid를 고해상도 output grid에 mapping한다는 것이다. 이러한 특징을 고려하여 이전 연구들에서는 Encoder-Decoder 네트워크 구조를 보통 사용하였다. 이 구조에서는 input이 여러 layer를 통과하며 downsampling된 후, upsampling된다. 이 과정에서 input-output간의 공유되는 정보에는 low-level 정보가 포함되어있지 않고 핵심 정보만이 남아있다. 즉 이미지의 detail에 대한 정보는 남아있지 않는 것이다.
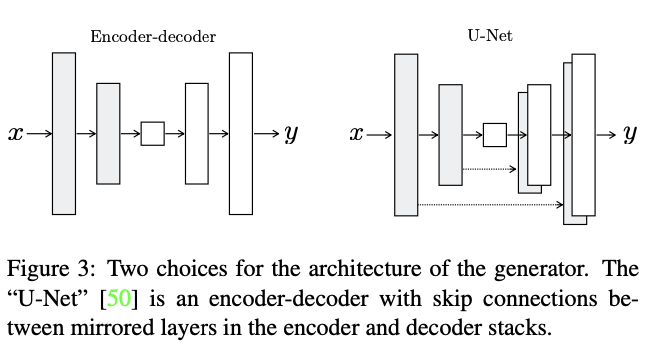
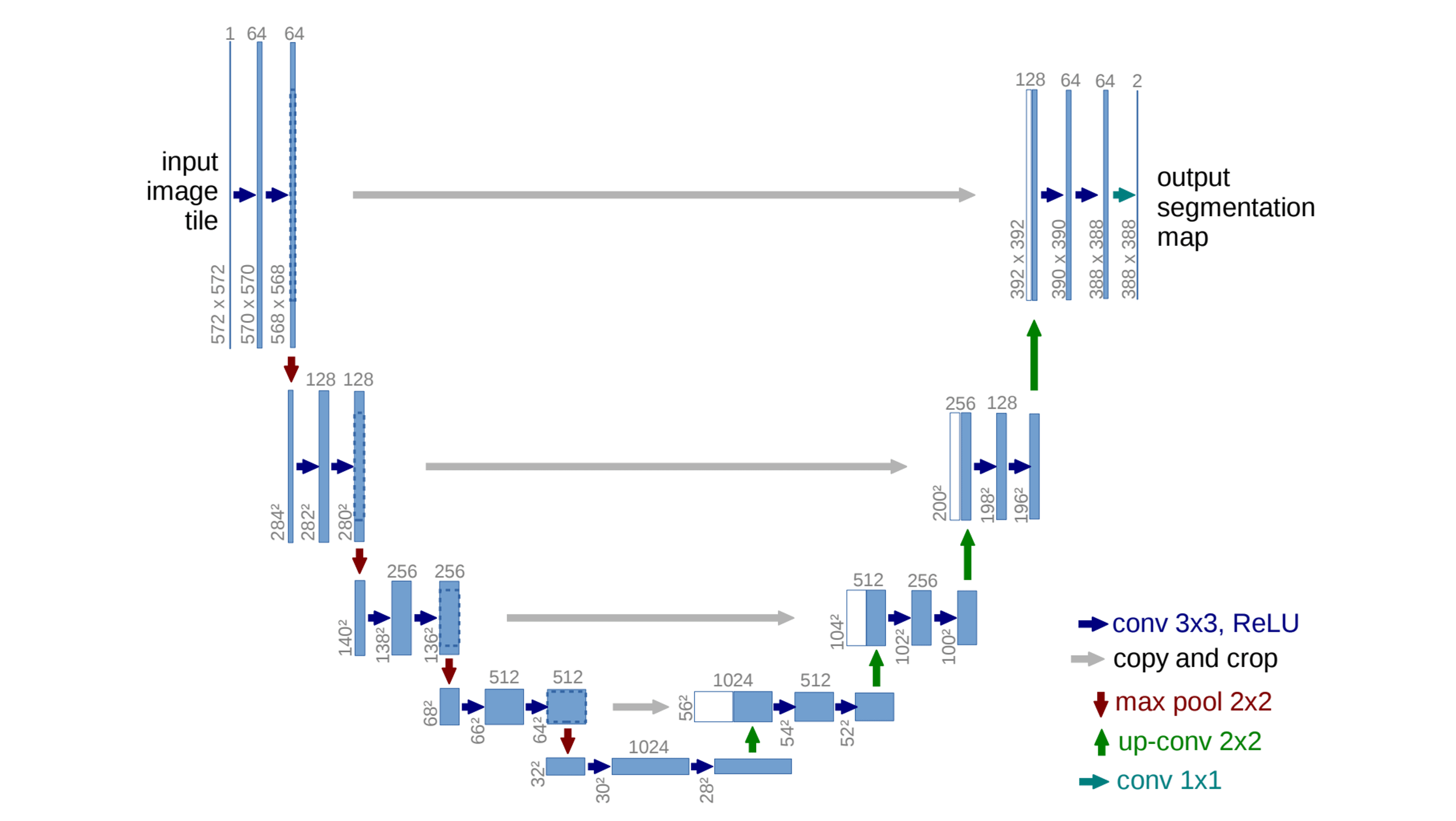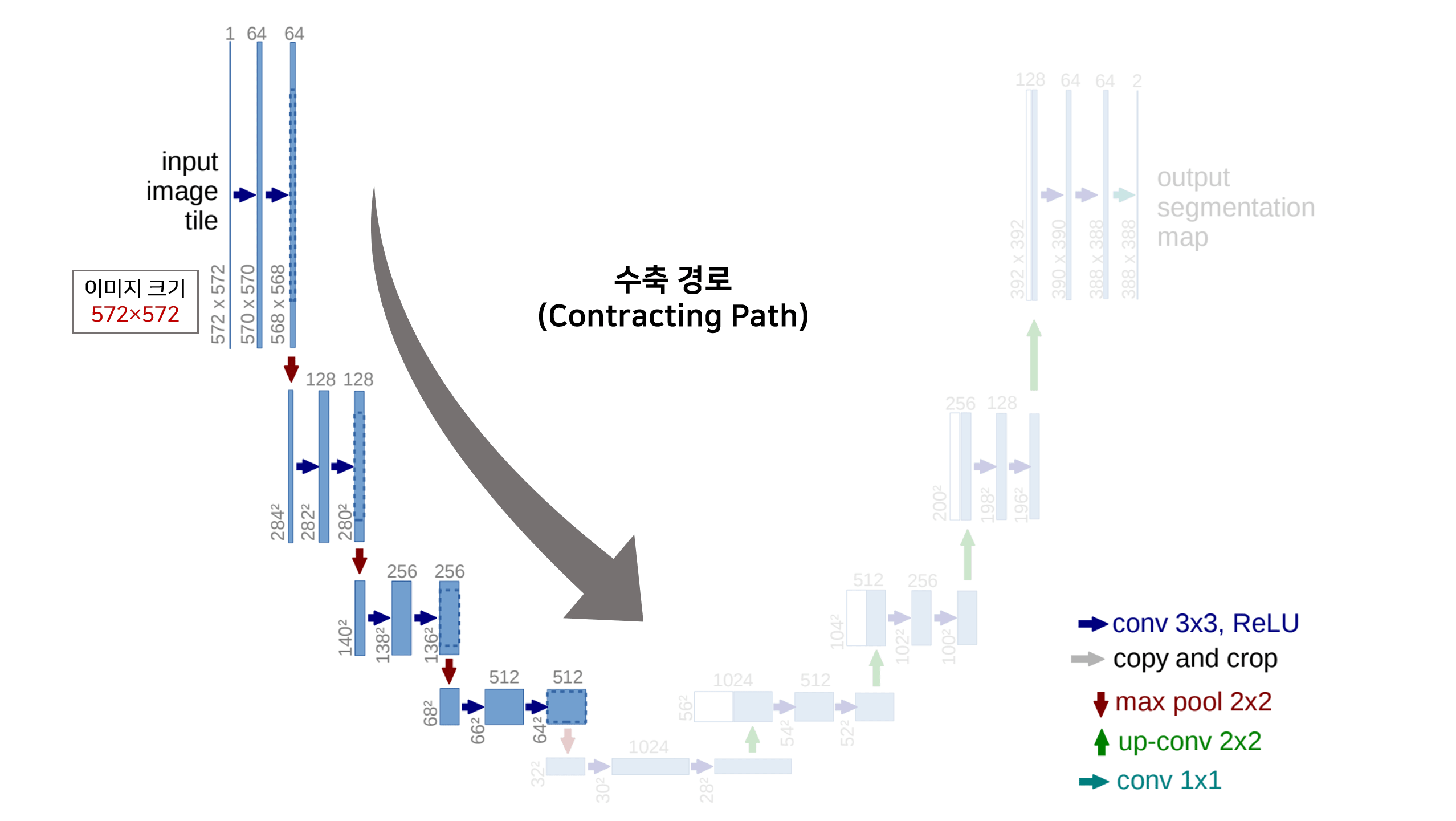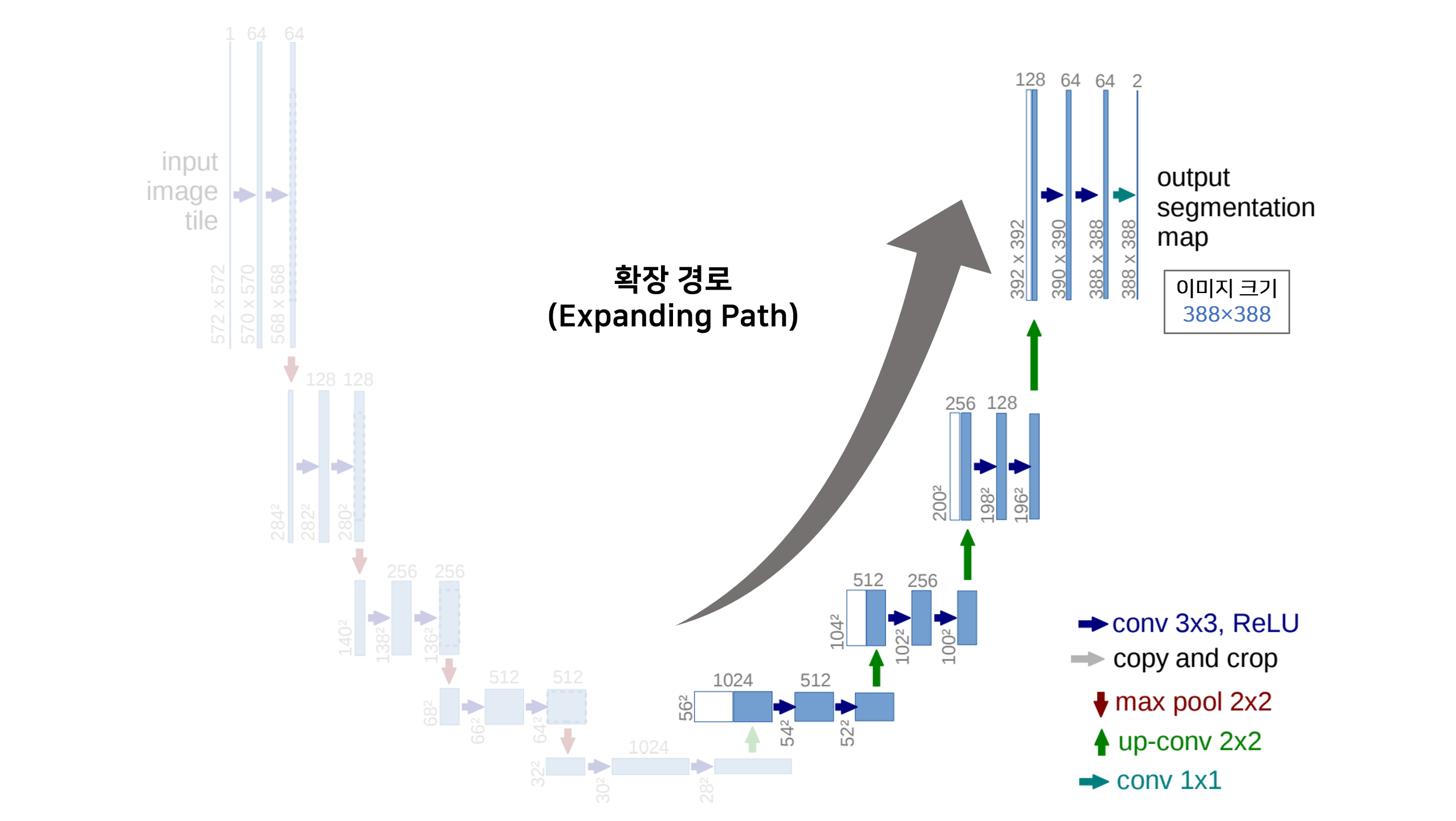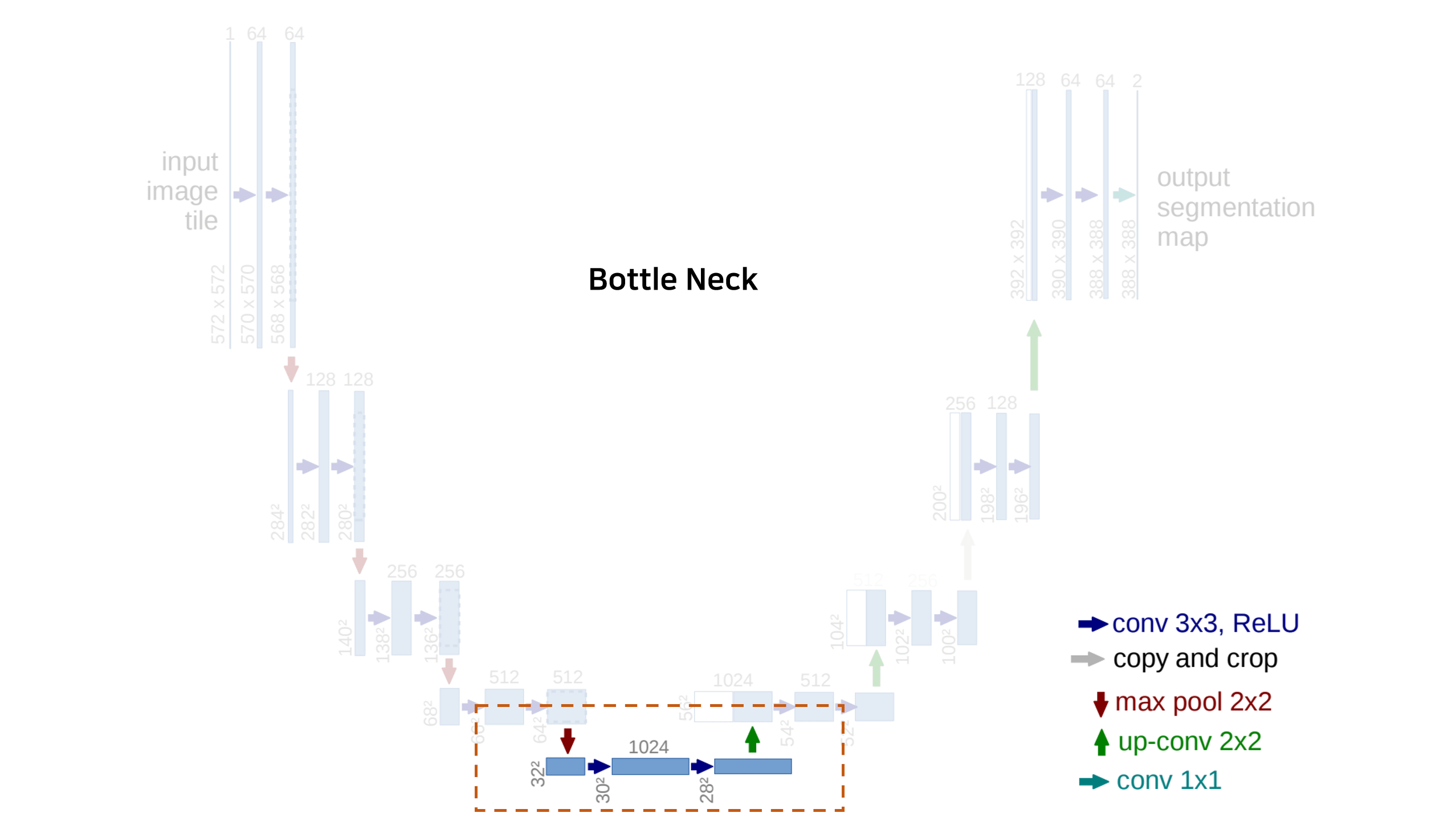
이러한 병목현상을 방지하기 위해 초반 layer에 존재하는 low-level 정보를 network를 통해 직접 전달해야하는데, 바로 U-Net이다. U-Net은 $i$번째 layer와 $n-i$번째 layer사이에 skip connection을 추가한다.
3.2.2 Markovian discriminator (PatchGAN)
뒤에 나올 Figure 4를 보면, L1 loss를 사용한 모델 sample에 많은 blur를 확인할 수 있다. 이는 high-frequency, 즉 이미지의 edge부분의 선명도 향상에는 도움이 되지 않지만 low-frequency, 즉 배경이나 텍스쳐 부분의 정확성을 강화한다.
이미지에서의 High-frequency(고주파), Low-frequency(저주파)는 픽셀 변화 정도에 따라 나누어진다. High-frequency(고주파)는 픽셀값의 변화가 큰 부분, 즉 사물의 edge나 corner 등에 해당한다. Low-frequency(저주파)는 픽셀값의 변화가 작은 일반적인 배경이나 텍스쳐 등에 해당한다.
논문에서는 $D$가 high-frequency 구조만을 modeling하도록 제한하기 위해 판별에 사용할 정보를 local image patches로 제한하며 이를 PatchGAN으로 부른다.
기존 GAN은 이미지의 전체를 보고 $D$가 판단한다. 즉 전체적인 이미지만 진짜처럼 만들고 detail한 부분을 신경쓰지 않아도 된다는 것이다.
앞에서 L1 loss가 low-frequency에 대한 정확성을 강화한다고하였듯이, low-frequency 부분에 대한 판단은 L1에게 맡기고 cGAN이 high-frequency에 대한 부분을 맡기 위함이다.
이미지의 detail한 부분을 파악하기 위해서는 low-frequency 부분을 필요없기 때문에 $D$가 high-frequency에 대한 높은 정확성을 가지도록 PatchGAN을 사용한다.
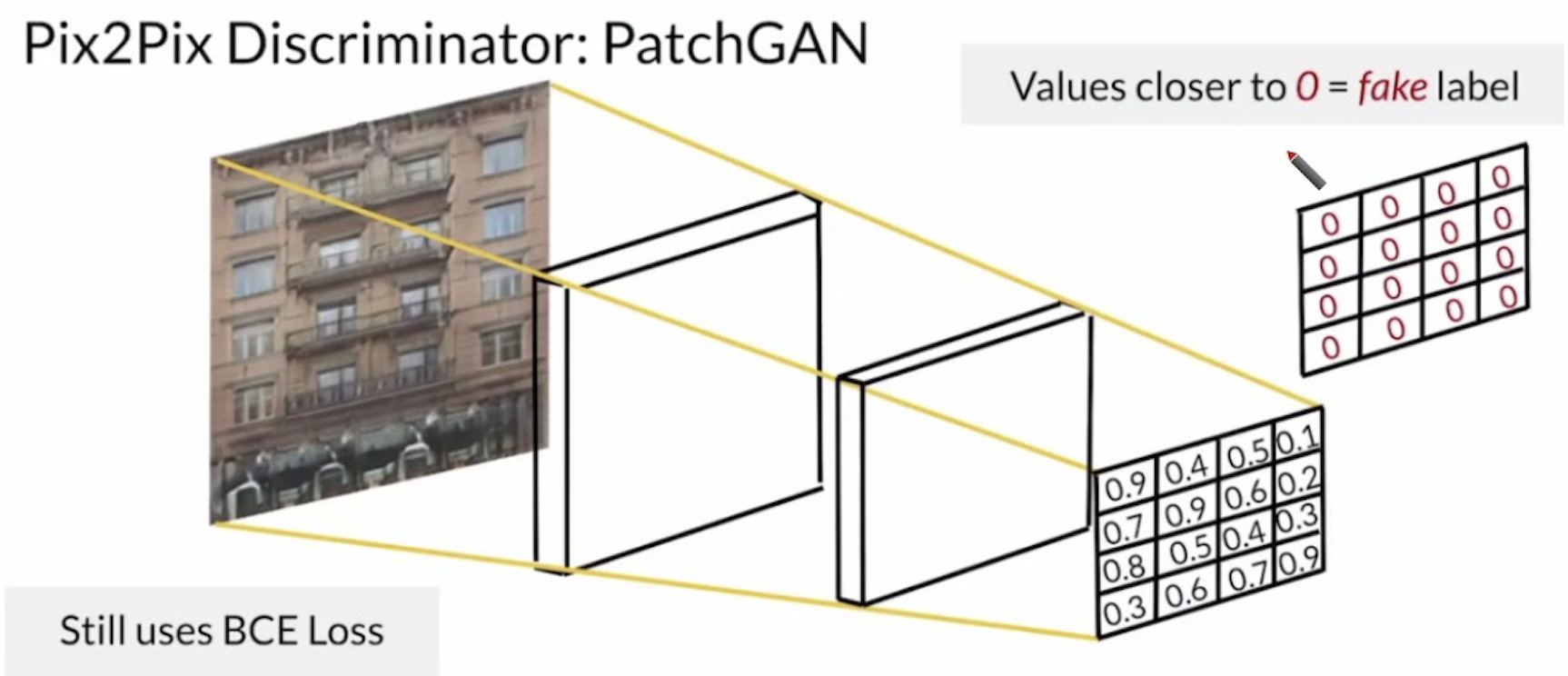
PatchGAN의 $D$는 이미지를 $N \times N$개의 patch로 나눈 뒤, 각 patch를 real or fake로 분류한다. 모든 patch에 대한 Output의 평균을 구하여 최종 분류결과를 도출한다. PatchGAN은 파라미터의 크기가 적고, 빠르며 어떤 큰 이미지에도 적용할 수 있다는 장점을 가진다.
3.3 Optimization and Inference
2014년에 발표된 GAN 논문에서는 $D$를 $k$ step 업데이트 후, $G$를 1 step 업데이트한다. 또한 $\log \;(1-D(x, G(x,z)))$를 minimize한 대신, $\log \;(D(x,G(x, z)))$를 maximize하는 방향으로 $G$를 train한다.
Pix2pix는 위 GAN의 optimizing 정책을 사용한다. mini-batch stochastic gradient descent(mini-batch SGD)와 Adam을 사용하며 learning rate는 0.0002, momentum parameter는 $\mathbf{\beta_1 = 0.5}$, $\mathbf{\beta_2 = 0.999}$이다.
Experiments
Analysis of the objective function
Eq. 4에서 어느 요소가 중요한지 알아보기 위해 논문에서는 각 항(L1, cGAN에 대한 loss)의 제거 실험을 진행하였다.

그림 4에서 볼 수 있듯이, L1만 사용하면 흐릿한 결과를 얻으며 $\lambda = 0$으로 하여 cGAN만 사용할 때에는 훨씬 선명한 결과를 얻지만 특정 상황에서 시각적인 왜곡이 발생한다. $\lambda = 100$일때 두 항을 모두 사용하면 이러한 왜곡이 줄어든다.
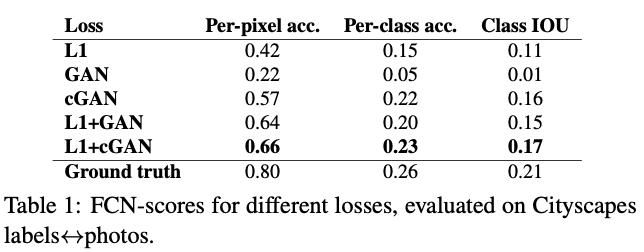
표 1을 봐도 L1 + cGAN의 성능이 가장 놓은 것을 알 수 있다.
Analysis of the generator architecture

U-Net 구조와 L1+cGAN를 함께 사용한 모델이 생성한 sample의 품질이 가장 높다는 것을 알 수 있다.
From PixelGANs to PatchGANs to ImageGANs

Figure 6을 통해 PatchGAN의 Patch size에 따른 성능을 알 수 있다. 이미지를 많이 분할할 수록 high-frequency에 해당하는 부분, 즉 edge와 같은 detail적인 부분이 향상된다.
여기서 $1 \times 1$에 해당하는 모델은 PixelGAN이라 하며 full image인 $286 \times 286$에 해당하는 모델은 ImageGAN이라 한다.
Conclusion
- pix2pix는 다양한 image-to-image translation에 적용할 수 있는 일반적인 프레임워크를 제공한다.
- pix2pix는 다양한 image-to-image translation에서 높은 성능을 보여준다. 이는 GANs의 효과적인 적용을 통해 가능하게 되었으며, 이는 GANs의 강력함을 입증하는 사례로 작용되었다.



사람이 그린 detail한 스케치로도 사실적인 sample을 생성할 수 있다.