[Paper Review] REACT : Learning Customized Visual Models with Retrieval-Augmented Knowledge
[논문 리뷰] Learning Customized Visual Models with Retrieval-Augmented Knowledge
제목 : Learning Customized Visual Models with Retrieval-Augmented Knowledge
저자 : Haotian Liu, Kilho Son, Jianwei Yang, Ce Liu, Jianfeng Gao, Yong Jae Lee, Chunyuan Li
링크 : arXiv Project Page
1. Introduction
다양한 범위의 하위 task에 적용할 수 있는 system을 구축하는 문제는 사실상 대량의 데이터셋으로 학습시키는 방법이 유일하다. 하지만 엄청난 크기의 labeled 데이터셋을 마련하는 것은 쉽지 않기에 self-supervised learning이 주목받기 시작하였고, 10억개의 크롤링된 image-text 데이터셋으로 contrastive learning을 수행한 CLIP이 그 예시이다. CLIP과 같은 pretrained model을 구축한 뒤, 원하는 task에 맞도록 모델을 fine tuning하거나, linear probing, prompt tuning, zero-shot task 등을 수행하는 2가지 단계의 파이프라인을 따른 연구가 이어져 오고 있다.
이 논문은 이러한 2단계의 파이프라인이 지나치게 단순하며 효율이 떨어짐을 주장하며 ‘검색’된 외부 지식을 활용하여 커스터마이징을 수행하는 것을 제안한다. 대규모 데이터셋에서 외부 지식을 수집/학습하여 커스터마이징하며, 수집하는 과정에는 인간의 annotation이 개입되지 않는다. 수집할 지식은 LAION 데이터셋이나 웹에서 얻을 수 있으며 다양한 domain을 포함하기 때문에 task-level transfer을 위한 visual 모델 커스터마이징에 유용하다.
저자들은 이 아이디어를 사람들이 특정 기술을 습득하기 위해 모든 지식을 외우는 대신 관련 분야에서 사전 교육을 통해 미리 준비하고 훈련하는 방식에서 영감을 얻었다고 한다.
저자들은 이를 위해 대규모 Multi-modal indexing system 구축한다.
위 시스템을 통해 관련 Text-Image 쌍을 검색할 수 있으며 이 과정에는 CLIP과 ANN(Approximate Nearest Neighbor) search가 적용된다. 기존 모델은 freeze하고 검색된 지식으로 추가 weight만을 학습시킴으로써 기존 모델이 가진 지식을 잊어버리지 않고 새로운 지식을 학습할 수 있다.
논문에는 OpenAI의 CLIP과 LAION의 외부지식을 사용하여 4가지 Computer Vision problem인 이미지 분류, Object Detection, Image-Text 검색, Semantic Segmentation에서 효과를 입증했다고 말한다. 기존 train data의 3%에 해당하는 검색된 증강 지식(retrieval-augmented knowledge)으로 zero-shot task에 특히 향상된 성능을 보여주었다.
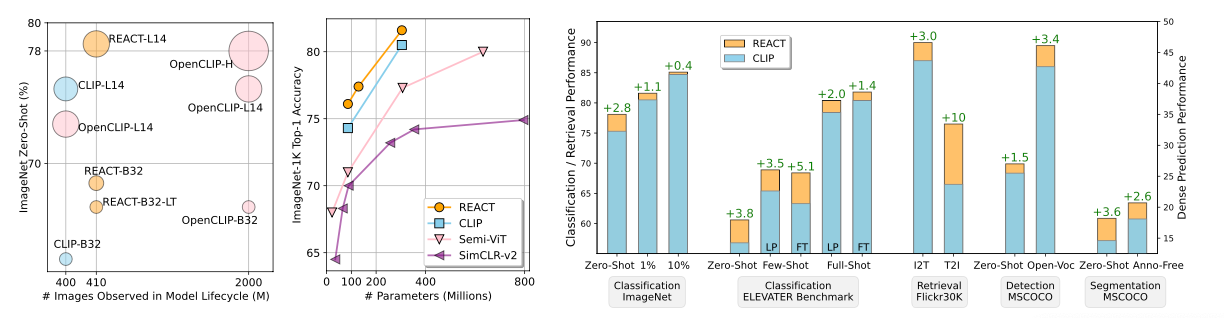
위 그림을 보면 모든 problem에 대해 CLIP보다 향상된 성능을 확인할 수 있다.
2. Relative Work
Vision-Language Models (CLIP)
CLIP(Contrastive Language-Image Pre-Training)은 OpenAI에서 개발한 Vision-Language Model이다. 웹에서 크롤링된 Image-Text 데이터인 LAION을 활용하여 train되었으며, contrastive learning을 통해 image, text 데이터 간의 유사성을 통해 다양한 modality의 연관성을 학습하였다.
contrastive learning 이란 유사한 데이터들은 representation 공간에서 서로 가깝게, 동시에 다른 데이터들은 서로 멀리 떨어져있도록 encoding하는 방법을 모델이 학습하는 것을 말한다. CLIP은 이러한 학습 방식을 사용하여 text와 image에 담긴 유사성을 파악하여 같은 space에 mapping하도록 학습하였다.
Retrieval Augmented Models
자연어 처리 분야에서 LLM에 외부 데이터를 encoding하여 활용하는 retrieval-augmented 모델이 제안되었다. 이를 통해 classification, 질문 답변, generation, multi-modal 등에서 성능 향상을 보였으며, Computer Vision 분야에도 활용되고 있는 추세이다. 특히 RAC와 K-LITE 모델이 대표적인 사례로, Image-Text 쌍의 지식을 활용하여 Classification, Retreive, Object Detection, Segmentation 등에서 성능 향상을 보이고 있다.
Adaptation of Vision-Language models
CLIP은 위에서 설명한 contrastive learning을 통해 zero-shot과 linear probing에서 성능을 보인다. 다음은 CLIP의 adaption 성능을 향상시키기 위한 방법들을 간단하게 설명한다.
ELEVATER는 text encoder를 활용하여 특정 task의 linear head를 초기화하며, 이를 통해 CLIP의 linear probing과 fine-tuning 성능을 향상시켰다.
NLP의 prompting 기법에 착안하여 learnable한 propmt를 활용하여 CLIP의 adaption 성능을 향상시키는 연구가 많이 나오고 있다. 하위 task에 대한 적은 양의 data를 활용하여 train cost가 적다는 장점이 있다.
이에 대한 연구 중 하나다 앞서 리뷰했던 PromptStyler이다.
Vision-language model은 task-level transfer에서 성능을 보이며 task-level transfer에는 다음 2가지 task가 있다.
- Zero-shot : train 단계에서 보지 못한 class를 분류하는 기법이다. train 데이터에는 해당 class의 이미지가 포함되어있지 않으며, category 이름과 같은 간단한 task definition만이 주어진다. (task definition : $\mathcal{I}_F = \lbrace \mathbf{t} \rbrace$)
- Few/Full-shot : train instance에서 annotation을 추가하여 task를 구체화할 수 있다. (task instruction : $\mathcal{I}_F = \lbrace (x_n, \mathbf{t}_n, y_n) \rbrace^N_{n=1}$) 이를 통해 CLIP의 image encoder $f_\theta$를 업데이트할 수 있다.
3. Retrieval-Augmented Customization (REACT)
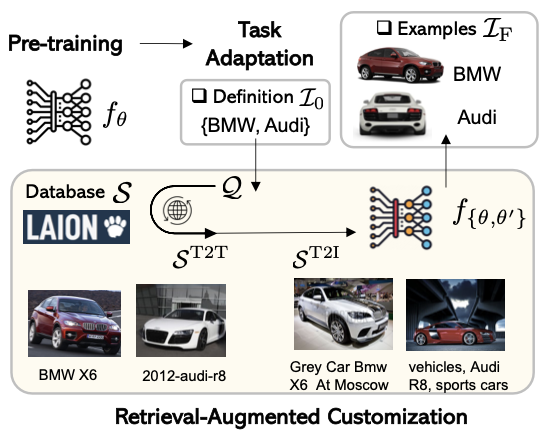
3-1. Preliminaries
저자들은 generality를 유지하기 위해 $(x, \mathbf{t}, y)$의 format을 사용하였다.
이미지 $x \in \mathcal{X}$
Language 설명 $\textbf{t} \in \mathcal{T}$ → text sequence $\mathbf{t} = [ t_1, \cdots, t_L]$
• $L$ : 이미지를 설명하는 text의 수이며, $L$이 작을 경우에는 $t$는 이미지의 category, 클 경우에는 이미지를 설명하는 의미가 풍부한 문장이 될 수도 있다.
label $y \in \mathcal{Y}$
논문에서는 web-scale(웹에서 확인할 수 있는) Image-Text 데이터가 external knowledge source $\mathcal{S}$로 존재한다고 가정한다. ($\mathcal{S} = \lbrace (x_m, t_m) \rbrace^M_{m=1}$, $M$은 데이터베이스 크기. LAION은 $400M$. 4억개)
REACT의 목표는 하위 task instruction $\mathcal{I}$와 external knowledge source $\mathcal{S}$가 주어졌을 때, 커스터마이징 과정에서 train&evaluation 이미지가 없는 상태에서도 하위 task에 transferable한 vision-semetic representation을 학습하는 것이다.
3-2. Multi-modal External Knowledge
Knowledge Base 구축
저자들은 대부분의 실험에서 4억개의 데이터를 가진 공개 dataset LAION-400M을 사용하였고, 웹에서 수집한 8억개의 데이터 Web-800M을 사용/비교하여 검색된 데이터의 영향성에 대해 연구했다.
CLIP으로 feature를 추출하고, FAISS 라이브러리를 이용해 cross-modal retrieval system을 구축한다. 이 시스템을 통해 다양한 하위 task에 필요한 domain에 대해 관련된 Image-Text 데이터를 검색할 수 있다.
FAISS란 Facebook에서 개발한 라이브러리로, 대량의 고차원 벡터에서 유사성 검색 및 클러스터링을 빠르고 효율적으로 수행할 수 있다. Hierarchical Navigable Small World (HNSW) 알고리즘을 사용하여 빠른 k-NN 탐색을 가능하게 한다.
Retrieval-Augmented Task Instruction
다양한 커스터마이징 task에 적용하기 위해서 task instruction 스키마(구조)는 통일된 형태여야하며, 저자들은 이를 위해 task definition $\mathcal{I}_0$를 대상의 시각적 특징을 설명하는 텍스트로 구성한다.
이 task definition을 인력으로 annotation하면 정확하고 완전한 $\mathcal{I}_F$를 만들 수 있지만, 추가적인 비용이 불가피하다. 그래서 저자들은 인적 cost 없이 위에서 구축한 외부 Knowledge Base $\mathcal{S}$에서 검색된 example들로 task instruction을 보강하는 것을 제안한다.
검색된 example : Image-Text pair
task definition인 $\textbf{t} \in \mathcal{I}_0$은 언어 prompt를 사용하여 자연어 $\boldsymbol{q} = g_{prompt}(\boldsymbol{t})$로 확장된다.
\[\mathcal{Q}=\left\{\boldsymbol{q} \mid \boldsymbol{q}=g_{\text {prompt }}(\boldsymbol{t}), \forall \boldsymbol{t} \in \mathcal{I}_0, prompt \in \mathcal{P}\right\} \tag{1}\]이 $\boldsymbol{q}$를 사용하여 Knowledge Base $\mathcal{S}$에서 검색하여 관련된 Image-Text 데이터를 얻게 된다. → $\boldsymbol{s} = g_{retrieve}(\boldsymbol{q})$
가장 결과가 좋은 상위 $K$개의 데이터를 얻기 위해 다음 2가지 process가 사용된다.
Text-to-Text (T2T) Retrieval
Image-Text에서 text를 검색하며, text간의 유사성이 높아 목표 concep과 잘 일치하는 example을 검색할 수 있다.
- \[S^{T2T} = \left\{(\boldsymbol{x},\boldsymbol{t}) \in \mathcal{S} : \underset{\boldsymbol{t}\in \mathbb{T}, \vert \mathbb{T} \vert = K}{\text{argmax}} f_\phi (\boldsymbol{t})^\top f_\phi (\boldsymbol{q}), \forall \boldsymbol{q} \in \mathcal{Q} \right\} \tag{2}\]
Text-to-Image (T2I) Retrieval
Image-Text에서 Image를 검색하며, 다양한 이미지 데이터에서 text 설명의 다양성을 확보할 수 있다.
- \[S^{T2I} = \left\{(\boldsymbol{x},\boldsymbol{x}) \in \mathcal{S} : \underset{\boldsymbol{x}\in \mathbb{X}, \vert \mathbb{X} \vert = K}{\text{argmax}} f_\theta (\boldsymbol{x})^\top f_\phi (\boldsymbol{q}), \forall \boldsymbol{q} \in \mathcal{Q} \right\} \tag{3}\]
위 2가지 process를 통해 검색된 외부 지식은 task definition $\mathcal{I}_0$을 augment하기 위해 사용된다.
3-3. Model Customization

(a) 처럼 전체 모델을 fine-tuning하여 커스터마이징을 수행할 수도 있지만, 저자들은 외부 지식을 활용할 수 있도록 추가적인 기능을 학습할 수 있는 방법을 제안한다. 이를 위해 모델의 weight를 freeze하고, 다음 2가지 방법을 사용하여 locked-text gated-image tuning을 수행한다.
Text는 freeze, Image는 open한다는 의미
Modularized Image Encoder
Image Encoder는 다음과 같이 바뀐다.
Image Encoder의 원래 layer 사이사이에 gated self-attention dense block을 삽입하고 처음부터 학습 시킨다. 이 Dense block은 위 그림 (d)처럼 self-attention layer와 feed-forward layer로 구성된다.
Frozen Text Encoder
Vision-Language contrast model(여기선 CLIP)의 Text Encoder는 task semantic space를 나타낸다. 이를 유지하기 위해 pretrain 모델의 Encoding 지식을 lock하는 locked-text tuning을 제안한다.
hypersphere space에서 normalize된 feature를 추출하기 위해 L2-norm을 적용하였다.
$ \boldsymbol{u}_i = \frac{f_{\lbrace \theta, \theta ‘\rbrace} ( \boldsymbol{x}_i)}{\parallel f_{\lbrace \theta, \theta ‘\rbrace} (\boldsymbol{x}_i)\parallel }$, $ \boldsymbol{v}_j = \frac{f_{\phi} (\boldsymbol{t}_j)}{\parallel f_{\phi} (\boldsymbol{t}_j)\parallel }$
task definition $\mathcal{I}_0$으로 모델을 커스터마이징하기 위해 $\theta ‘$를 업데이트한다.
이를 위해 검색된 지식인 $S^{T2T}$와 $S^{T2I}$에서 Image, Text를 모두 학습하는 Objective를 사용한다.
\[\begin{align*} \underset{\lbrace\theta ' \rbrace}{\text{min}}\;\; \mathcal{L}_\text{C} =\mathcal{L}_{i2t} + \mathcal{L}_{t2i}, \; \text{with}\; \mathcal{B} \sim S^{T2T} \text{or} S^{T2I} \tag{4}\\ \mathcal{L}_\text{i2t} = -\sum_{i\in \mathcal{B}} \frac{1}{\vert\mathcal{P}(i)\vert} \sum_{k \in \mathcal{P}(i)} \log \frac{\exp(\tau \boldsymbol{u}_i^\top \boldsymbol{v}_k)}{\sum_{j\in\mathcal{B}}\exp(\tau \boldsymbol{u}_i^\top \boldsymbol{v}_j)} \tag{5} \\ \mathcal{L}_\text{t2i} = -\sum_{j\in \mathcal{B}} \frac{1}{\vert\mathcal{Q}(j)\vert} \sum_{k \in \mathcal{Q}(j)} \log \frac{\exp(\tau \boldsymbol{u}_k^\top \boldsymbol{v}_j)}{\sum_{i\in\mathcal{B}}\exp(\tau \boldsymbol{u}_i^\top \boldsymbol{v}_j)} \tag{6} \end{align*}\]$\mathcal{P}(i) = \lbrace k \mid k \in \mathcal{B}, \; \boldsymbol{v}_k^\top \boldsymbol{v}_i \geq \gamma \rbrace$
$\mathcal{Q}(j) = \lbrace k \mid k \in \mathcal{B}, \; \boldsymbol{v}_k^\top \boldsymbol{v}_j \geq \gamma \rbrace$
두 sequence는 어떤 데이터($i$ or $j$)에 대해 batch 내의 모든 text와 비교하여 유사도가 $\gamma$ 이상인 데이터만 모아둔 sequence이다. ($\gamma = 0.9$)
위 식에서 $\tau$는 negative한 외부 지식에 대해 penalty를 제어하는 파라미터이다.
위 Objective로 다양한 실험 결과, Pretrained 모델의 Image/Text Encoder는 freeze하고, learnable한 gated 모듈을 Image Encoder에 추가하였을때 최적의 성능을 보였다고 한다.
3-4. Discussions with Data-Centric Methods
이 섹션에서는 대부분의 연구가 Network Achitecture, Train Objective, Model Scaling up 등 모델 중심적인 방법에 치중되어 있음을 언급한다. Data centric, 즉 데이터 중심 기법은 덜 탐구되고 있으며 REACT가 검색 argument 방식을 통해 데이터 gap을 메우고 기존 Data centric 패러다임과의 연결고리를 구축한다고 언급한다.
다음 2가지 기법과 비교하며 REACT가 가진 고유한 특징을 알아보자
K-LITE
- Knowledge source
- K-LITE는 WordNet, Wikitionary의 text 형태의 상식을 사용하여 language supervision을 보강한다.
- REACT는 Web scale의 Image-Text 데이터를 사용한다.
- 목표
- K-LITE는 structural human knowledge을 사용해서 Visual 모델의 generality를 향상시키는 것이 목적이다.
- REACT는 task instruction augmentation을 사용하여 Visual 모델의 커스터마이징 능력을 향상시키는 것을 목표로한다. (task-level transfer)
Self-Training
Knowledge source & Process
Self-Training은 teacher model의 “dark knowledge”를 활용하여 pseudo-label을 생성한다..
REACT는 Web scale의 Image-Text 데이터를 사용하여 보다 더 풍부한 의미를 지닌 데이터를 사용할 수 있다.
REACT와 self-training은 서로 도움이 된다.
- Self-Training은 REACT의 retrieval-augmented pool에서 시작할 수 있으며,
- REACT는 self-training에서 얻은 pseudo-label을 사용하여 추가적으로 supervision을 얻을 수 있다.
Experiments
실험의 목적은 다음과 같다.
- Task transfer에서 retrieval-augmented image-text knowledge가 지닌 장점 확인
- locked-text gated Image Encoder와 기존 방법 비교
- 하위 task의 train 데이터가 포함되는 full/few-shot에도 적용 가능한가?
실험은 Image classification과 Image-Text retrieve 2가지로 모델을 평가한다.
zero-shot task transfer에 대해 ImageNet 데이터셋으로 모델을 평가하고 추가적으로 ELEVATER를 사용하여 평가를 진행하였으며 Image-Text retrieve 평가는 MSCOCO와 Flickr 데이터셋을 사용하였다.
ELEVATER는 20개의 데이터셋을 포함한 open-set image classification benchmark이다.
zero-shot transfer는 타깃 task의 이미지를 전혀 사용하지 않아야 하지만, CLIP과 같은 Web-scale 데이터로 학습한 모델은 위키피디아나 WordNet의 단어가 추가되있어서 ImageNet 데이터셋의 일부가 포함되어 있을 것이라 주장한다.
4-1. Image Classification
ImageNet-$1K$ - Zero-shot
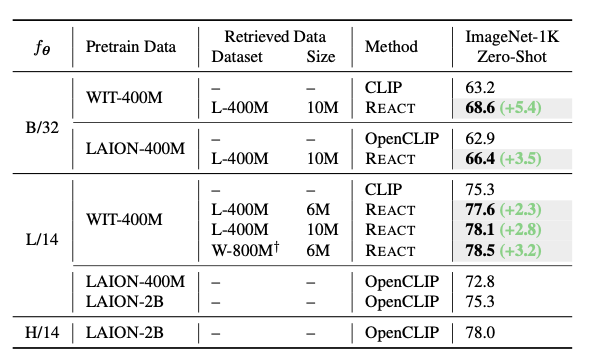
위 표에서 Retrieved Data의 왼쪽은 base 데이터셋, 오른쪽 Size는 검색된 Data의 개수이며 CLIP/OpenCLIP을 REACT로 커스터마이징한 결과를 비교하였을 때, 향상된 성능을 확인할 수 있다.
다음은 실험을 통해 얻은 3가지 특징이다.
: 자체 retrain 데이터 활용
REACT는 pretrain 데이터인 LAION-400M 에서 10M(천만)개의 관련 Image-Text 쌍을 활용하여 성능을 향상시켰다.
이는 REACT가 target domain adaption 능력이 보다 좋음을 알 수 있으며, 새로운 데이터 없이도 커스터마이징이 가능하다.
효율적인 새로운 Image-Text source 탐색
CLIP ViT-L/14 모델에 10M개의 관련 Image-Text 데이터를 활용하여 78.1%의 성능을 달성했으며, 이는 다른 backbone 모델들보다 뛰어난 성능을 보임을 알 수 있다.
이를 통해 REACT가 도메인 관심 분야에서 더 효율적인 성능 향상 방법임을 보여줍니다.
Retreival pool 확장에 따른 성능 향상
REACT를 800M(8억)개 이상의 Image-Text로 구성된 Web에서 자체적으로 수집한 데이터셋에 적용했다.
6M개의 관련 쌍을 활용하여 78.5%의 성능을 달성했으며, LAION-400M 데이터셋의 6M개 쌍보다 0.9% 향상되었다.
이는 REACT가 더 큰 Retreival pool을 활용할수록 성능이 향상된다는 것을 알 수 있으며, 이는 Web Image-Text 데이터베이스의 지속적인 증가를 REACT는 효율적으로 활용할 수 있음을 예측할 수 있다.
ImageNet-$1K$ - Low-Shot
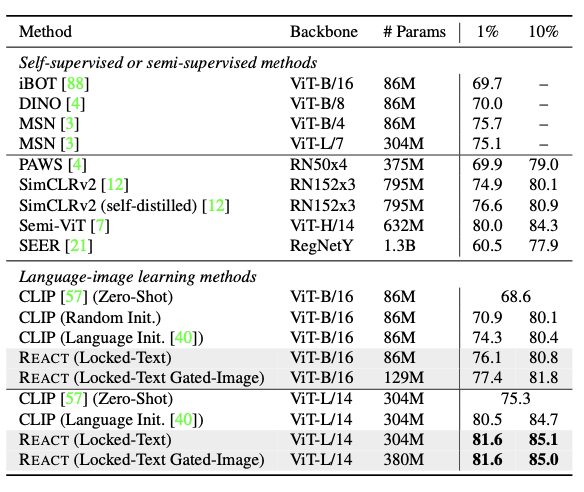
Train 데이터에서 원하는 task의 label을 1% 혹은 10%로 설정하여 low-shot 성능을 체크하였다.
linear head를 language-augmented initialization하여 CLIP ViT-B/16모델의 1% low-shot 성능을 향상시켰으며, 모델을 ViT-L/14로 확장하면 80.5%를 상성하며 SOTA와 동등한 수준이 된다. 여기서 REACT 커스터마이징을 통해 SOTA를 달성하였으며, 10% label 역시 마찬가지이다.
Zero/ Few/ Full-Shot on ELEVATER
ELEVATER의 Image Classification in the wild(ICinW) 벤치마크를 사용하여 Vision task에 대한 성능을 평가한다.
ICinW는 여러 도메인의 20개의 dataset으로 구성되며 총 1151개의 class를 가지고 있다.
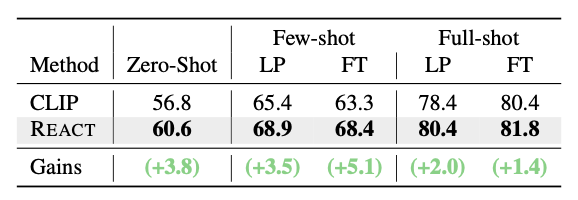
위 표는 10M개의 Image-Text 데이터로 REACT 커스터마이징을 수행하고 ELEVAVTER 벤치마크로 zero-shot, few-shot, full-shot 성능을 평가한 것이다.
REACT는 zero-shot에서 3.8%의 성능 향상을 보이며 해당 process의 효과를 입증하였으며, Few/Full-shot의 Linear Probing, Fine-tuning 부분에서 일관된 성능 향상을 보였다.
Analysis
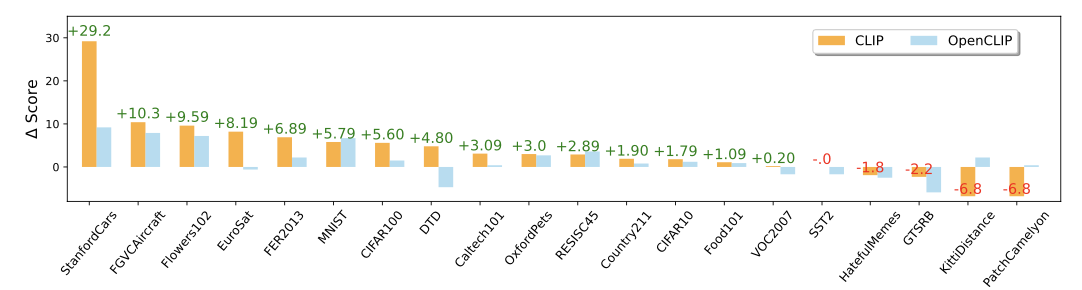
위 사진에서 ICinW의 20개의 데이터셋에서 성능을 비교한 결과이다. 눈에 띄게 성능이 향상된 StanfordCars와 FGVC Aircraft의 경우, 아래와 같이 관련된 Image-Text 데이터가 LAION-400M 데이터셋에서 검색될 수 있었기 때문이다.
K-LITE는 이 데이터셋의 지식들이 Wiktionary에서 추출되지 않았기 때문에 실패하였다. 이를 통해 특정 Domain knowledge과 시각적인 knowledge이 필요하다는 것을 알 수 있다.
Limitations
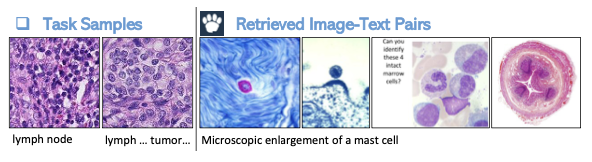
위 그래프에서 볼 수 있듯이 암세포 인식 벤치마크인 PatchCamelyon 데이터셋에서는 성능이 하락한다. 아래에서 보듯이, 검색된 이미지들은 PatchCamelyon 데이터셋과 다른 시각적 분포를 보인다.
이러한 분석을 통해 Image-Text knowledge 검색이 모델의 성능 향상에는 영향을 미치지만, 특정 domain에서의 검색 품질이 보장되어야한다는 것을 알 수 있다.

4-2. Image-Text Retrieval
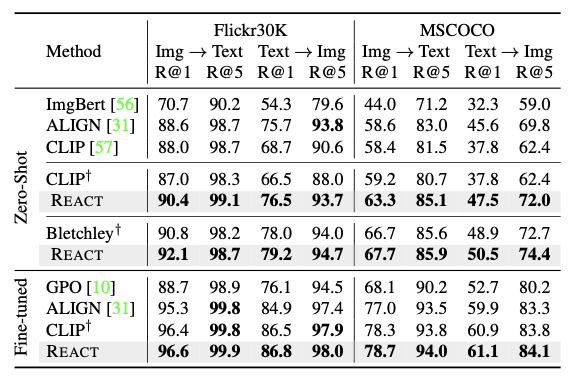
REACT의 Generality를 평가하기 위해 Flickr30K, MS COCO 데이터셋에서 zero-shot, full-shot의 Image-Text Retrieval task를 수행한다.
표준 Image-Text contrast Objective를 사용하였으며, $336*336$의 입력 resolution, CLIP-L/14를 사용한다.
위 표에서 볼 수 있듯이, REACT는 Flickr30K, MSCOCO에 대한 zero-shot, full-shot Retrieval 모두에서 일반적인 CLIP에 비해 성능이 향상된다.
- Image-to-Text, Text-to-Image 검색 모두에서 성능이 향상되었으며, Fine-tuning 후 에도 성능이 향상되었다.
- 8억 6400만개의 파라미터가 있는 Bletchley에서도 향상된 성능을 보이는 것으로 보아, REACT가 retrieval task에서 모델 size에 따라 확장됨을 알 수 있다.
4-3. Dense Prediction Tasks
REACT는 Image Constrast Loss로 optimize되어있지만, Dense prediction task(obeject detection, semetic segmentation)에서도 효과적이다.
Object Detection
SOTA인 ResNet50와 ViT-B/16를 backbone으로 한 RegionCLIP으로 2가지 실험을 진행한다.
- Ground-Truth(GT), Region Proposal Networks(RPN)를 사용한 Zero-shot Inference
- MSCOCO 데이터셋으로 open-vocabulary Object Detection
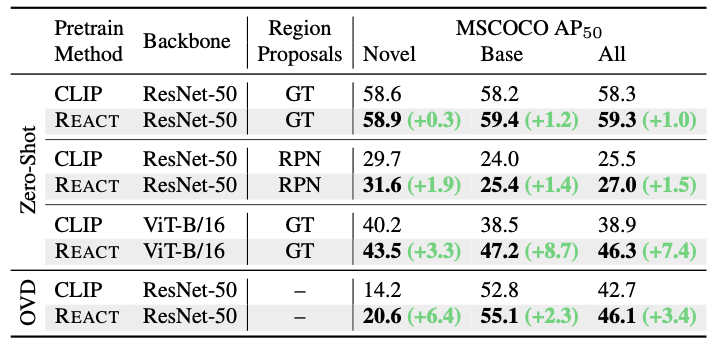
위 표를 보면, REACT는 모든 setting에서 CLIP보다 일관되게 성능이 향상됨을 확인할 수 있다. 또한, REACT에서 사용된 데이터는 웹에서 검색되어 무료로 제공되므로, COCO Image-Text pair를 사용할 필요가 없다.
따라서 REACT 커스터마이제이션은 Objcet Detection 모델의 성능을 향상시키고, 비용 효율적인 방법으로 unseen 클래스에 대한 일반화 능력을 높일 수 있음을 시사한다.
Sementic Segmentation
추후 업데이트 예정