[Paper Review with Code] ResCLIP: Residual Attention for Training-free Dense Vision-language Inference
[논문 리뷰] ResCLIP: Residual Attention for Training-free Dense Vision-language Inference
ResCLIP: Residual Attention for Training-free Dense Vision-language Inference
Yuhang Yang∗, Jinhong Deng∗, Wen Li, Lixin Duan
CVPR 2025
CLIP의 마지막 self-attention 층이 공간 정보를 제대로 반영하지 못해 dense prediction (예: semantic segmentation)에 약하다는 기존 한계를 지적하고, 이를 개선하기 위한 모듈을 제안한다.
Dense prediction : 이미지 내 어디에 어떤 객체가 있는지 예측
CLIP은 이미지 전체에 대한 global feature를 뽑아서 이미지가 “고양이 사진”인지 “자동차 사진”인지를 예측
즉, CLIP의 마지막 self-attention은 대체로 공간 불변(spatial-invariant)적인 특성을 가지며 마지막 attention에서의 각 patch 간 관계가 “어디 있는지”에 별로 민감하지 않음
Introduction
CLIP 기반 모델은 대규모 Image-Text 쌍에 대한 contrastive learning을 통해 학습되기 때문에 open-vocabulary 인식 능력이 매우 뛰어나지만, semantic segmentation과 같은 dense prediction에는 여전히 한계가 존재한다.
이를 위해 CLIP을 픽셀-level annotation으로 fine-tuning하는 방법이 제안되었지만, 비싼 annotation 비용이 들 뿐만 아니라, 학습 데이터에 대한 편향 때문에 CLIP의 generalization 능력을 저해한다.
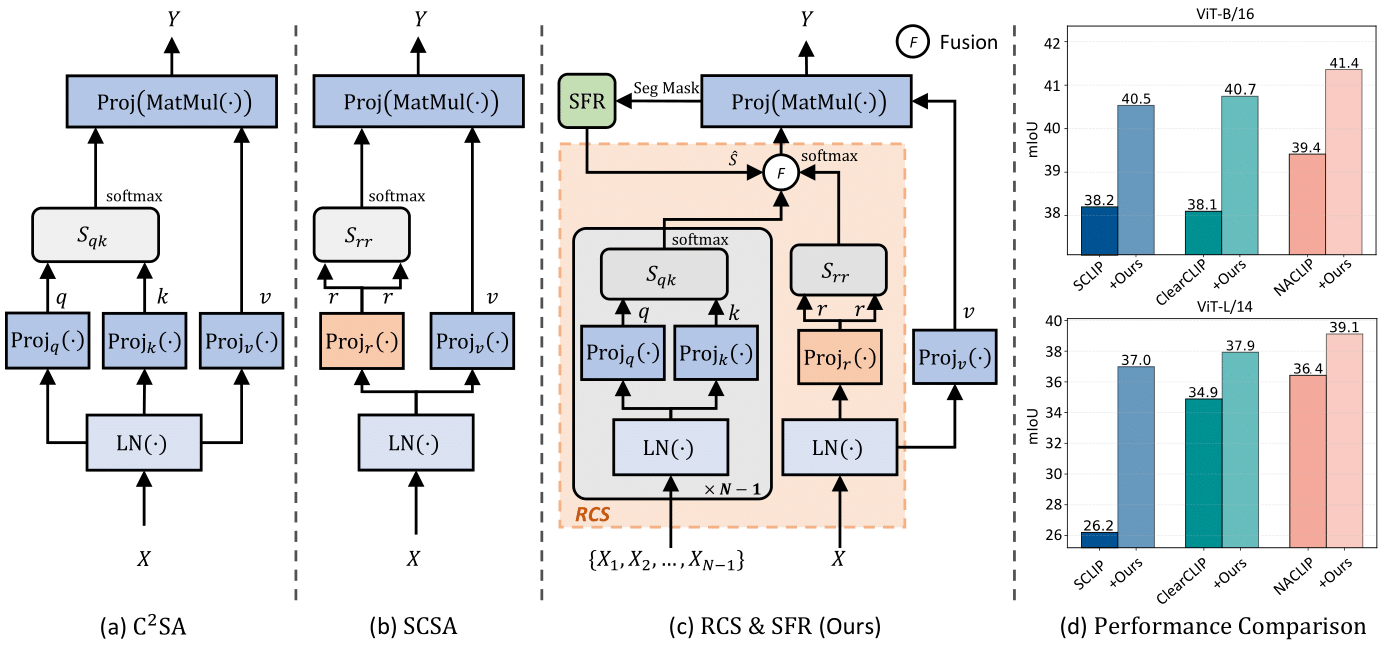
최근 연구들은 이러한 dense prediction의 한계를 CLIP의 마지막 블록의 self-attention layer에 원인이 있다고 보고 있으며, 기존의 query-key attention을 query-query 또는 key-key 기반의 self-correlation self-attention (b, SCSA)으로 수정함으로써 성능 향상을 달성해왔다. 하지만 이는 원래 CLIP의 공간적 대응 관계를 포착하는 cross-correlation attention (query-key 기반의 cross-correlation attention, $\text{C}^2\text{SA}$, (a))의 속성을 간과한다.
SCSA
CLIP의 마지막 self-attention에서 사용되는 query-key ($qk^\top$) 대신, query-query ($qq^\top$) 또는 key-key 곱 ($kk^\top$)을 사용하여 같은 종류의 정보끼리만 비교하는 방식
예: “이 패치의 key는 이 패치의 key와 얼마나 비슷한가?”
같은 종류끼리의 유사도를 기반으로 하므로, local하게 비슷한 부분에 집중할 수 있게 된다.
→ 즉, spatial-covariant, 즉 위치에 따라 attention이 달라지는 성질을 가지게 됨
단점
같은 종류끼리만 비교하기 때문에 다양한 패치 간의 의미 있는 관계 (예: 고양이 귀 ↔ 고양이 몸통)를 잘 포착하지 못할 수 있음.
실제로 CLIP의 원래 attention 구조인 query-key $\text{C}^2\text{SA}$는 다양한 공간 위치 간의 복합적이고 비대칭적인 관계를 잡아낼 수 있는 구조
예: “이 패치(query)가 저 패치(key)와 어떤 의미론적 대응이 있는가?”
저자들은 “attention이 pixel-level에서 $\text{C}^2\text{SA}$가 class-specific한 dense representation을 학습할 수 있을 것”이라는 점에서 새로운 질문을 제시한다.
“CLIP이 pixel-level supervision 없이도 $\text{C}^2\text{SA}$의 localization 특성을 얻을 수 있을까?”
이를 위해 CLIP의 모든 layer에서 $\text{C}^2\text{SA}$를 분석하였고, 마지막 layer를 제외한 나머지 layer들에서는 attention이 localization 특성을 보인다는 사실을 발견한다.

위 그림에서 보듯이 마지막 layer의 attention은 공간적으로 균질하지만, 다른 layer들은 class-specific 특성과 localization 특성을 보인다. 예를 들어 “고양이(cat)“의 경우, 중간 layer의 attention은 다른 고양이 영역으로 집중되는 것을 볼 수 있다.
이를 바탕으로 training-free 방식의 새로운 2가지 모듈이 포함된 ResCLIP을 제안한다. (c)
- Residual Cross-correlation Self-attention (RCS)
- CLIP의 중간 layer에서의 $\text{C}^2\text{SA}$를 추출하여 마지막 블록의 attention에 residual 방식으로 결합
- 이러한 cross-correlation은 공간 정보를 재구성하여, CLIP의 잠재된 localization 능력을 끌어낸다.
- Semantic Feedback Refinement (SFR)
- semantic segmentation map을 feedback으로 사용하여 attention score를 조정
- 동일한 semantic category에 속하는 영역에 집중하고 지역적 일관성(local consistency)을 명시적으로 강화
- residual 방식으로 결합
(d)를 보면 ResCLIP을 SCLIP, ClearCLIP, NACLIP과 결합했을 때 최대 13.1% mIoU 향상이 이루어졌음을 볼 수 있다.
Method
1. Preliminary
Vision Encoder
CLIP은 Text와 align하기 위해 Image Encoder로 ViT 구조를 사용한다.
$H \times W \times 3$ 이미지를 $P \times P$ 크기의 patch $n$개로 분할하며 각 patch는 임베딩될 때 positional 임베딩도 포함된다. 각 layer의 입력은 다음과 같이 visual token sequence로 표현된다.
\[X = \{x_{\text{cls}}, x_1, x_2, …, x_{n}\} \in \mathbb{R}^{(1+n) \times d}, \;\; n = hw,\;\; \left\{\begin{matrix} h = H/P \\ w= W/P \end{matrix}\right.\]여기서 $x_{\text{cls}}$는 전체 이미지를 대표하는 class token이며, sequence는 여러 개의 multi-head self-attention layer를 거쳐 최종 representation으로 변환된다.
Self-Attention
Transformer 인코더의 핵심은 self-attention이며, 이는 이미지 patch들 간의 관계를 포착하는 데 사용된다.
여기에서는 설명의 단순화를 위해 single-head attention만을 고려한다.
입력 $X$에 대해 $q,k,v$를 생성
\[q,k,v = \text{Proj}_{q,k,v}(\text{LayerNorm}(X)) \tag{1}\]이를 사용하여 Attention score를 계산 (이미지 패치들 간의 전역적 구조 관계)
\[S_{qk} = \frac{qk^\top}{\sqrt{d_k}} \tag{2}\]softmax 함수를 통해 Attention map을 계산
\[\text{Attn}(S_{qk}) = \text{softmax}\left(\frac{qk^\top}{\sqrt{d_k}}\right) \tag{3}\]
Dense Vision-language Inference
CLIP은 대규모 Image-Text 쌍에 대해 contrastive loss으로 학습되었기 때문에, open-vocabulary 이미지 인식에서 좋은 성능을 보인다.
Text Encoder는 Text representation $X_{\text{text}} = \lbrace t_1, t_2, …, t_c\rbrace$를 생성하며, 이는 각 class의 텍스트 설명에 대응한다.
CLIP은 Text와 Image feature 간 유사도(cosine similarity)를 계산하여 class를 예측한다.
이를 dense prediction으로 확장하기 위해 $X_{\text{text}}$와 Dense visual token $X_{\text{dense}} = \lbrace x_1, x_2, …, x_{n}\rbrace \in \mathbb{R}^{n\times d}$와 유사도를 계산하여 각 pixel에 대한 예측 class $\mathcal{M}$을 구한다.
\[\mathcal{M} = \text{arg}\max \text{cos}(X_\text{dense}, X_\text{text})\]하지만 CLIP은 localization 능력이 부족하기 때문에 이렇게 얻은 semantic segmentation 결과는 노이즈가 많고 정확도가 낮다.
2. ResCLIP
본 논문은 CLIP의 중간 layer의 self-attention은 class-specific한 특징과 localization 특성을 가진다는 점에서 착안하여 새로운 training-free 방식인 ResCLIP을 제안한다.
ResCLIP은 CLIP의 중간 layer로부터 C2SA를 추출하여, 마지막 layer의 attention을 재구성한다.

즉, 중간 layer의 cross-correlation 정보를 통해 공간 정보를 재구성하여 semantic-related 영역에 attention을 집중시킨다.
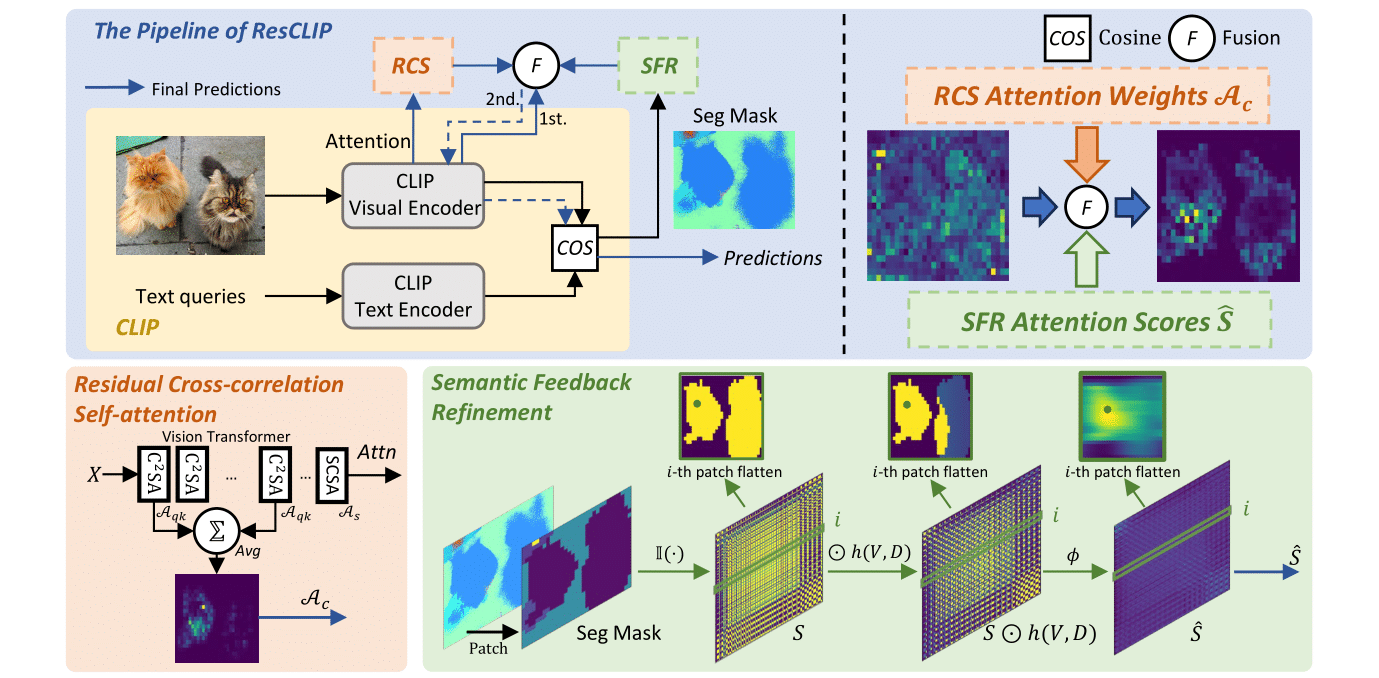
Residual Cross-correlation Self-attention (RCS)
RCS는 CLIP의 중간 layer의 attention($\text{C}^2\text{SA}$)을 가져와서, 기존 마지막 layer의 attention(SCSA)과 residual 방식으로 결합한다.
즉, local patch 구조를 반영한 attention(SCSA)와 cross-feature 관계를 반영한 중간 attention($\text{C}^2\text{SA}$)을 섞는 구조다.
중간 layer들에서 $\text{C}^2\text{SA}$를 추출한 뒤, 평균을 계산하는 방식으로 Attention을 합친다.
각 $i$번째 layer의 $\text{C}^2\text{SA}$ attention인 $\text{Attn}(S_{qk})$을 $\mathcal{A}^i_{qk}$ 라 할 때,
\[\mathcal{A}_c = \frac{1}{N}\sum^e_{i=s}\mathcal{A}^i_{qk}\]이 결합된 attention $\mathcal{A}_c$ 는 마지막 layer의 정보를 더 풍부하게 구성하며, RCS attention은 다음과 같이 계산된다.
\[\mathcal{A}_{rcs} = (1-\lambda_{rcs}) \cdot \mathcal{A}_s + \lambda_{rcs} \cdot \mathcal{A}_c\]- $\mathcal{A}_s$: 기존 SCSA (query-query, key-key 기반 attention)
- $\mathcal{A}_c$: 중간 layer에서 얻은 $\text{C}^2\text{SA}$ (query-key 기반 attention)
- $\lambda_{rcs}$: 두 attention 간 조절 parameter
$\mathcal{A}_{rcs}$는 local patch 구조($\mathcal{A}_s$)와 cross-feature 관계($\mathcal{A}_c$)에 대한 정보를 함께 가지고 있다.
Semantic Feedback Refinement (SFR)
RCS 모듈이 SCSA와 $\text{C}^2\text{SA}$정보를 모두 가지고 있다 해도, pixel-level의 supervision이 없기 때문에 완전한 attention이 아니다.
왜?
2가지 정보가 합쳐진 Attention이지만 여전히 픽셀 수준에서 “정답”이 뭔지 알려주는 supervision이 없다는 것이다.
즉, “이 픽셀은 고양이”, “저 픽셀은 의자” 같은 정확한 정보가 없기 때문에, attention이 제대로 조정됐는지 확인할 수가 없음
NACLIP은 이웃 patch에 attention를 집중하는 prior를 attention에 적용하기도 했지만, 객체의 형태가 다양한 경우 부정확한 정보가 추가될 수 있다.
왜?
NACLIP은 patch 주변을 강조하는 방식으로 attention을 수정
예: 어떤 patch가 “고양이 귀”라면, 그 주변도 “고양이일 가능성”이 높기 때문에 같이 강조
이를 Gaussian 커널을 사용해서 주변에 부드럽게 attention 값을 분포시켜 수행
하지만, Gaussian 커널은 모든 방향으로 동일하게 퍼져나가기 때문에 객체의 형태가 복잡하거나 길쭉한 경우 의미없는 영역까지 강조하는 경우가 생김
따라서 Semantic Feedback Refinement (SFR) 모듈을 제안한다.
이는 RCS로부터 얻은 segmentation map을 feedback으로 사용하여, attention을 semantic하게 보정하고, 동시에 local consistency를 유지한다.
SFR 모듈의 동작은 다음을 반복한다:
- RCS 모듈로부터 생성된 segmentation map을 하나의 피드백으로 삼는다.
- 이 segmentation map을 사용하여, 마지막 layer의 attention score를 다시 조정한다.
attention score $S \in \mathbb{R}^{n \times n}$는 각 요소 $S_{ij}$가 $i$ 번째 patch가 $j$ 번째 patch에 주는 attention의 크기를 의미한다.
여기서, 하나의 patch에 대한 attention row vector $S_i \in \mathbb{R}^{n}$는 다음과 같이 semantic feedback을 통해 조정된다:
\[S^i_{m,n} = \mathbb{I}(\mathcal{M}_{i^{\prime},j^{\prime}} == \mathcal{M}_{m,n})\]- $M \in \mathbb{R}^{hw}$ : segmentation map
- $(i^{\prime}, j^{\prime})$ : $i$ 번째 row attention이 대응하는 grid 상의 위치 ($i$를 2D 인덱스로 변환)
- $\mathbb{I}(\cdot)$ : indicator 함수로, 두 위치의 class가 같으면 1, 다르면 0을 반환
즉, 같은 semantic label을 가진 위치에만 attention이 유지되도록 필터링한다.
하지만 이렇게만 하면 locality가 무시될 수 있다. 그래서 같은 class를 가진 patch 중에서 인접한 위치는 강조하고, 떨어져 있는 위치는 감쇠(decay)시키는 보정을 수행한다.
\[h(V, D) = V + (1 - V) \cdot D\]- $V \in {0, 1}^{hw}$ : source patch로부터 연결 가능한 위치에 1, 그렇지 않으면 0
- $D \in \mathbb{R}^{hw}$ : 거리 기반 decay 함수
감쇠 함수 $D(p, q)$는 Chebyshev 거리로 정의되며, 다음과 같다: ($p,q$는 patch의 좌표)
\[D(p, q) = \exp\left(-\frac{d(p, q)}{\max d(\cdot, \cdot)}\right)\]\(d(p, q) = \max(|p_x - q_x|, |p_y - q_y|)\) $d(p, q)$는 patch p와 q 간의 좌표 거리이며, Chebyshev 거리는 체스판에서 왕이 한 번에 갈 수 있는 최대 거리 개념이다.
이러한 decay 함수를 Attention Score에 적용한다.
\[\hat{S}^i = \phi(S^i \odot h(V, D))\]- $\phi$ : 1D Gaussian 커널을 사용한 smoothing 함수
- $\odot$ : element-wise 곱
이 smoothing 연산은 attention score의 일반화 능력을 향상시키며, Transformer의 self-attention이 가진 row-independence 성질은 그대로 유지된다.
각 row에 위 연산을 적용하여 전체 Attention score map $\hat{S}$를 얻고, 이를 원래 Attention score와 결합하여 최종 SFR attention score를 계산한다:
\[S_r = (1 - \lambda_{\text{sfr}}) \cdot S_s + \lambda_{\text{sfr}} \cdot \hat{S}\]- $S_s$ : 기존 SCSA attention score
- $\lambda_{\text{sfr}}$ : 두 score 간의 가중치 조절 파라미터
마지막으로, 이 attention score를 softmax 처리하여 $\mathcal{A}_{\text{sfr}}$를 만든 후, RCS attention과 결합하여 ResCLIP의 최종 attention을 완성한다:
\[\mathcal{A}_{\text{ResCLIP}} = (1 - \lambda_{\text{rcs}}) \cdot \mathcal{A}_{\text{sfr}} + \lambda_{\text{rcs}} \cdot \mathcal{A}_c\]- $\mathcal{A}_c$: 중간 layer의 $\text{C}^2\text{SA}$ attention
- $\lambda_{\text{rcs}}$: RCS의 가중치
이를 통해 ResCLIP의 attention은 다음 세 가지 정보를 종합하게 된다:
- SCSA (query-query, key-key 기반)
- spatial-covariant한 local 정보를 제공
- 각 패치 주변의 유사한 패치들과의 상호작용을 통해 위치에 민감한 지역적 특징을 포착
- 중간 layer의 C²SA (query-key 기반)
- CLIP의 중간 layer에서 추출한 attention으로, class-specific한 공간적 대응 관계(spatial correspondence)를 포착
- 서로 다른 위치에 있지만 같은 semantic 객체에 속하는 패치들 간의 상호작용을 강화
- SFR
- 초기 segmentation 결과를 피드백으로 활용하여, 같은 semantic class에 속하고 인접한 영역끼리의 attention을 강화
- 이를 통해 semantic 일관성과 지역적 집중(local consistency)을 동시에 확보한다.
Experiments
1. Set up
Datasets
open-vocabulary semantic segmentation을 위한 8개의 표준 벤치마크 데이터셋에서 평가를 수행한다.
- 배경 클래스가 없는 데이터셋
- PASCAL VOC 2012 (VOC20)
- PASCAL Context59 (Context59)
- COCO Object (Object)
- 배경 클래스가 있는 데이터셋
- PASCAL VOC 2012 (VOC21)
- PASCAL Context60 (Context60)
- COCO-Stuff (Stuff)
- Cityscapes
- ADE20K-150
Baseline
OVSS(Open-Vocabulary Semantic Segmentation) 방법들과 비교한다.
- Training-free 방식
- CLIP baseline, MaskCLIP, ReCo, CLIPSurgery, GEM
- SCLIP, NACLIP, ClearCLIP
- 약한 감독 방식 (Weakly-supervised)
- GroupViT, CoCu, TCL, SegCLIP, OVSegmentor, PGSeg
그중에서도 SCLIP, NACLIP, ClearCLIP은 특수한 attention 구조를 가진 대표 모델로, 이들과의 결합을 중점적으로 평가한다.
Implementation details
- 계산 비용이 높은 후처리 기법(PAMR, DenseCRF) 제외
- ImageNet의 prompt 사용
- 기본 backbone : ViT-B/16, ViT-L/14 실험 결과도 제시
- 추가 학습 없는, training-free 방식
- Metric : mIoU (mean Intersection over Union)
2. Main Results
Quantitative results
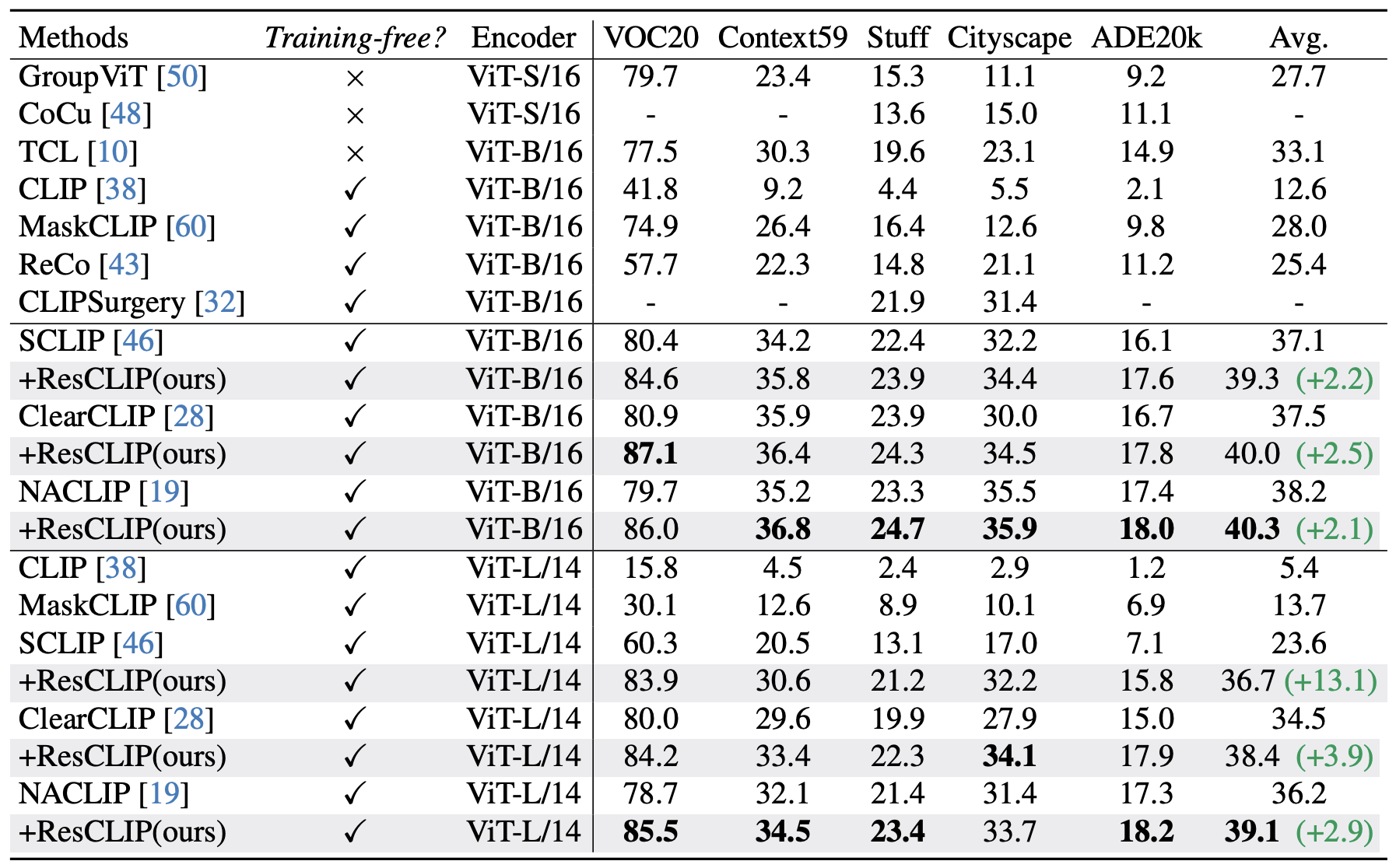
위는 배경 class가 없는 데이터셋에서 다양한 open-vocabulary segmentation 모델의 성능을 요약한 것이다.
ResCLIP은 SCLIP, ClearCLIP, NACLIP과 결합 시 모두에서 성능이 향상되었으며, 특히 NACLIP과 결합할 경우, 기존 Week-supervised 방식조차도 뛰어넘는 성능을 달성하였다.
ResCLIP은 plug-and-play 구조이기 때문에 기존 방식에 쉽게 통합될 수 있으며, 모든 데이터셋에서 일관된 개선 효과를 보이며 높은 가능성을 입증한다.
또한, 기존 방식들은 ViT-L/14로 변경 시 평균 2% 이상의 성능 하락이 발생한다.
예: SCLIP은 13.5% mIoU 하락.
그러나 ResCLIP을 결합하면 이 성능 저하가 크게 완화됨을 확인하였다.
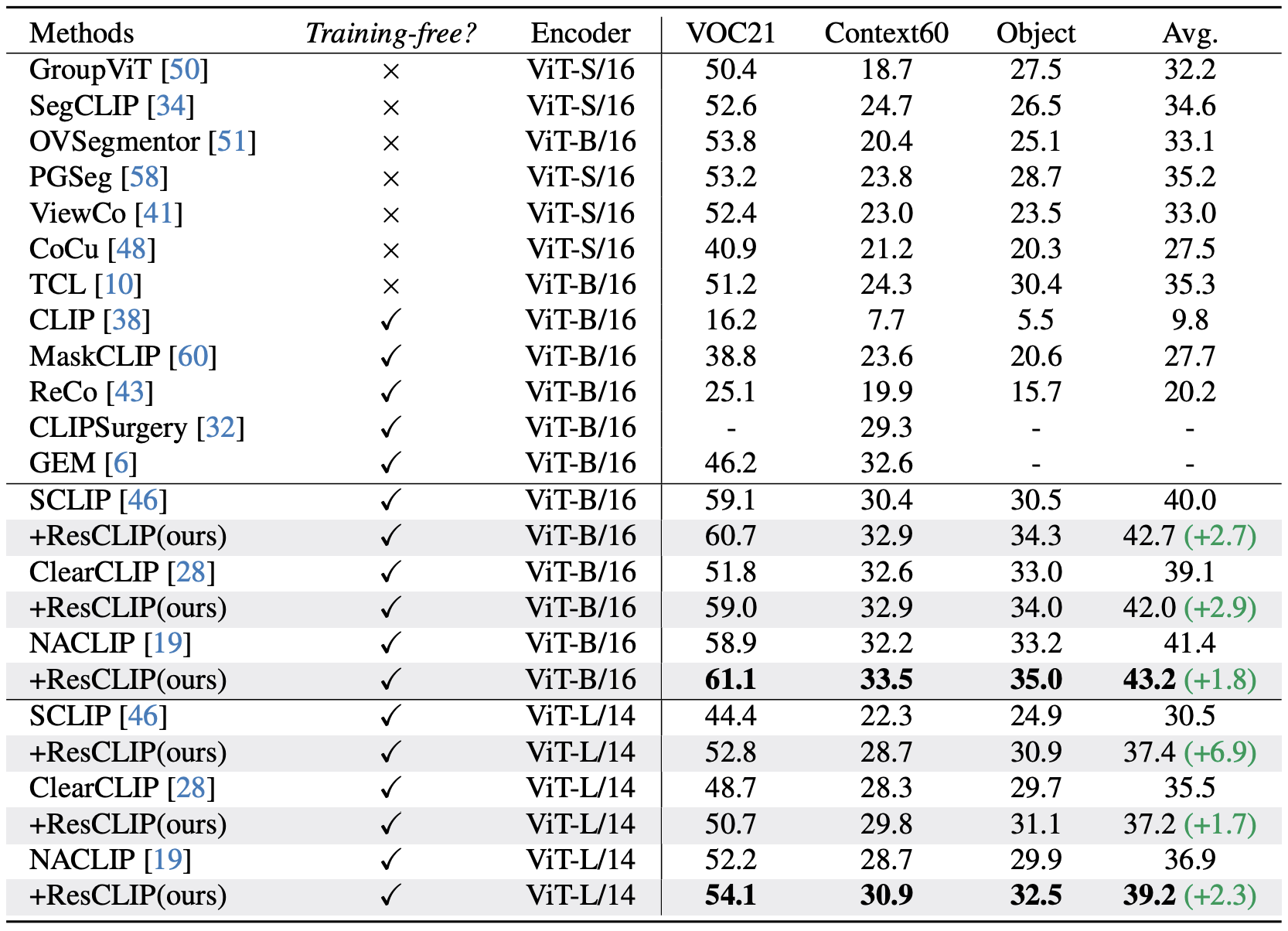
위는 배경 class가 있는 데이터셋에서의 평가 결과이다. 역시나 ResCLIP은 일관된 성능 향상을 보인다.
NACLIP + ResCLIP (ViT-B/16) → 43.2% mIoU,
이는 Week-supervised 방식인 GroupViT을 넘어서는 SOTA 성능이며, ViT-L/14 사용 시에도 여전히 뚜렷한 향상이 유지되었다.
이 결과는 ResCLIP이 CLIP 마지막 층의 attention의 노이즈를 효과적으로 감소시킨다는 것을 검증한다.
Qualitative results.

위는 ResCLIP과 기존 training-free 방법들(SCLIP, NACLIP, ClearCLIP)의 segmentation 결과를 비교한 것이다.
ResCLIP은 객체의 내부 영역을 더 잘 포착하고, 중앙이 비어 있는 현상 없이 더 정밀한 마스크를 생성한다.
- VOC 및 COCO Object 데이터셋에서 객체 내부의 예측 품질 향상이 명확하다.
- 특히 ADE20K에서는 NACLIP보다 더 명확한 경계와 클래스 구분을 보여준다.
Experimental Analysis
Ablation Study
NACLIP + ViT-B/16을 기준으로 ablation 실험을 수행한다.
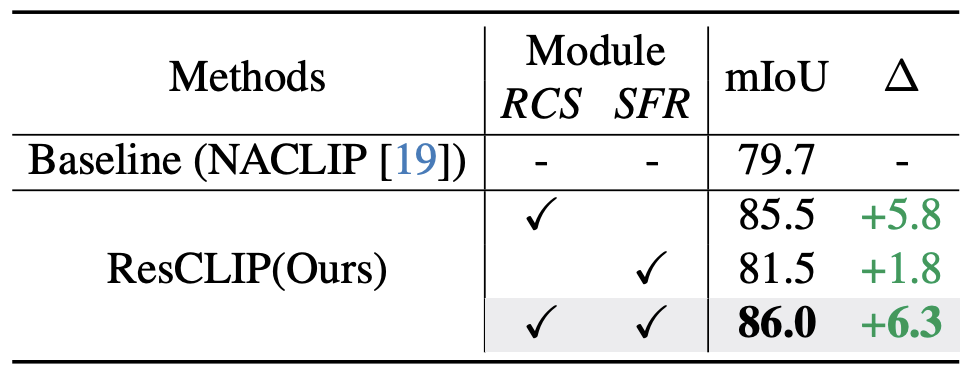
RCS만 적용
- mIoU : 79.7% → 85.5%
- 중간 layer의 query-key attention 정보를 마지막 attention map에 포함시키는 것이 효과적
SFR만 적용
- mIoU : 79.7% → 81.5%
- SFR이 semantic 유사 영역 간의 attention을 강화하면서 local 공간 일관성도 잘 유지
RCS + SFR 결합
- mIoU가 86.0%로 증가(총 6.3% 향상)
→ 두 module이 상호 보완적(complementary)임을 증명
Sensitivity analysis of hyper-parameters.
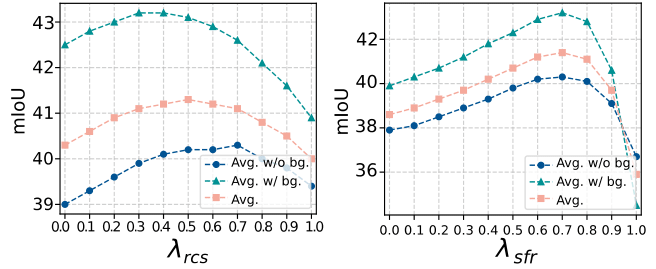
에서는 두 주요 하이퍼파라미터인
- $\lambda_{\text{rcs}}$ (중간 attention 결합 비율)
- $\lambda_{\text{sfr}}$ (semantic feedback 결합 비율)
에 대한 민감도 분석 결과를 보여준다.
- $\lambda_{\text{rcs}}$: 0.5에서 최적 성능을 달성
- $\lambda_{\text{sfr}}$: 0.7에서 가장 우수하며, 0.6~0.8 구간에서 안정적인 성능을 보인다
공통적으로 중간 값에서는 성능 향상, 극단적 값 (예: 1.0)에서는 성능 저하 경향을 보인다. 이러한 일관된 경향은 다양한 데이터셋에서도 유사하게 나타나며, ResCLIP이 다양하게 튜닝해도 안정적인 성능을 보장함을 의미한다.
Analysis of layer fusion strategies in RCS
RCS 모듈은 중간 layer의 attention을 평균하여 결합($\mathcal{A}_{qk}$)하는데, 이 attention 결합 방식을 두 가지로 비교한다.
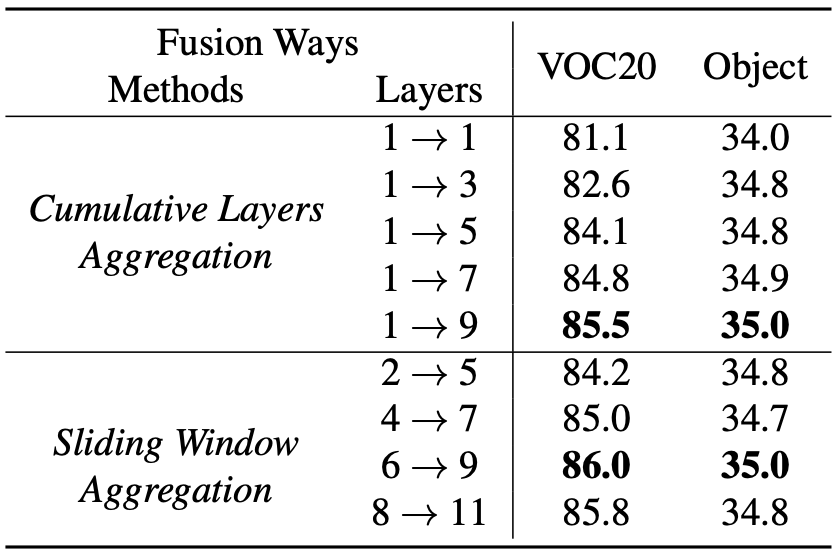
Cumulative Layer Aggregation (CLA)
첫 번째 layer부터 n번째 layer까지 누적해서 attention을 평균함
결과: 많은 layer를 포함할수록 성능이 향상
예: layer 1 → 9까지 포함하면 VOC20에서 85.5%, Object에서 35.0%
Sliding Window Aggregation (SWA)
4개의 연속된 layer를 슬라이딩 윈도우 방식으로 평균함
결과: 6 → 9 구간에서 최고 성능 달성
VOC20: 86.0%, Object: 35.0%
이 분석을 통해 다음 두 가지 결론을 얻을 수 있다:
- 중간 attention을 많이 활용할수록 성능이 향상
- 하지만 선택적이고 연속적인 구간(windowed aggregation)이 더 효율적인 성능을 낼 수 있음
Conclusion
ResCLIP은 training-free로 CLIP의 dense vision-language 추론 성능을 향상시키는 구조dㅣ다.
CLIP의 중간 layer attention이 class-specific features과 localization properties을 가진다는 사실을 발견하고, 두 가지 모듈을 설계한다.
Residual Cross-correlation Self-attention (RCS)
→ CLIP 중간 layer의 풍부한 공간 대응 정보를 추출
Semantic Feedback Refinement (SFR)
→ 같은 semantic 객체 영역에 집중하고, 로컬 일관성을 보존하며 마지막 attention을 재구성
이 두 모듈은 서로 보완적으로 작용하며, CLIP의 마지막 attention layer를 semantic하게 재구성할 수 있게 해준다.
광범위한 실험을 통해, 우리는 ResCLIP이 다양한 벤치마크에서 성능을 향상시키고, 다양한 backbone 및 기존 모델들과 결합 시에도 강력한 일반화 성능을 유지함을 보여주었다.
Code
RCS
1
2
3
4
5
6
if use_rcs:
# 6,7,8,9 (index: 5,6,7,8)
selected_attns = torch.stack([attn_map[i] for i in range(5, 9)])
attention_rcs = selected_attns.mean(dim=0)
else:
attention_rcs = None
중간 layer(6~9번째)의 attention map들을 평균내어 attention_rcs를 만든다.
이 attention은 마지막에 기존 attention에 residual로 더해진다.
custom_attn() 내부에서 attn_rcs_weights와 함께 attention score에 추가:
1
attn_weights = tau_attn_rcs * ((1 - lambda_attn_rcs) * attn_weights + lambda_attn_rcs * attn_rcs)
SFR
1
2
3
4
5
6
if use_sfr:
seg_logit_temp = self.create_logit_temp(...)
patch_logit_temp = self.create_patch_matrix(seg_logit_temp, n_patches, temp_thd=temp_thd)
attention_sfr = self.generate_attention_sfr(patch_logit_temp, n_patches, ...)
else:
attention_sfr = None
self.create_logit_temp: CLIP을 통해 segmentation logit 생성self.create_patch_matrix: 각 patch별 예측 class ID로 구성된 2D matrix 생성self.generate_attention_sfr- patch 간 semantic 관계에 기반한 attention matrix 생성
- 동일 class 여부 확인
- 중간에 연결된 path 여부 체크
- 거리 기반 decaying 및 Gaussian smoothing 적용
마찬가지로 custom_attn() 내부에서 attn_weights에 다음과 같이 적용:
1
attn_weights = tau_attn_sfr * ((1 - lambda_attn_sfr) * attn_weights + lambda_attn_sfr * attn_sfr)
Github에서 코드를 보면, SFR모듈이 RCS모듈보다 먼저 적용된다. 그 이유는 아래와 같다.
SFR은 segmentation logit으로부터 나온 semantic feedback이다. , “이 patch는 어떤 class일 가능성이 높은가”에 기반한 global semantic prior이다.
따라서 softmax를 적용하기 전에 attention을 semantic하게 형성하기 위해서 이 정보는 raw attention score인 $k·kᵀ$ 단계에서 먼저 적용되어야 한다.
그런 다음, softmax 함수로 attention을 확률 분포로 변환한다.
RCS(attn_rcs)는 중간 레이어에서 추출한 attention의 평균값으로, 이미 학습된 attention의 localization 능력을 일부 보존한 것으로 생각할 수 있다.
즉, 이미 semantic 방향으로 형성된 attention(SFR)을 중간 layer의 attention 기반으로 조정한다고 보면 된다.