[Paper Review] SAGAN - Self Attention GAN
[논문 리뷰] Self-Attention GAN
이번에는 Self-attention 기법을 GAN에 적용한 SAGAN에 대한 논문을 읽어볼까 한다.
기존의 GAN은 convolution에서 low-resolution feature map의 정보만을 활용해 high-resolution인 detail 요소를 생성한다. 하지만, SAGAN에서는 모든 feature map의 정보를 활용하여 detail 요소를 생성하며, $D$는 멀리 있는 아주 작은 detail까지 서로 일치하는지 확인할 수 있다.
Self-Attention을 적용한 GAN인 SAGAN은 이미지 생성분야에서 새로운 SOTA를 달성하였다.
✏️Introduction
이전 GAN들은 텍스쳐로 구분되는 class(하늘, 바다, 풍경 등)에는 좋은 성능을 보이지만, 복잡한 구조를 가진 class(강아지의 털은 잘 표현하지만 발은 잘 그리지 못함)에는 detail적인 부분에서 아쉬운 성능을 보였다. 이는 다른 이미지 영역의 dependency(종속성)를 modeling할 때 convolution에 의존하기 때문이다.
Convolution 연산을 할 때, receptive field는 local에 국한되기 때문에(데이터를 감지하는 영역이 작기 때문에) long range dependencies를 처리하기 위해서는 convolution layer를 깊게 쌓아 각 layer를 통과할 때마다 receptive field를 점차 확장시켜 넓은 영역에 대한 정보를 감지해야한다.
즉, 가벼운 모델로는 처리가 불가능하며, Optimization 알고리즘이 dependency를 감지하는 parameter값을 찾는 게 힘들어지며, 생소한 데이터에 대해 실패할 확률이 크다.
이러한 문제를 논문에서는 Self-Attention 기법을 활용하여 long range dependencies를 효과적으로 modeling하는 SAGAN을 제안한다. 어떤 위치에서의 반응을 모든 위치 feature의 가중치 합으로 계산하는데, weight나 attention vector의 계산은 매우 적은 비용으로 가능하다.
또한, network conditioning(조건)에 대한 insight를 적용시켰다. $D$에만 적용되었던 spectral normalization 기법을 $G$에도 적용시켜 성능을 향상시켰다.
Image-Net 데이터셋으로 실험한 결과, Inception score를 36.8에서 52.52로 높이고, Fréchet Inception Distance를 27.62에서 18.65로 줄여 새로운 SOTA를 달성하였다고 한다.
✏️Related Work : Attention
원래라면 넘어갔을 Related work section이지만, Attention Model을 GAN에 적용시킨 첫 논문이므로, 짚고 넘어가자
필자가 작년에 허술하게 Attention is all you need 논문 리뷰도 있다..
Attention
Attention은 ‘문장’을 더 잘 이해하기 위해 고안되었다. 사람은 문장을 이해할 때, 문장 중에서 중요한 단어들을 좀 더 강조하여 이해한다. 예를 들어,
“3일 전에 바지와 셔츠를 샀는데, 바지가 작아”
위 문장에서 문맥을 이해하기 위해 우리는 “바지”에 초점을 맞춘다. “셔츠”라는 단어가 들어가있지만, 문장에서 큰 의미를 차지하지는 않는다.
이와 같은 방식으로 인공신경망이 input sequence data의 전체 또는 일부를 되짚어 살펴보면서 어떤 부분이 의사결정에 중요한지, 판단하고 중요한 부분에 “집중”(Attention) 하는 방식인 Attention 메커니즘을 도입하게 된다.
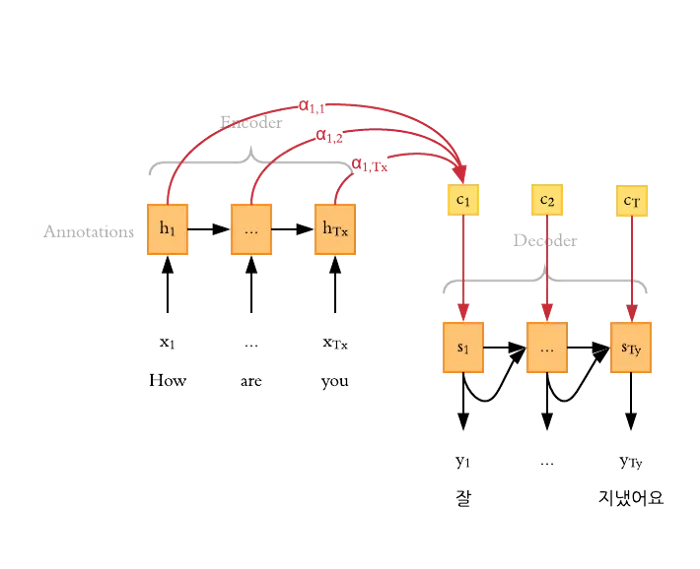
Input data에 대해 Decoder가 결과를 내기 위해 각 timestep마다 다음을 반복한다.
- Encoder가 어느 부분에 집중할지를 판단하기 위해 각 단어의 attention score를 계산한다.
- 이 attention score를 기반으로 가중치가 반영된 Attention output을 생성한다.
- 2번의 결과와 Decoder의 hidden layer를 사용해 이번 step의 Decoder output을 도출한다.
- 3번의 Decoder output은 다음 step의 Encoder의 Input이 되어 반복한다.
Attention 메커니즘은 RNN처럼 순차 데이터(문장, 음성 등)를 처리하는 seq2seq 모델의 성능을 크게 향상시켰다.
Self-Attention
Self-Attention은 문장 안의 단어들의 연관성을 알기 위해 스스로 Attention을 적용하는 것이다. timestep이 필요한 Attention과 달리, Self-Attention은 단어 하나 당 모든 단어에 대해 Attention Score를 구하므로 timestep이 필요가 없다.
RNN처럼 들어온 timestep 순서로 계산하거나, CNN의 Convolution처럼 input data의 local을 사용하는 것이 아닌 모든 input에 대해 한번에 계산하기 때문에 local dependency가 아닌 long range dependency modeling이 가능하다는 장점이 있다.
즉, RNN처럼 방향이 정해진(timestep) Attention은 자신보다 나중에 들어갈 input 데이터들은 활용하지 못하지만, Self-Attention 기법을 사용하면 모든 input 데이터에 대해 Attention 연산이 이루어지기 때문에 모든 input 데이터 정보를 활용할 수 있다.
Self-Attention은 input 데이터의 각 요소가 자기 자신을 포함한 다른 모든 요소와의 관계를 학습할 수 있게 한다. Self-Attention의 핵심 요소는 Query, Key, Value가 있다.
- Query(질문): 현재 처리하고 있는 문장 또는 단어의 표현이다. 질문을 던지는 주체로 생각할 수 있으며, 다른 단어들과의 관계를 알고 싶어하는 단어의 관점을 나타낸다.
- Key(키): 비교 대상이 되는 문장 또는 단어의 표현입니다. 각 Key는 정보의 저장소 역할을 하며, Query가 접근하려고 하는 대상이다. Query가 각 Key와 얼마나 관련이 있는지를 평가하여 해당 단어가 얼마나 주목해야 할 대상인지 결정한다.
- Value(값): Key에 대응하는 실제 값이다. Query와 Key의 관계가 얼마나 강한지에 따라, 각 Value는 Query에 의해 가중치가 부여된다. 이 과정을 통해 얻은 가중치가 높은 Value들이 결합되어, 최종적으로 Query에 대한 응답이 된다.
이러한 모든 요소가 서로를 조사하고, 그 결과로 각 요소는 다른 모든 요소와의 관계에 따라 새로운 표현을 얻게 된다. 이 과정은 input 데이터 내의 숨겨진 패턴과 관계를 효과적으로 파악할 수 있다.
이러한 Attention은 다음과 같이 구할 수 있다.
[
\text{Attention}(Q, K, V) = \text{softmax}\left (\frac{QK^T}{\sqrt{d_k}} \right)V
]
\[\text{Attention}(Q, K, V) = \text{softmax}\left (\frac{QK^T}{\sqrt{d_k}} \right)V\]위 수식 자세히 파고들기
- Query와 Key를 내적하여 연관성을 나타내는 Attention Score를 계산
- $\sqrt{d_k}$로 나누는 scaling을 통해 모델 학습을 수월하게 함
- softmax 함수로 정규화
- 위에서 계산된 score matrix와 Value matrix를 내적하여 Attention matrix 형성
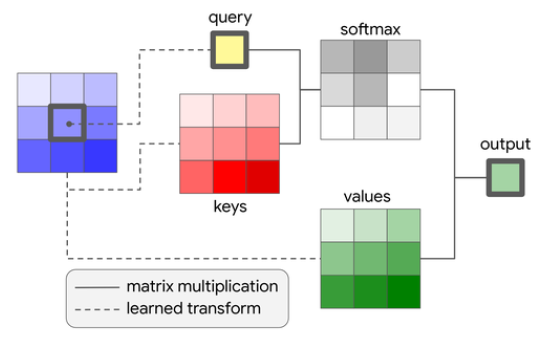
- 이미지에서 일부분을 나타내는 작은 패치(patch)들을 추출하여 다루기 쉬운 형태로 변환하기 위해 임베딩
- 이미지의 각 패치를 Query, Key, Value로 사용하여 Self-Attention을 계산
- 각 패치(Query)와 다른 모든 패치(Key)로 Attention map을 계산
- Attention map에 값(Value)를 가중 평균하여 이미지 내에서 각 패치가 서로 어떻게 관련되어 있는지를 모델링
이 Attention map을 시각화하면 아래과 같이 Query인 값과 Key 값들의 연관된 정도에 따라 다른 밝기 수준을 가지고 있어 어떤 픽셀과 관련이 있는지 알 수 있다.

SAGAN에서는 image generation task에 이러한 Self-Attention을 사용해 long range dependency 문제를 해결하고자 한다.
✏️Self-Attention GANs
대부분의 GAN은 주변 값들의 정보를 활용하는 Convolution 연산을 통해 구축되어있다. 이때문에, 이미지의 long-rande dependencies을 modeling할 때 비효율적이다.
이번 논문에서는 Self-Attention을 적용하여 $G$와 $D$가 넓게 펼쳐진 영역 간의 관계를 효율적으로 modeling할 수 있도록 하는 SAGAN을 제안한다.
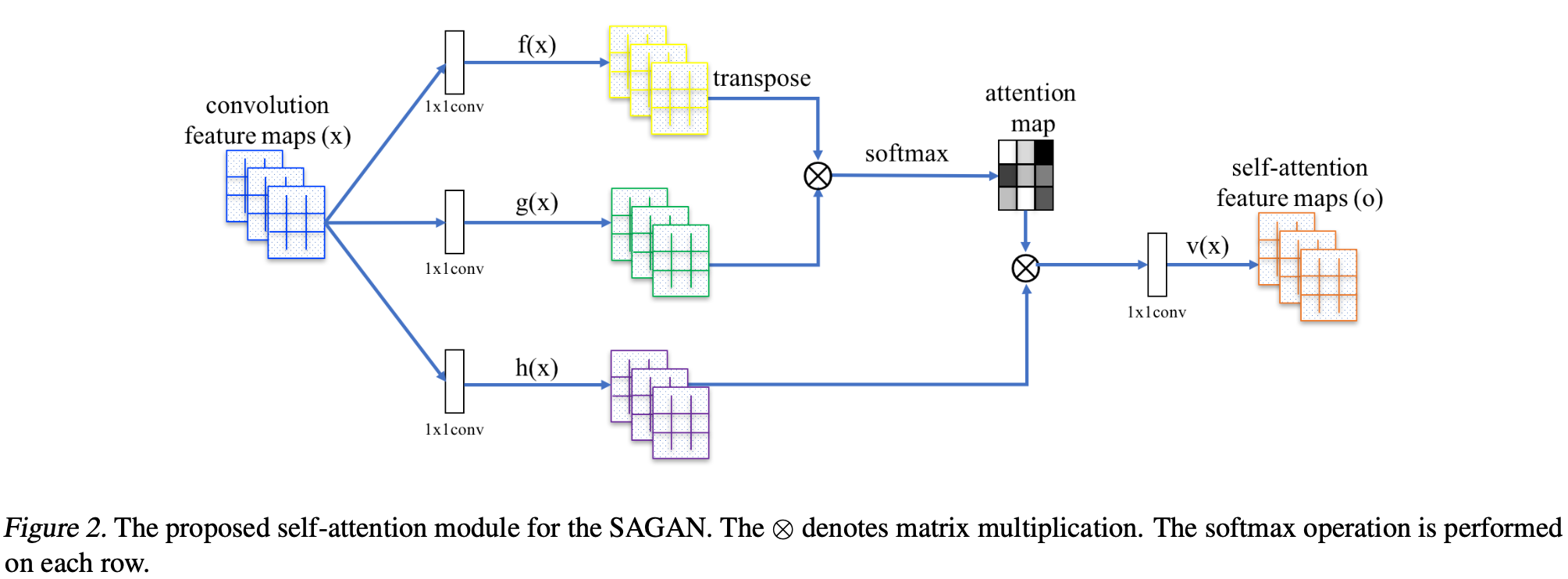
convolution layer를 통과한 feature map($x$)를 입력 $x \in \mathbb{R}^{C \times N}$의 image features는 Attention을 계산하기 위해 3개의 feature space인 Query $f(x)$, Key $g(x)$, Value $h(x)$로 1x1 convolution으로 계산하여 변환된다. $\rightarrow f(x) = \textit{W}_f x$, $g(x) = \textit{W}_g x$, $h(x) = \textit{W}_h x$
아래 수식은 Query와 Key의 곱에 softmax 연산을 통해 Attention Map을 구하는 식이다.
\[\beta_{j,i} = \frac{e^{s_{ij}}}{\sum_{i=1}^N e^{s_{ij}}}, \;\text{where}\;\; s_{ij} = f(x_i)^Tg(x_j) \tag{1}\]여기서 $\beta_{j,i}$는 $j^{\text{th}}$번째 영역을 처리할때 $i^{\text{th}}$영역이 얼마나 영향을 미치는지 결정하는 weight이다.
channel 수를 $C$, 이전 hidden layer에서 넘어온 feature의 feature location 수를 $N$이라 할 때, Attentino layer의 output은 $o = (o_1, o_2, \cdots, o_j, \cdots, o_N)$이다. ($o$ : self-attention feature map)
\[{o_j} = v\left(\sum_{i=1}^N \beta_{j,i}h(x_i) \right), \; h(x_i) = W_hx_i,\; v(x_i) = W_vx_i \tag{2}\]$W_g\in \mathbb{R}^{\overline{C} \times C}$, $W_f\in \mathbb{R}^{\overline{C} \times C}$, $W_h\in \mathbb{R}^{\overline{C} \times C}$, $W_v\in \mathbb{R}^{C \times \overline{C}}$ 모두 $1 \times 1$ convolution 연산을 거쳐 학습된 weight이다.
ImageNet으로 몇번의 epoch를 train한 후, channel 수 $\overline{C}$를 $\frac{C}{k}$($k = 1, 2, 4, 8$)로 감소시켜봐도 성능 저하는 보이지 않아 메모리 효율성 때문에 $k = 8$로 지정하였다고 저자들을 말한다.
게다가, Self-attention feature map에 scale parameter를 곱하고, input feature map을 더하여 최종 output을 만들었다.
\[y_i = \gamma o_i + {x_i} \tag{3}\]여기서 $\gamma$는 처음에 0으로 초기화된 parameter이다. 논문에서는 이러한 $\gamma$를 곱해 처음에는 local 정보를 활용하다가, 점점 갈수록 local이 아닌 정보에 가중치를 부여하게끔 할 수 있음을 나타낸다.
이 말은즉슨, 처음에는 쉬운 학습을 하고 나중에 복잡한 task를 학습하게 유도한 것이라고 저자는 말한다.
제안된 self-attention 모듈은 $G$와 $D$ 모두 적용했으며, hinge loss를 GAN에 적용하였다.
hinge loss는 classification에서 사용하는 loss function으로, 주로 SVM에서 최대 margin 분류에 사용된다.
\[l(y) = \text{max}(0, 1 -t* y ),\; \text{where} \; t = \pm1\]여기서 $t$는 정답 혹은 오답 class를 예측하는 중인지를 결정한다.
$|y| > 1$일 경우에서는 $y$가 margin 밖에 있는 상황이며 다음과 같은 경우가 생긴다.
- $t$와 $y$가 같은 부호이면 $l(y)=0$이 된다.
- 즉, 정확하게 분류한다는 뜻이다.
- $t$와 $y$가 다른 부호이면 오답이며 $l(y)$는 linear해진다. (잘못 분류했다는 뜻)
$|y| < 1$이고 $t$와 $y$가 같은 부호이더라도 올바른 예측을 하고 있지만, 아직 확실하지 않다는 것을 의미한다.
즉 분류가 잘 되는 margin 바깥 부분의 관측값이라면 loss가 0이 되도록 하고,분류가 잘 되지 않는 margin 내의 관측값이라면 loss가 커지게 유도하는 것이 hinge loss의 목적이다.

SAGAN에서 사용하는 $G$와 $D$의 loss 식은 다음과 같다.
\[L_D = -\mathbb{E}_{(x,y) \sim p_{\text{data}}}[\text{min}(0, -1 + D(x,y))] - \mathbb{E}_{z \sim p_z,y \sim p_{\text{data}}}[\text{min}(0, -1-D(G(z), y))]\] \[L_G = -\mathbb{E}_{z\sim p_z, y \sim p_{\text{data}}}D(G(z),y) \tag{4}\]$D$는 최적의 hyperplane을 찾기 위해 학습한다.
- $D(x, y)$는 실제 데이터에 대한 분류값이며, 이 값이 1(real에 대한 분류값)보다 작으면 $D(x, y)\geq1$이 되도록 유도한다.
- $D(G(z), y)$는 $G$가 생성한 이미지에 대한 분류값이며, 이 값이 $-1$보다 큰 경우 $D(G(z), y) \leq -1$ 가 되도록 유도한다.
$G$는 $D(G(z), y)$가 $D$의 hyperplane에 가까워지도록 학습하는 것이 목표이다.
✏️Techniques to Stabilize the Training of GANs
GAN 학습을 안정화(Stabilize)하기 위해 적용한 기법 2가지를 알아보자.
- $D$에 적용된 spectral normalization을 $G$에도 적용한다.
- $D$가 학습이 느리다는 문제를 해결하기 위해 two-timescale update rule을 적용한다.
1. Spectral normalization
<Spectral normalization for generative adversarial networks, 2018>에서 spectral normalization을 $D$에 적용하였을 때, GAN의 학습이 안정화되며 계산 비용 역시 상대적으로 적다는 것이다.
Spectral normalization은 $D$의 Lipschitz constant를 컨트롤하기위해서 사용된다. Lipschitz norm은 함수의 gradient를 제한하는 것인데, 이때 tuning해야하는 hyper parameter인 Lipschitz constant를 신경써서 조절할 필요가 없어진다.
자세한 내용은 추후 SNGAN을 리뷰하면서 설명하겠다…
저자들은 $G$도 spectral normalization의 이점을 활용할 수 있다고 말한다. parameter의 비대화를 방지하고 비정상적인 gradient를 피할 수 있다. 실험을 통해 $G$, $D$ 둘 다 computing cost를 획기적으로 줄이며 안정적인 train을 보여준다고 한다.
2. Imbalanced learning rate for $G$ and $D$ updates
일반적으로 GAN에서 $G$와 $D$의 train balance를 맞추기 위해 $G$ 1 업데이트 당 $D$ $k$ 업데이트 단계를 거친다.
하지만 <GANs trained by a two time-scale update rule converge to a local nash equilibrium>에서 제안한 Two Time-Scale Update Rule(TTUR)은 $D$와 $G$에 다른 learning rate를 적용하는 방법이다. 이 방법을 사용하여 효율적으로 $G$와 $D$의 balance를 맞출 수 있었으며, 같은 train 시간으로 더 나은 결과를 얻었다고 말한다.
✏️Experiments
논문에서는 train할 때 사용한 detail은 다음과 같다.
- 128*128 이미지 생성
- spectral normalization 적용
- $G$는 conditional batch normalization을, $D$에는 projection을 적용
- $\beta_1 = 0$, $\beta_2 = 0.9$인 Adam optimizer 사용
- TTUR : [$D$ - 0.0004, $G$ - 0.0001]
1. Evaluating the proposed stabilization techniques
제안된 stabilization(안정화) 기법에 대한 평가를 진행하는 section이다.
spectral normalization은 SN, learning rate의 balance를 맞추는 TTUR이라 하자.
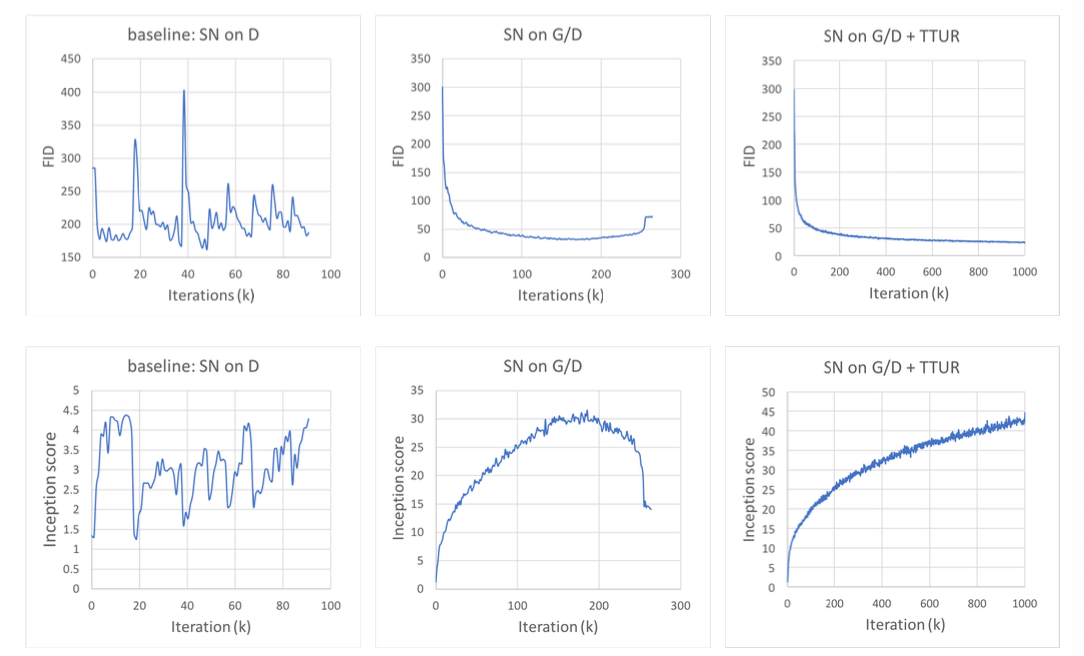
위 사진은 SN과 TTUR을 사용한 모델의 학습 그래프이다.
좌측 모델은 SN을 $D$에만 적용한 baseline 모델(SN on D)로, 학습이 매우 불안정함을 알 수 있다.
중간 모델은 SN을 $G$와 $D$ 모두 적용한 모델(SN on G/D)로, 학습이 안정되었지만 26만 iter에서 이미지 품질이 떨어지기 시작하였다.
아래 사진에서
SN on G/D의 160k의 FID 값은 33.39였지만SN on G/D의 260k의 FID값은 72.41로 오히려 결과 이미지의 품질이 하락
우측 모델은 SN과 TTUR를 적용시켜 중간모델에서 $G$와 $D$의 학습률을 조정한 모델이며 논문에서 제안한 모델(SN on G/D + TTUR)이다. 이 모델의 경우 학습이 안정되고 이미지 품질 역시 FID 또는 Inception score의 하락은 보이지 않았다.

2. Self-attention mechanism
여러 feature map에 Self-attention을 적용시키면서 성능의 변화를 살펴보자.

위 표를 보면 high-level feature map($feat_{32}$, $feat_{64}$)에 Self-Attention을 적용시킨 모델이 low-level feature map($feat_{8}$, $feat_{16}$)에 적용시킨 모델보다 성능이 좋은 것을 알 수 있다.
8*8 feature map과 같이 작은 크기에 적용시킨 Self-attention은 Convolution과 다를바 없지만, Self-attention을 적용시킨 feature map 크기가 커지면 활용할 수 있는 정보가 많아지며 long-range dependency modeling이 수월해진다.
또한 Self-attention block 대신 Residual block을 사용할 때 차이가 큰 것으로 보아 SAGAN 사용으로 인한 성능 향상이 단순히 모델 깊이와 용량의 증가로 인한 것이 아님을 보여준다.
위 이미지는 Self-attention이 long range dependency modeling 했을 때 Query 위치에 대한 Attention map이다.

위 이미지는 마지막에 학습된 $G$의 Attention map을 시각화한 것이다. Query 위치를 보면 네트워크가 공간적인 인접성뿐만 아니라 색상, 질감 등의 유사성에 따라 Attention을 할당하는 것을 학습함을 알 수 있다.
오른쪽 상단 강아지 이미지에서 파란색 Query point를 보면 관절 구조를 정확하게 파악하여 뚜렷한 다리를 그릴 수 있음을 볼 수 있다.
3. Comparison with the state-of-the-art(SOTA)
기존에 ImageNet에서 conditional 이미지 생성 SOTA를 달성한 cGANs with Projection Discriminator과 ACGAN과 비교를 진행하였다.

위 표를 보면 Inception Score, Intra FID, FID라는 3가지 metric에서 SOTA를 달성함을 알 수 있다.

위 사진은 ImageNet의 몇가지 class에 대한 SAGAN의 생성 결과이며, 괄호() 안에 있는 숫자는 각 class에 대한 SAGAN과 CGANS with Projection Discriminator의 intra FID이다.
금붕어, 강아지, 새 등과 같이 기하학&구조적인 패턴을 가진 class에서는 SAGAN이 우수한 성능을 보이지만, 질감과 같은 특성으로 구별되는 돌담, 산호 등은 SAGAN의 성능이 더 낮은 것을 알 수 있다.
이는, Self-Attention이 기하학&구조적인 패턴이 생기는 long range dependency을 modeling하는 점에서는 convolution 연산보다 좋은 성능을 보이지만 단순한 텍스쳐를 modeling할 때에는 local convolution과 유사한 역할을 함을 시사한다.
✏️Conclusion and Code
Self-Attention GAN은 다음과 같은 변경 사항을 통해 SOTA를 달성하였다.
- Self-Attention module을 통한 long range dependencies modeling이 수월
- $D$뿐만 아니라 $G$에도 적용된 spectral normalization을 통한 학습 안정화
- Two Time-Scale Update Rule(TTUR)를 활용하여 $D$와 $G$의 학습 불균형 해결