[Paper Review] SplatFlow
[논문 리뷰] SplatFlow: Multi-View Rectified Flow Model for 3D Gaussian Splatting Synthesis
SplatFlow: Multi-View Rectified Flow Model for 3D Gaussian Splatting Synthesis
Hyojun Go, Byeongjun Park
EverEx, KAIST
CVPR 2025.
[Arxiv] [Project Page] [Github]

Introduction
최근에는 3D Gaussian Splatting (3DGS)이 대안으로 떠오르고 있으며, 이를 기반으로 3D Generation 및 Editing에서 속도와 품질을 동시에 달성하고자 한다. 하지만 대부분 3DGS Generation 및 Editing 방법은 특정 task에 특화되어 있으며, 통합된 프레임워크는 부족하다. 3DGS 생성을 위해 2D Diffusion 모델을 사용하지만, 이 방식은 각 scene마다 최적화가 필요하여 시간이 오래 걸린다.
이 문제를 해결하기 위해 Diffusion을 Reconstruction 모델과 결합하거나, 3D Generative 모델 자체를 사용하는 방식으로 3DGS Gneration을 시도한다. 하지만 대부분 특정 환경에서의 합성 데이터셋을 사용하여, 현실 세계의 다양한 scene scale나 복잡한 카메라 경로 같은 문제에는 적합하지 않다. 3DGS 편집 분야에서도 2D Diffusion 모델을 사용하지만, 3D 변환에서 어려움이 존재한다.
본 논문에서는 직접적인 3DGS Generation 모델을 설계한다. inversion이 2D Diffusion에서 train-free editing이 가능한 것처럼, SplatFlow는 2D to 3D 파이프라인 없이 생성과 편집을 하나의 통합된 프레임워크로 제공할 수 있게 한다.
우리는 SplatFlow를 제안한다. 이 모델은 크게 두 가지 구성 요소로 이루어진다:
1. Multi-view Rectified Flow (RF) 모델
2. Gaussian Splatting Decoder (GSDecoder)
LDM처럼 RF모델을 latent space에서 작동시켜 텍스트 프롬프트에 따라 이미지, 깊이, 카메라 포즈를 동시에 생성하게 하여 SplatFlow는 현실 세계의 다양한 장면 규모와 카메라 경로를 효과적으로 다룰 수 있다. GSDecoder는 효율적인 feed-forward 방식을 사용하여 이 latent 출력을 3DGS representation으로 변환한다.
SplatFlow는 train-free inversion&inpainting을 활용하여, 3DGS 편집뿐만 아니라 object 교체, novel view synthesis, 카메라 포즈 추정 등 다양한 3D 작업도 수행할 수 있다.
Preliminary : Rectified Flows
Rectified Flow (RF) 모델은 다음과 같은 상미분방정식(ODE)을 기반으로 데이터 분포 $p_0$로부터 샘플을 생성하는 생성 모델을 정의한다:
\[\frac{\text{d}X_t}{\text{d}t} = v(X_t), \quad X_0 \sim q_0, \quad t \in [0, 1]\]여기서 $q_0$는 일반적으로 Gaussian 분포 $\mathcal{N}(0, I)$로 초기화되며, $v(X_t)$는 시간에 따라 변화하는 vector field이다. 이 벡터장은 Neural Net으로 학습되며, 다음과 같이 파라미터화한다:
\[v_t(X_t) = -u_\theta(X_t, 1 - t)\]Training
RF는 모델을 학습하기 위해, $p_0$와 $q_0$에서 추출된 샘플 쌍 $(y_0, y_1)$을 사용한다. 이 샘플 사이를 연결하는 직선 경로(linear path)를 정의한다:
\[Y_t = tY_1 + (1 - t)Y_0\]이 선형 경로에 따라 생성되는 분포 $p_t(y_t)$는 다음과 같이 표현된다:
\[p_t(y_t) = \int p_t(y_t \mid y_1) p_1(y_1) \, dy_1\]이 때, 조건부 벡터장은 다음과 같은 상미분방정식(ODE)을 따른다:
\[\frac{dY_t}{dt} = u_t(Y_t \mid Y_1) = y_1 - y_0\]여기서 벡터 필드 $u_t(Y_t|Y_1)$는 $y_0 \to y_1$ 로의 조건부 변화를 나타낸다.
marginal vector field $u_t(y_t)$는 다음과 같이 conditional vector field을 평균하여 얻는다:
\[u_t(y_t) = \int u_t(y_t \mid y_1) \frac{p_t(y_t \mid y_1)}{p_t(y_t)} p_1(y_1) \, dy_1\]Loss function
위의 벡터장을 근사하기 위해, RF는 Flow Matching (FM) loss를 정의한다:
\[\mathcal{L}{\text{FM}} := \mathbb{E}_{t, Y_t} \left[ \| u_t(Y_t) - u_\theta(Y_t, t) \|^2_2 \right]\]하지만, 이 FM loss는 계산 복잡도가 크기 때문에, Conditional Flow Matching (CFM) loss로 대체하여 학습한다:
\[\mathcal{L}_{\text{CFM}} := \mathbb{E}_{t, Y_t, Y_1 \sim p_1} \left[ \| u_t(Y_t \mid Y_1) - u_\theta(Y_t, t) \|^2_2 \right]\]최종적으로, 학습된 vector field은 다음과 같이 사용되어 데이터 분포 $p_0$를 따르는 샘플을 생성할 수 있다.
\[v_t(X_t) = -u_\theta(X_t, 1 - t)\]Method
Overview
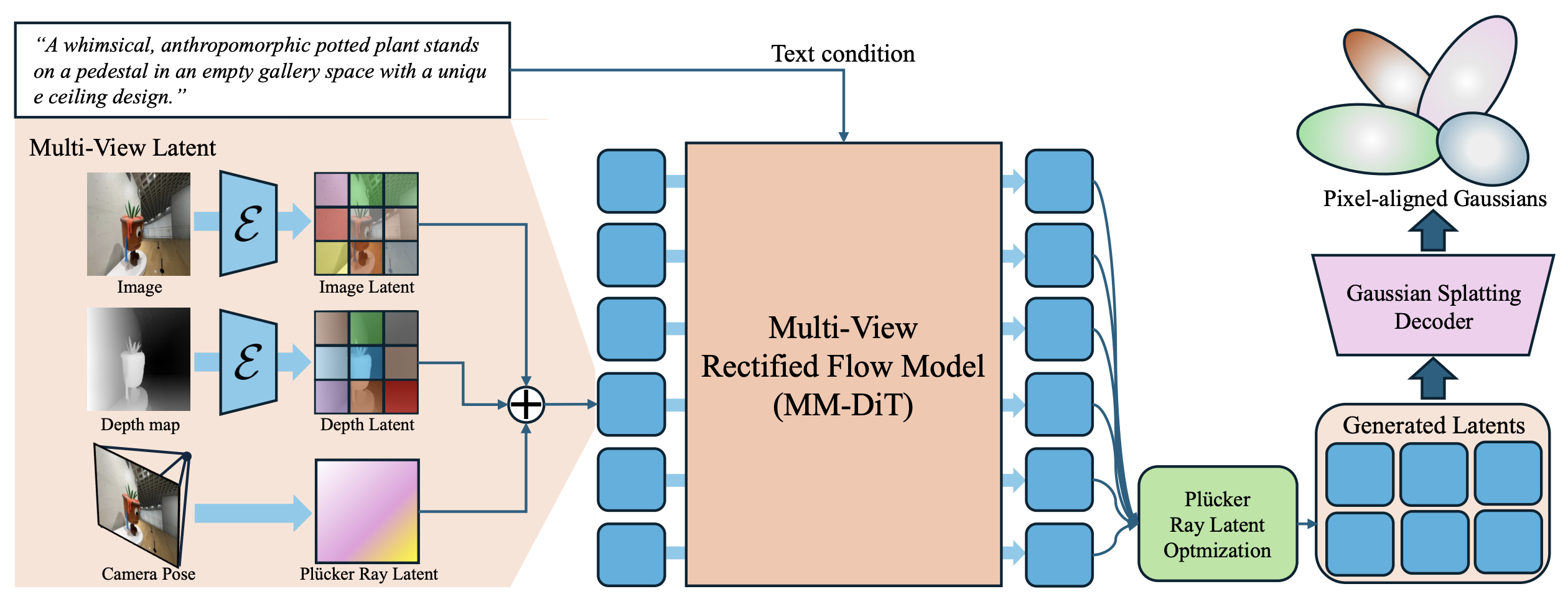
SplatFlow라는 3DGS 생성 모델을 제안하며, 이 모델은 생성을 목적으로 학습되었음에도 불구하고, 다양한 3D 편집 및 3D 관련 task을 학습 없이 수행할 수 있도록 설계되었다.
위 figure에서 보이듯, SplatFlow는 크게 두 가지 주요 구성 요소로 이루어져 있다:
1. Multi-view Rectified Flow (RF) 모델
2. Gaussian Splatting Decoder (GSDecoder)
먼저, Multi-view RF 모델은 텍스트 프롬프트를 condition으로 받아, Multi-view 카메라 포즈, depth map, 이미지들을 생성한다. 이후, GSDecoder가 이러한 latent representation을 3DGS 형태로 변환함으로써 현실 세계의 장면 구조를 구성한다.
모든 모델은 latent space에서 동작하며, frozen Stable Diffusion 3 Encoder를 사용하여 RF 모델이 SD3와 같은 latent space을 공유하도록 설계하였다. 이로 인해, SD3의 지식을 활용하여 SplatFlow의 생성 및 편집 능력을 향상시킬 수 있다.
마지막으로, 본 모델은 training-free을 기반으로 하여 다음과 같은 다양한 task을 수행할 수 있다:
- object replacement
- camera pose estimation
- novel view synthesis
Gaussian Splatting Decoder (GSDecoder)
소수의 시점(sparse views)으로부터 빠르게 3DGS를 재구성하는 feed-forward 3DGS를 활용하여, 우리는 GSDecoder $G_\phi$ ($\phi$ : parameter)를 설계한다. GSDecoder는 K개의 시점에 대한 latent represenatation과 그에 대응하는 카메라 포즈 $P = {P_i}_{i=1}^K$를 입력받아, pixel-aligned 3DGS를 복원한다.
각 카메라 포즈는 다음과 같은 구성으로 표현된다:
\[P_i = K_i [R_i \mid T_i]\]여기서 $K_i$는 카메라 내부 파라미터(intrinsic matrix), $R_i$는 rotation matrix, $T_i$는 이동 벡터(translation vector)이다.
이미지 $I_i$를 고정된 인코더 $\mathcal{E}$에 통과시켜 latent vector를 얻고, 이를 바탕으로 GSDecoder $G_\phi$가 직접적으로 3D Gaussian parameter들을 출력한다:
\[G_\phi\left(\left\{(\mathcal{E}(I_i), P_i)\right\}_{i=1}^K\right) = \left\{\left(\mu_j, \alpha_j, \Sigma_j, c_j\right)\right\}_{j=1}^{H \times W \times K}\]- $\mu_j$ : 위치 (mean)
- $\alpha_j$ : 불투명도 (opacity)
- $\Sigma_j$ : 공분산 행렬 (covariance matrix)
- $c_j$ : 색상 (color)
위 파라미터들은 pixel-aligned 방식으로 제공된다.
그러나 이 방식에서 이미지 latent는 Frozen Stable Diffusion Encoder를 통해 생성되기 때문에, 세밀한 공간 정보를 잃고 추상적 표현에 머물 가능성이 있다. 즉, 정확한 3D 구조 보존에 어려움이 발생할 수 있다.
이를 해결하기 위해, 두 가지 개선 사항을 적용한다:
Depth latent integration
<Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation>에 따르면, Encoder $\mathcal{E}$ 는 depth 정보도 효과적으로 인코딩할 수 있다. 이를 기반으로 각 depth map $D_i$에 대해 latent $\mathcal{E}(D_i)$를 추가 입력으로 사용하였다.
- DepthAnythingV2를 통해 depth map $D_i$ 추출
- $[-1, 1]$ 범위로 정규화
위 과정을 거친 후, RGB 이미지와 유사하게 3채널로 구성하여 사용하였다.
이는 GSDecoder의 수렴 속도와 성능을 향상시키는 데 도움이 된다.
Adversarial Loss 적용
adversarial loss는 생성 이미지의 품질을 향상시키는 데 효과적이지만 훈련 초기에 적용하면 불안정하다. 이에 따라 GSDecoder가 일정 수준의 수렴에 도달한 이후에만 Vision-aided GAN에 사용된 vision-aided loss를 적용하여, 학습 안정성은 유지하면서 품질을 향상시키는 전략을 사용하였다.
Training
GSDecoder는 Stable Diffusion 3 Decoder 파라미터로 초기화되며,cross-view attention 메커니즘을 포함하고, 3D Gaussian Splatting에 맞게 채널 dimension을 확장하여 구성된다.
GSDecoder는 입력으로 ${(I_i, D_i, P_i)}_{i=1}^K$ 를 받아, 최종적으로 3DGS 파라미터 ${(\mu_j, \alpha_j, \Sigma_j, c_j)}_{j=1}^{H \times W \times K}$를 predict한다.
loss는 다음과 같다.
\[L_\text{decoder} = w_1 L_\text{mse} + w_2 L_\text{LPIPS} + w_3 L_\text{vision-aided}\]$L_\text{vision-aided}$는 일정 iter 이후 적용되며, $w_1=1$, $w_2=0.05$를 사용하였다고 한다. $w_3$의 경우, 각 iter에서 다른 loss gradient와 GSDecoder의 마지막 layer에서 Vision-aided GAN loss의 gradient의 비율에 따라 l2-norm을 기준으로 결정되며 0.1을 곱하여 을 설정한다.
Multi-View Rectified Flow Model
앞에서 GSDecoder가 준비되었으므로, 3D Gaussian Splatting 생성을 위해 필요한 조건은 Multi-view 이미지 latent $\mathcal{E}(I_i)$, depth latent $\mathcal{E}(D_i)$, 카메라 포즈 $P_i$를 일관성 있게 생성하는 것이다.
이를 위해 Multi-view Rectified Flow (RF) 모델을 설계한다. 이 모델은 텍스트 condition $C$에 따라 joint distribution로부터 샘플을 생성한다:
\[p\left(\{I_i\}_{i=1}^K, \{D_i\}_{i=1}^K, \{P_i\}_{i=1}^K \mid C\right)\]이 방식은 Multi-view 이미지, depth, 카메라 포즈를 동시에 생성하며, 다음과 같은 이유로 joint distribution 모델링이 필요하다:
- 편집 및 inpainting과 같은 다양한 task을 하나의 프레임워크 내에서 수행
- Real world scene에서 각기 다른 구조와 카메라 경로를 유연하게 반영
RF 모델은 각 시점 i에 대해, 이미지 latent $\mathcal{E}(I_i)$, depth latent $\mathcal{E}(D_i)$, 그리고 Plücker 좌표계를 따르는 카메라 ray $r_i$를 concat하여 입력으로 사용한다.
Plücker(플뤼커) 좌표계란?
두 점 $p_1$, $p_2$를 이용해 직선을 표현하는 일반적인 방법과 달리, 방향 벡터(direction vector)와 모멘트 벡터(moment vector) 2가지로 직선을 표현하는 방법이다.
모멘트 벡터 $m$은 직선과 원점을 포함하는 평면의 방향벡터를 의미하며, 원점과 $p_1$, $p_2$가 이루는 삼각형 넓이의 2배가 $m$의 크기가 된다. 또한, $m$과 $d$는 서로 직교하는 성질을 가지고 있다. ($m^\top \cdot d = 0$)
3D에서 Plücker 좌표 $\langle d, m \rangle$는 $\langle d_x:d_y:d_z: m_x: m_y: m_z \rangle$의 6가지 요소로 표현된다.
왜 Plücker 좌표 기반 ray 표현이 멀티뷰 일관성을 강화하는 데 중요할까?
Multi-View 일관성이란, 여러 시점에서 같은 장면을 볼 때 그 구조가 서로 맞아떨어지는 것을 의미한다.
하나의 물체를 왼쪽, 오른쪽, 위쪽에서 찍었을 때, 각 이미지에서의 모양, 위치, 깊이 등이 서로 충돌 없이 일치해야 하며, 이 일관성이 깨지면 현실감이 무너진다.
기존 latent 기반 표현의 한계
이미지 latent $\mathcal{E}(I_i)$, depth latent $\mathcal{E}(D_i)$는 각각의 시점에 대해 독립적으로 존재하기 때문에 모델이 각 시점이 어떻게 연결되어 있는지 공간적으로 잘 모른다.
그 결과, 서로 다른 시점 간 위치·방향 불일치, 깊이 왜곡 같은 문제가 생긴다.
이때, Plücker ray $r_i = \langle d_i, m_i \rangle$을 latent와 함께 입력에 포함시키면, 모델은 다음을 알 수 있다:
• “이 latent는 어디를 향하는 광선의 정보인지”
• “이 픽셀의 ray는 어디서 시작되고, 어디를 관통하는지”
• “다른 시점에서 비슷한 방향을 향하는 ray는 같은 공간을 바라보고 있는 것”
즉, 서로 다른 시점의 latent가 공간적으로 어떤 관계인지 추론할 수 있게 된다.
- 시점 간의 관계를 geometry-aware하게 학습하게 되고,
- 이미지 latent 자체에 포함되지 못한 공간 정보를 보완적으로 받아들여
- Multi-view 간 더 정밀하고 일관된 이미지/깊이/포즈 생성이 가능하게 된다.
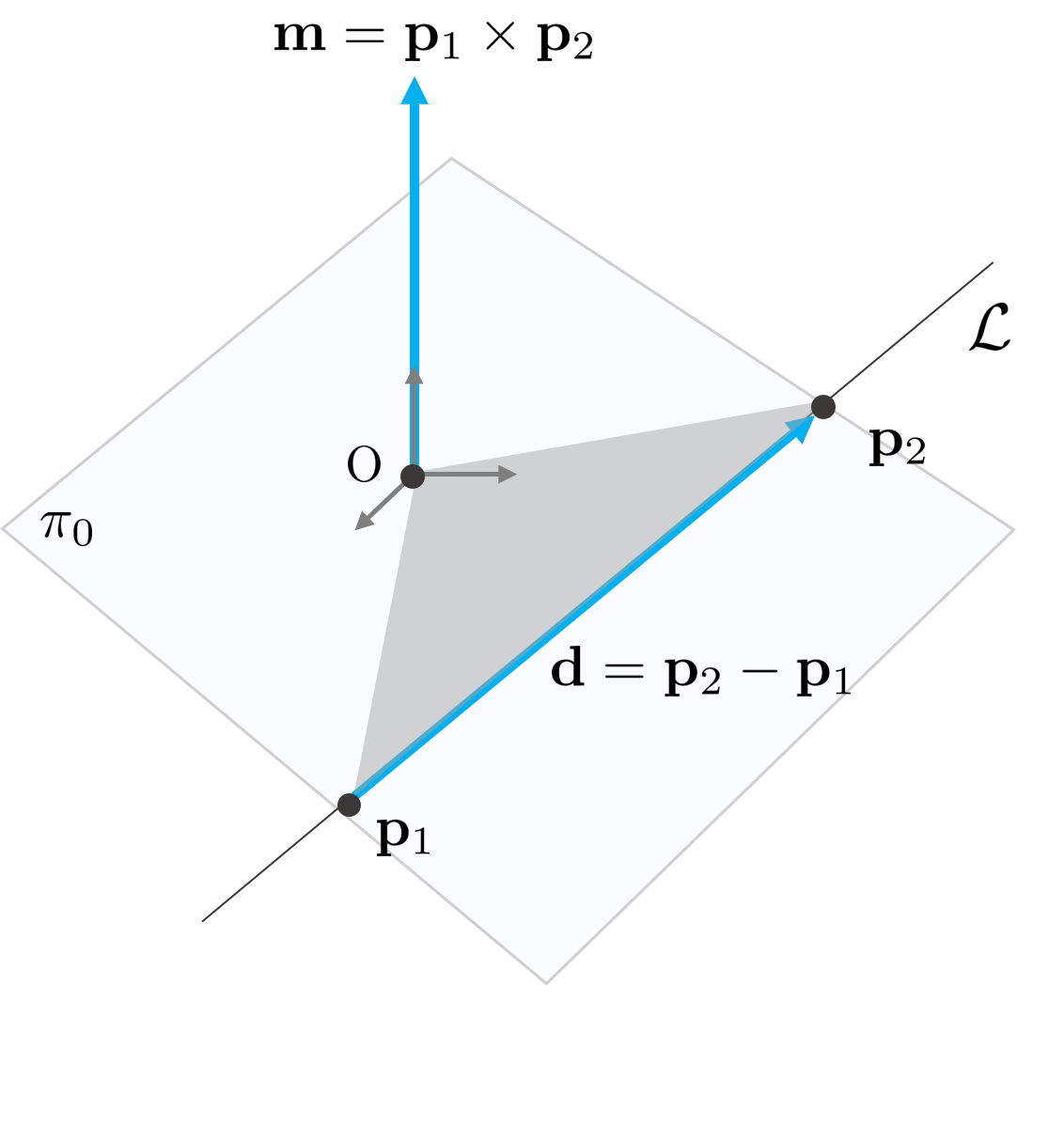
Plücker좌표계 상의 $r_i$는 $⟨d_i,m_i⟩$로 표현되며 각 요소는 다음을 의미한다.
- direction vector
여기서 $w_i$는 픽셀 좌표, $K_i$는 내부 파라미터, $R_i$는 rotation matrix이다.
- moment vector
결과적으로 광선 $r_i = \langle d_i, m_i \rangle$는 $6 \times h \times w$ tensor로 표현되며, 이미지 및 depth latent ($n \times h \times w$)와 결합되어, 하나의 표현 $X_i = \langle \mathcal{E}(I_i), \mathcal{E}(D_i), r_i \rangle \in \mathbb{R}^{(2n+6) \times h \times w}$이 된다.
이러한 구성으로부터 전체 입력은 다음과 같은 형태가 된다:
\[Y_0 = (X_1, X_2, \dots, X_K) \in \mathbb{R}^{K \times (2n + 6) \times h \times w}\]RF 모델 $u_\theta$는 이 데이터를 입력으로 받아, 앞서 설명한 Conditional Flow Matching loss로 학습된다.
RF모델 역시 Stable Diffusion 3모델을 기반으로 입력 및 출력 layer의 채널 수를 확장하고, cross-view attention 메커니즘을 포함하여 multi-view 일관성을 강화한다.
추가된 채널의 경우 pretrain된 가중치를 복사해서 사용한다.
Sample process
ray $r_i$로부터 다시 카메라 포즈 $P_i$를 복원하기 위해, RayDiffusion의 방식을 사용한다. 이 과정을 통해 카메라 포즈를 추정한 후, 다양한 view가 동일한 intrinsic matrix를 공유하도록 보정한다.
하지만 ODE를 그대로 푸는 것만으로는 포즈 정확도가 떨어질 수 있으며 그 원인을 카메라 포즈가 존재해야 할 manifold를 벗어나기 때문이라고 추정한다.
이를 해결하기 위해, 다음과 같은 전략을 사용한다:
- 매 sampling process $t = t_k$에서, t = 0에서의 predict 결과를 생성
- 해당 결과로부터 카메라 포즈를 복원
- 다시 카메라 ray을 구성하여 $t = t_k$까지 Plücker ray를 유효한 manifold로 projection하여 샘플링을 유지한다.
또한, multi-view 이미지 생성을 더 향상시키기 위해, Stable Diffusion 3의 vector field를 샘플링 중 일부 view에서 RF 모델과 결합하여 사용한다. 이 방식은 SD3의 강력한 generalization 능력을 활용하여 이미지 품질을 높이는 데 도움을 준다.
Inference Given Partial Data
SplatFlow가 training-free 3D 편집과 다양한 응용 task을 수행하기 위해 기존의 inversion 및inpainting 기법을 Rectified Flow에 맞춰 수정하여 적용한다.
- SDEdit 기반 inversion은 Rectified Flow 기반 inversion으로 수정
- RePaint 기반 inpainting은 Rectified Flow sampling 과정에 적합하도록 조정
3D GS editing
task 목표는 기존 3D scene의 일부를 텍스트 prompt에 따라 수정하는것이다.
GSDecoder는 multi-view latent를 직접 수정함으로써 3DGS를 디코딩할 수 있도록 설계되어 있다. 따라서 편집 작업은 multi-view latent만 수정하면 되므로 매우 효율적이다.
또한, RF 모델이 multi-view 이미지 latent의 joint distribution을 학습하기 때문에, cross-view attention과 같은 추가 모듈 없이도 편집이 가능하다. 이는 inversion + sampling이라는 간단한 파이프라인으로 편집을 수행할 수 있게 한다.
과정은 다음과 같다.
- 편집할 multi-view latent와 텍스트 프롬프트를 설정
- SDEdit을 Rectified Flow 구조에 맞게 수정하여 inversion 수행
- 수정된 latent를 기반으로 ODE $\frac{\text{d}X_t}{\text{d}t} = v(X_t)$를 풀어 편집된 latent를 생성
- GSDecoder를 통해 최종 편집된 3D Gaussian Splatting 결과 get
Inpainting application
task 목표는 일부 시점(view)의 정보만 주어졌을 때, 나머지 이미지/depth/카메라 포즈를 복원하는 것이다.
1) 카메라 포즈 추정: 이미지와 깊이 정보를 바탕으로 포즈만 추정.
2) Novel View Synthesis: 일부 시점만 가지고 나머지 시점의 장면을 예측.
이는 joint distribution modeling을 했기 때문에 알 수 없는 부분을 생성할 수 있다.
RePaint 기법을 Rectified Flow에 맞게 통합하여 구현한다.
과정 상세 설명(부록)
입력값
• $Y_{t_N}$ : 초기 latent 값 ($\mathcal{N}(0, I)$에서 샘플링)
• $m$ : 어떤 latent가 알려졌는지를 나타내는 mask (known vs unknown)
• $Y_{t_0}^{known}$ : 알려진 latent의 ground truth
• $u_θ$ : SplatFlow의 vector field (속도 함수)
Sampling
샘플링은 timestep $t_N \rightarrow t_0$ 방향으로 진행된다.
중간 ray inversion 적용 ($i ≥ t_{stop}$)
- 목적지 $Y_{t_0}$를 예측, Plücker ray $\langle d, m \rangle$ 추출
- $ \tilde{Y}_{t_0} \leftarrow Y_t - t_i u_\theta(Y_t, t_i)$
- $\langle d^{(1:K)}, m^{(1:K)} \rangle \leftarrow \tilde{Y}_{t_0}[2n:]$
- ray로부터 카메라 포즈 $(K, R, T)$를 역추정
- $ \langle K^j, R^j, T^j \rangle \leftarrow \text{ray optimize} \langle d^j, m^j \rangle , \;\;\;\; j \in [1, \dots, K] $
다시 새로운 ray를 구성, manifold를 보존
$\langle {K}, {R}^{(1:K)}, {T}^{(1:K)} \rangle \gets \text{shared_K}(\langle {K}, {R},{T} \rangle^{(1:K)})$
$\langle {d}^{(1:K)}, {m}^{(1:K)} \rangle \gets \text{plücker}(\langle {K}, {R}^{(1:K)}, {T}^{(1:K)} \rangle)$
${r}_{t_0} \gets \langle {d}^{(1:K)}, {m}^{(1:K)} \rangle$
- 목적지 $Y_{t_0}$를 예측, Plücker ray $\langle d, m \rangle$ 추출
Unknown latent 예측 (inpainting)
vector field $u_\theta$를 따라 다음 timestep로 업데이트한다
unknown ray latent는 아래 형태로 업데이트된다. ( $z \sim \mathcal{N}(0, I)$는 샘플링된 noise )
\[Y_{t_{i-1}}^{\text{unknown}} = (1 - t_{i-1}) \cdot r_{t_0} + t_{i-1} \cdot z\]
Known latent 유지
알려진 latent는 $Y_{t_{i-1}}^{\text{known}} = (1 - t_{i-1}) Y_{t_0}^{\text{known}} + t_{i-1} \epsilon $ 형태로 noise와 함께 interpolation된다.
최종 결합
전체 latent는 known/unknown을 mask로 구분하여 결합한다:
Expeimental Results
SplatFlow의 성능을 다음 세 가지 측면에서 평가한다:
- Text-to-3DGS Generation
- 3DGS Editing
- Inpainting Application (카메라 포즈 추정, novel view synthesis)
1. Text-to-3DGS Generation
metric:
- FID $\downarrow$: 생성 이미지의 현실성
- CLIP Score $\uparrow$: 이미지와 텍스트의 의미적 일치도
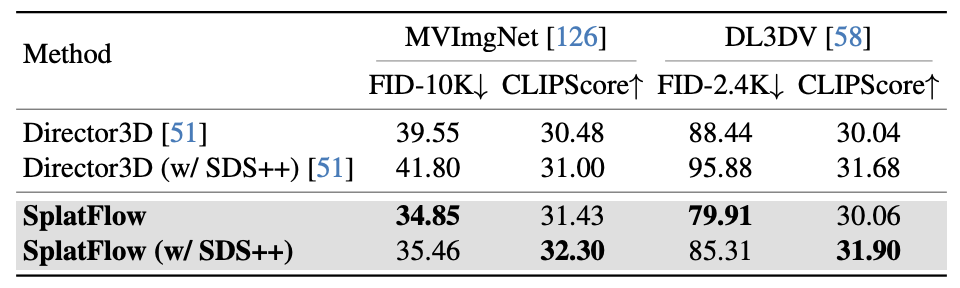
SplatFlow는 적은 학습 데이터에도 불구하고 더 낮은 FID를 기록하며, 이미지 품질 면에서 우수하다.
SDS++ 적용 시 CLIP Score가 추가 향상되며, 텍스트 정렬성도 높아진다.

2. 3DGS Editing
100개 scene을 사용하여 GPT-4로부터 편집 대상 객체의 caption을 받아 생성하고, 동일한 객체 mask를 이용하여 편집 전·후를 비교한다.
metric:
- CLIPScore $\uparrow$: 편집 후 이미지와 편집 텍스트의 의미적 일치도
- CLIP D-sim $\uparrow$: 원본 대비 편집 방향의 의미 변화 정도
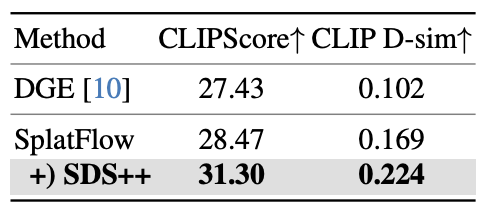
SplatFlow는 객체 교체의 정확성과 정합성 모두에서 우수한 성능을 보이며 SDS++ 적용 시 편집 정렬성과 의미적 변화 정도가 모두 향상됨을 볼 수 있다.

3. Inpainting Application
Camera pose estimation
metric:
- Rotation@$θ$: 회전 정확도 (5°, 10°, 15°)
- Center@$δ$: 중심 위치 정확도 (0.05, 0.1, 0.2)
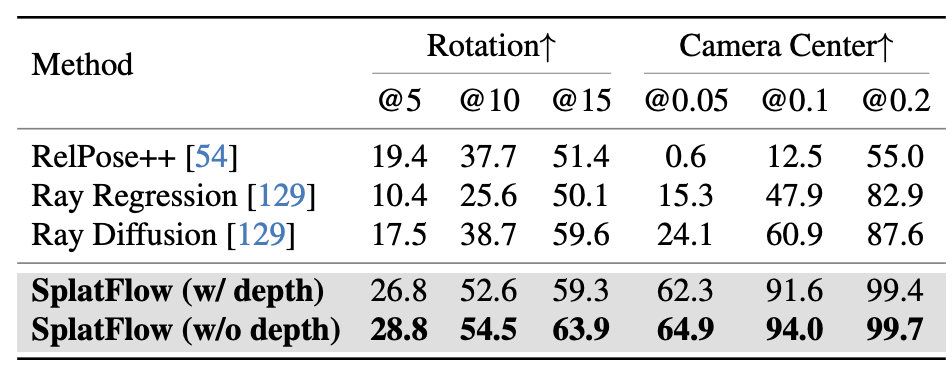
depth 정보를 제거한 버전이 오히려 더 높은 정확도를 보이는데, 저자들은 이를 깊이와 포즈를 동시에 추론하면서 더 풍부한 정보 간 상호작용이 발생했기 때문으로 추정한다.

Novel view-synthesis
Type:
- Interpolation: 입력 시점을 균등 샘플링
- Extrapolation: 중심부 입력만 사용, 주변 생성
metric:
- RGB : PSNR↑, SSIM↑, LPIPS↓
- Depth : AbsRel↓, $δ$1↑
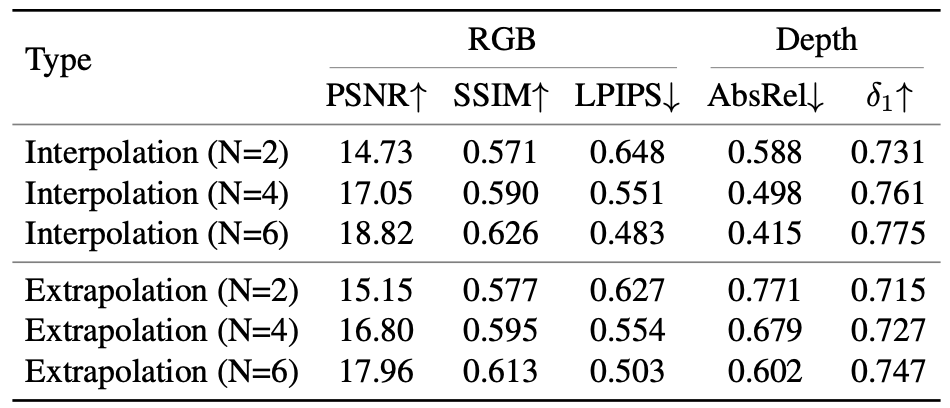
Interpolation이 Extrapolation보다 전반적으로 더 나은 성능을 보이며, 입력 뷰 수가 증가할수록 성능이 개선된다. 이는 SplatFlow가 시점 간 3D reasoning을 잘 수행함을 보여준다.

빨간색 테두리를 가진 사진을 기준으로 novel view synthesis를 수행한 결과이다.