[Paper Review] TADA : Timestep-Awara Data Augmentation for Diffusion models
[논문 리뷰] TADA : Timestep-Awara Data Augmentation for Diffusion models
데이터 증강(Data Augmentation)은 주어진 원본 데이터를 확장하여 데이터셋의 다양성을 증가시키는 기법이다. 이 방법은 특히 학습 데이터가 부족한 경우, 모델의 일반화 능력을 향상시키기 위해 사용한다.
이번 논문에서는 Diffusion model의 distribution 변화가 특정 timestep에서 발생한다는 것을 발견하고 timestep에 따라 유연하게 강도를 조정하는 Data augmentation 전략을 제안한다.
이러한 전략이 다양한 diffusion model에 도움되기를 바란다고 저자들은 말한다.
Introduction
Diffusion 모델의 reverse process에서 데이터 증강이 어떤 영향을 미치는지 살펴보았을 때, 성능 저하에 영향을 미치는 timestep을 파악하고, 특정 timestep이 sampling 과정의 변형에 기여하여 의도하지 않은 sample 생성이 이루어진다는 것을 파악하였다.
위에서 파악한 것을 바탕으로 저자들은 timestep에 따라 증강 강도를 유연하게 조정하는 Timestep-Aware Data Augmentation (TADA) 전략을 제안한다.
위 전략은 $T(x_t, w_t)$로 표시되는데, timestep $t$(noise level이 되기도 함)에 따라 증강 강도 $w_t$를 조절한다. 즉, input 데이터에 큰 noise가 포함된 경우 증강 강도가 강한 train sample($w_t$)로 model을 train한다. vulnerable한 timestep 동안에는 0에 가까운 $w_t$를 적용하다가 다시 약한 noise가 포함된 data가 input이 들어오면 다시 강도를 높인다.
Method
Preliminaries
TADA를 살펴보기 전 필요한 여러 개념들을 살펴보자
Diffusion models
$n$개의 데이터 point ${x_0^1, \cdots, x_0^n}$가 분포 $q(x_0)$에서 sampling되었다고 가정하자. Diffusion model은 분포 $q(x_0)$에 가장 근접한 모델 $p_θ(x_0)$를 만드는 것이 목표이다.
Diffusion model을 training하는 것에는 2가지 process가 있다.
- foward process : Gaussian noise $z \sim \mathcal{N}(0,\textit{I})$를 timestep $t$에 따라 추가하여 noise data $x_t$를 만드는 과정
- reverse process : foward process에서 추가된 noise를 제거(denoising)하여 원래의 데이터를 복구하는 과정
Foward process에서는 $x_0$를 이용해 $x_t = \alpha_t x_0 + \sigma^2 z$를 계산한다. 모델 $\widehat{\epsilon}_\theta (x_t, t)$는 weighted MSE를 최소화하여 timestep $t$에서 추가된 noise $z$를 예측하도록 train된다.
Reverse process에서는 $p_\theta(x_{t-1}|x_t)$를 통해 $x_t$로 $x_{t-1}$을 계산한다. 이 과정은 $x_T \sim \mathcal{N}(0, \textit{I})$, 즉 완전한 Gaussian noise인 상태에서 시작한다. $\widehat{x}_\theta (x_t, t) = \frac{x_t - \sigma_t^2 \widehat{\epsilon}\theta (x_t, t)}{\alpha_t}$일 때, reverse process $x{t-1}$는 다음과 같다.
\[\widehat{x}_{t-1} = \alpha_{t-1} \widehat{x}_\theta(x_t, t) + \sigma_{t-1}^2z \tag{1}\]$\alpha_t$와 $\sigma_t^2$, Objective, sampline method 등에는 다양한 방법이 있지만, 이 논문에서는 DDPM의 향상된 버전인 Improved DDPM에서 제안한 방법을 채택하였다.
Signal-to-nosie ratio(SNR)
Variational Diffusion Models에서는 signal-to-noise ratio(SNR)이라는 개념을 도입했으며, 이는 각 timestep $t$에서 noise level을 측정하는 개념이다. SNR은 $t$에 따라 점점 감소하는 함수이다. ($\text{SNR}(t) = \frac{\alpha_t^2}{\sigma_t^2}$)
Data augmentation
이 논문에서는 데이터 증강을 $T(x_t, w)$로 표시하며, $w \in [0,1]$은 증강의 강도를 제어하는 정규화된 hyper parameter이다.
Analyzing the effect of data augmentation on learned reverse process
데이터 증강이 Diffusion model에 미치는 영향을 파악하고 취약한 $t$를 파악하기 위해 증강을 통해 학습된 model과 일반적인 model의 reverse process를 비교한다.
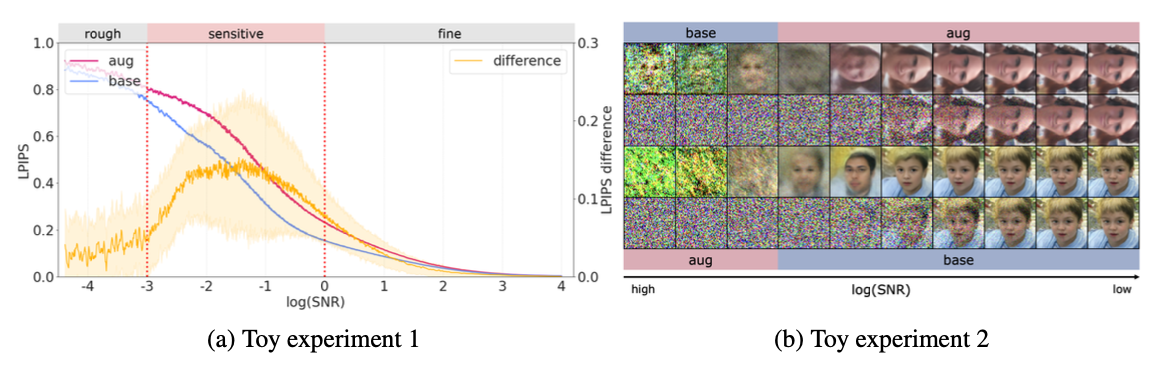
위 이미지에서 (a)는 horizontal-flip 으로만 train된 baseline 모델 ($\widehat{ε}_{\text{base}}$)과 증강 데이터로 train된 모델인 ($\widehat{ε}_{\text{aug}}$)의 두 Diffusion model의 reverse process를 비교한 실험의 결과이다. (a)그래프를 보면 rough(초기)와 fine(마지막) 시점에서는 두 모델의 차이(노란선)가 거의 없으며, sensitive한 timestep에서는 차이가 벌어짐을 알 수 있다.
(b)는 (a)의 sensitive timestep에서 $\widehat{ε}_{\text{aug}}$와 $\widehat{ε}_{\text{base}}$ 사이의 reverse process를 $\widehat{ε}_{\text{base}} \rightarrow \widehat{ε}_{\text{aug}}$ 와 $\widehat{ε}_{\text{aug}} \rightarrow \widehat{ε}_{\text{base}}$로 바꿔서 두 가지 sampling process를 생성한 결과이다.
- 처음 두 행은 sample이 처음에는 데이터 분포를 따르지만 결국 증강된 데이터 분포에 포함되는 $\widehat{ε}_{\text{base}} \rightarrow \widehat{ε}_{\text{aug}}$ 의 경우를 보여준다. 즉, sample이 $\widehat{ε}_{\text{base}}$에 의한 데이터 분포를 따르더라도 $\widehat{ε}_{\text{aug}}$에 의해 변경되어 증강된 것과 같은 결과물로 다시 나타난다.
- 마지막 두 행은 처음에 $\widehat{ε}_{\text{aug}}$의 궤적을 따르던 샘플이 sensitive timestep 동안 $\widehat{ε}_{\text{base}}$에 의해 조정되어 궁극적으로 데이터 분포와 일치하게 된 경우를 보여준다.
Diffusion model의 sensitive timestep에서 sampling trajectory을 변경하여 최종 sample이 원래 데이터 분포를 따르는지 아니면 증강된 분포를 따르는지를 결정할 수 있음을 알 수 있다.
Timestep-Aware Data Augmentation for Diffusion models
위 실험을 바탕으로 논문에서는 rough와 fine timestep에서는 강력한 증강(큰 $w$)을 적용하고, sensitive timestep에서는 강도를 낮추는 전략을 제안한다.
- sensitive timestep($t \in [t_{rough}, t_{fine}]$): 약한 강도의 증강이 train 데이터에 적용되어 생성된 sample $p(x)$에 가깝게 유지
- rough($t \in (t_{rough},T]$) 및 fine($t \in [0,t_{fine})$) timestep: 강력한 증강을 통해 과적합을 방지하고 확산 모델의 일반화 기능을 개선
증강 강도 $w_t$는 다음과 같이 구할 수 있다.
\[w_t = k(r_t - r_{rough})(r_t - r_{fine}) + \delta \tag{2}\]여기서 $r_t = \log (\textbf{SNR}(t))$이며, $\delta$는 sensitive timestep에서 최대 증강 강도를 나타낸다. $w_t$가 너무 낮으면 안되기 때문에 $\delta=0.1$로 설정하였다.
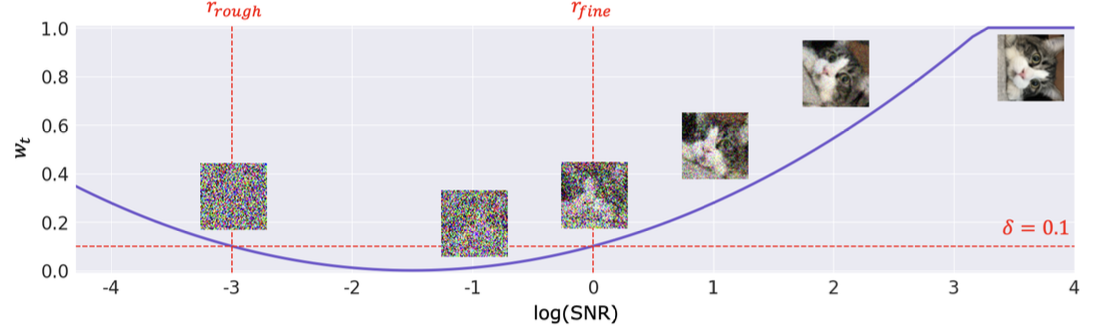
위 그림은 Eq. 2에 대한 그래프이다.
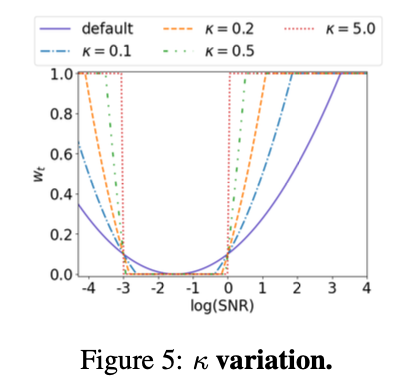
$k$는 clipping이 발생하기 전에 $w_t$가 0이 되도록 한다. 이는 자동으로 계산되는데, 위 그래프는 $k$를 조절하였을 때 $ r_{rough}$와 $ r_{fine}$에서 증강 강도가 어떻게 변화하는지 나타내는 그래프이다.
Diffusion 모델의 noise level이 해상도에 따라 달라지므로 SNR을 조정할 필요를 느끼고 다른 논문에서 제안한 식을 적용하였다. 이미지의 해상도를 $d$, timestep을 $t$라 할 때
\[\text{SNR}_{calibrated}(t) = \frac{\text{SNR}(t)}{(d/64)^2} \tag{3}\]이 식을 Eq. 2의 $r_t$에 적용시키면 해상도에 따른 조정이 가능해진다고 한다.
Experiment
TADA를 이전 연구에서 사용된 두 가지 증강 방법과 비교하는 실험을 한다.
- 50% 수평 뒤집기(h-flip): 확산 모델에서 일반적으로 사용
- 증강 정규화 방법(AR):<Elucidating the Design Space of Diffusion-Based Generative Models>(2023)에서 사용한 기법
Benefit of TADA
TADA는 sensitive timestep 동안 증강 강도를 조정하기 때문에 distribution-shifted sample을 생성하지 않는다는 것을 보여주며, overfitting 문제를 완화하여 작은 데이터 세트에서 Diffusion 모델의 성능을 향상시킨다는 것을 보여준다.
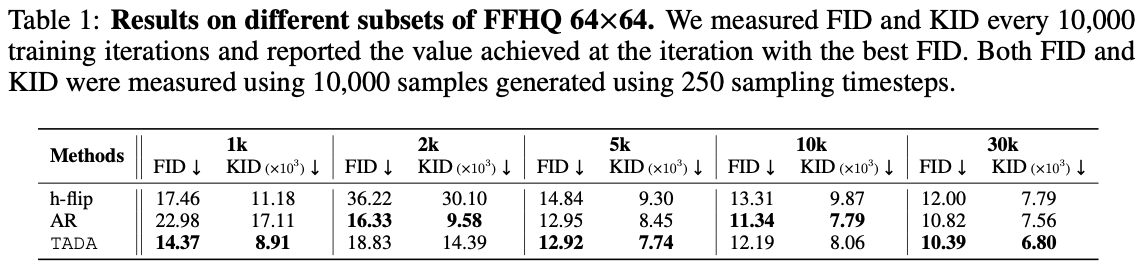
위 표 1를 보면, iter가 100,000회인 FID 및 KID 결과를 나타낸다. h-filp 기법보다 성능이 좋은 것을 알 수 있으며, TADA라는 비교적 간단한 기법으로 AR과 비슷한 결과를 낸다는 것을 알 수 있다.

위 사진은 TADA가 분포 내에서 sample을 생성하는지 시각화한 것으로, 모든 timestep에서 증강을 적용한 Naive augmentation에 비해 TADA가 훨씬 선명한 얼굴을 생성한다는 것을 알 수 있다.
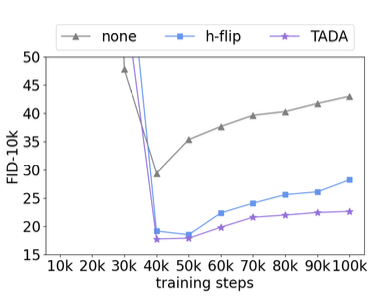
위 그래프는 overfitting에 미치는 영향을 보여주는 그래프로, FID값을 나타내는 그래프이다.
TADA(보라색)가 h-flip(파랑색)보다 overfitting을 완화하는 데 더 효과적임 알 수 있다.
Generalization
TADA가 Diffusion 모델 학습에서 다양한 설계에 적용할 수 있음을 알아보기 위해 높은 해상도, Transfer learning, 다양한 Noise scheduling, 다양한 모델 크기로 실험을 진행하였다.
High resolution
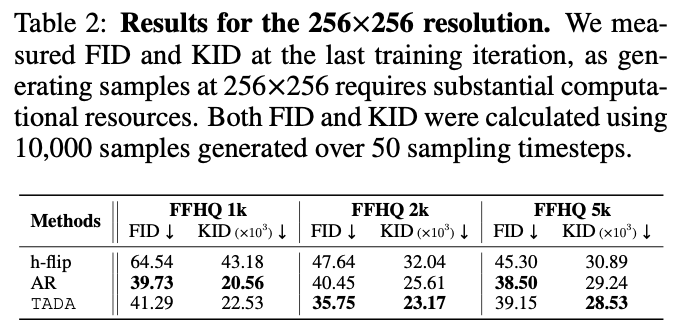
표 2역시 표 1과 동일

높은 해상도인 256*256 데이터에 TADA를 적용한 결과이다.
Transfer Learning
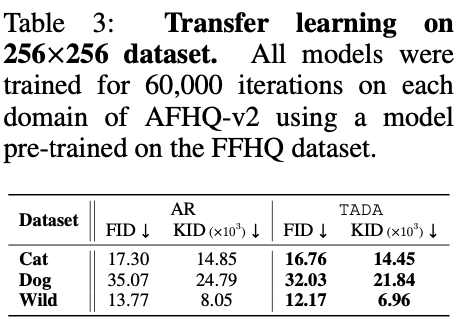
위 표 3은 AHFQ-v2의 세 가지 class에서 TADA가 AR을 능가하고 있음을 보여준다.
Noise scheduling, Sampling step, Model size
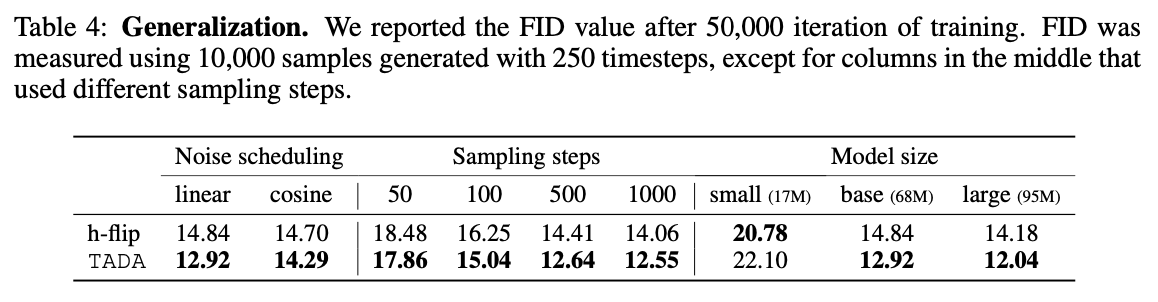
위 표 4는 3가지 관점에서 TADA와 h-flip을 평가한 결과이다.
- TADA는 linear과 cosine noise schedule 모두에서 h-flip보다 우수한 성능을 보여준다.
- {50, 100, 500, 1000} sampling 단계에서의 TADA와 h-flip의 성능 추이를 보면, TADA는 h-flip보다 지속적으로 우수한 성능을 보인다.
- TADA는 대규모 모델에서는 뚜렷한 이점을 보였지만 소규모 모델에서는 효과가 떨어진다.
- 이러한 결과는 데이터 증강이 대규모 모델의 성능을 향상시키는 데 중요한 역할을 하기 때문에 예상되는 결과라고 논문에서 말한다.
Ablation Study
이 section은 TADA에서 각 구성 요소의 영향을 분석하기 위해 세 가지 ablation studies를 수행한다.
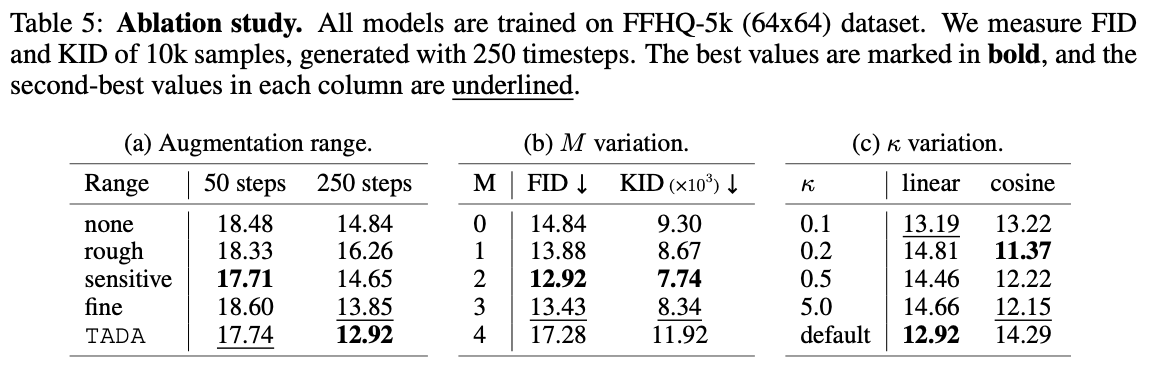
Augmentation Range
표 5a에서는 특정 timestep에서만 $w_t$를 적용하고 다른 범위에서는 $w_t = 0$으로 설정하여, $rough$, $sensitive$, $fine$에 대한 FID score를 측정한다.
baseline(h-flip)을 ‘none’으로 고려할 때, 각 timestep의 기여도는 sampling 단계에 따라 다르다.
- 50 sampling step에서는 sensitive timestep이 가장 영향력이 크다.
- 250 sampling step에서는 fine timestep이 가장 영향력이 크다.
sampling step에 관계없이 TADA가 다양한 범위에서 baseline model에 비해 명확한 개선을 보이는 것을 알 수 있다.
$M$ Variation
표 5b에서는 다양한 $M$ 값에 대해 TADA를 테스트하고, 250 sampling step에서의 FID score를 측정한다. $M = 0$ (h-flip)의 baseline model과 비교할 때,
- $M$이 적당히 작을 때(ex: $M=2$) 증강을 적용하는 것이 유익하다는 것을 알 수 있다.
- $M$이 너무 크면 train data 분포가 원본 train data로부터 너무 멀어져 학습을 방해할 수 있다.
이를 바탕으로, 논문에서는 모든 setting 에 대해 $M = 2$로 설정한다.
$κ$ Variation
TADA에서 $κ$의 영향을 평가하기 위해, linear과 cosine noise schedule에 대해 $κ$의 값을 조절하여 실험을 진행하였다.
표 5c는 $κ$를 변화시키며 얻은 FID score를 보여주는데, 직접 설정해준 $κ$가 default보다 성능이 우수한 것을 알 수 있다.
default는 $κ$가 자동으로 계산되는 것임
default가 합리적이지만, 더 나은 hyper-parameter tuning으로 TADA의 성능을 향상시킬 수 있음을 시사한다.
Discussion & Conclusion
Generative model을 위한 다른 데이터 증강 방법과 마찬가지로, TADA는 데이터 부족 문제를 완전히 해결할 수 없으며, 더 많은 데이터를 수집하는 것보다 덜 효과적이다. 또한, 논문에서 비교 실험을 위해 채택한 증강기법(h-flip, AR)은 GAN에서 일반적으로 사용되는 기법이므로 Diffusion model에 최적이 아닐 수 있다.
하지만, Diffusion model에서 데이터 증강과 분포 변화 사이의 관계를 처음으로 심층적으로 조사하였으며, 특정 timestep에서는 유의미한 영향을 미친다는 것을 알아내었다.
이를 바탕으로 시간 간격에 따른 데이터 증강 강도를 조절하는 방법인 TADA를 제안하였으며 간단하게 구현하더라도 Dataset, model 구성, Sampling step에 걸쳐 Diffusion model을 일관되게 향상시킬 수 있음을 보여주었다.
TADA는 데이터가 제한된 환경에서 Diffusion model의 성능을 효과적으로 개선하여 overfitting 문제를 해결하고 Transfer learning에서도 성능을 개선하였다.