[Paper Review] Transfomer - Attention Is All You Need
Transformer
- 선행 연구
RNN
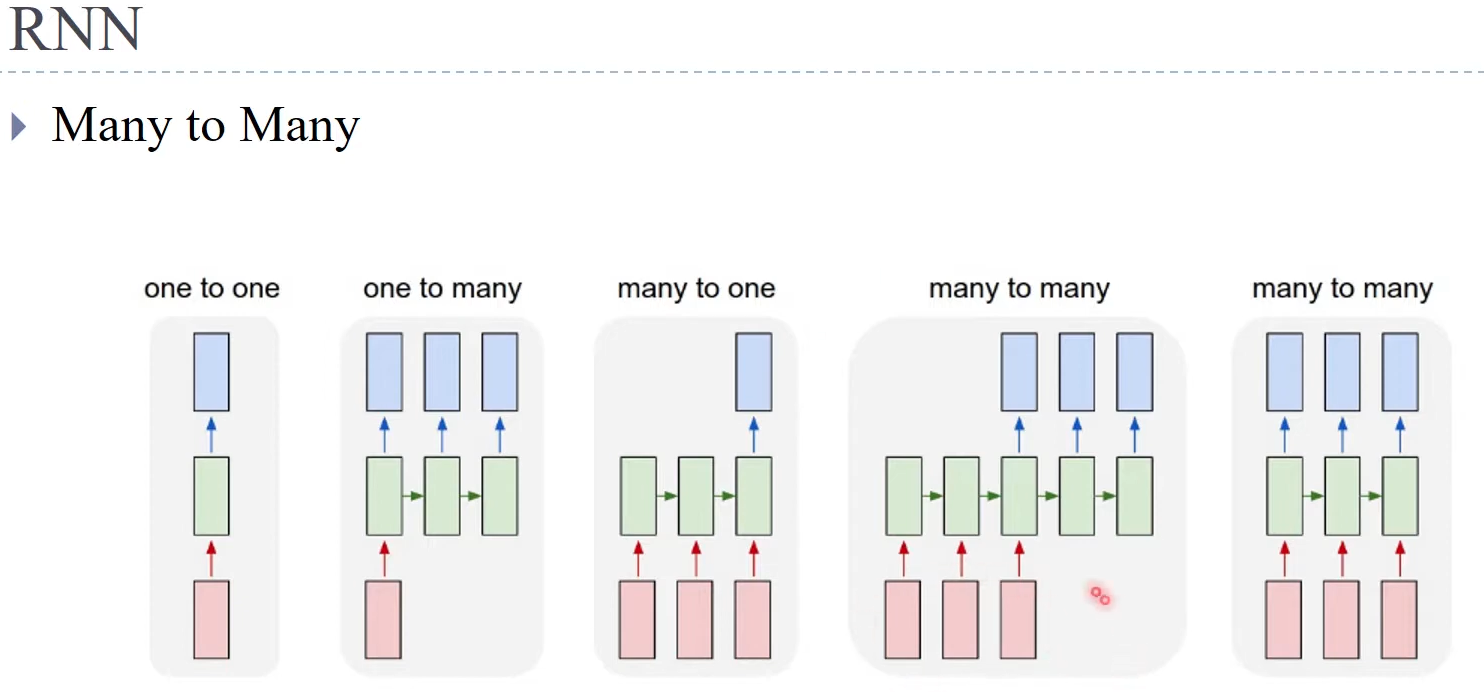
- 각 박스 - 단어
- 초록색 박스 - Neural Network, 단어를 벡터로 변환(워드 임베딩) 후 입력
- 현재 word vector를 이전의 값을 바탕으로 업데이트
- 워드 임베딩 - Word Embedding


- 맥락의 두 벡터에 weight를 곱하여 hidden layer로 만들고 다시 weight를 곱한 뒤 softmax를 취함
- ouput과 실제 원 핫 벡터의 loss를 구하고 이를 다음 layer로 전달
- 이전 값을 계속하여 사용하기 때문에 Gradient Vanishing이 발생 → 문장이 길면 성능 하락
- LSTM
과거의 값들 중 최근 기억을 사용하여 과거 기억을 수정
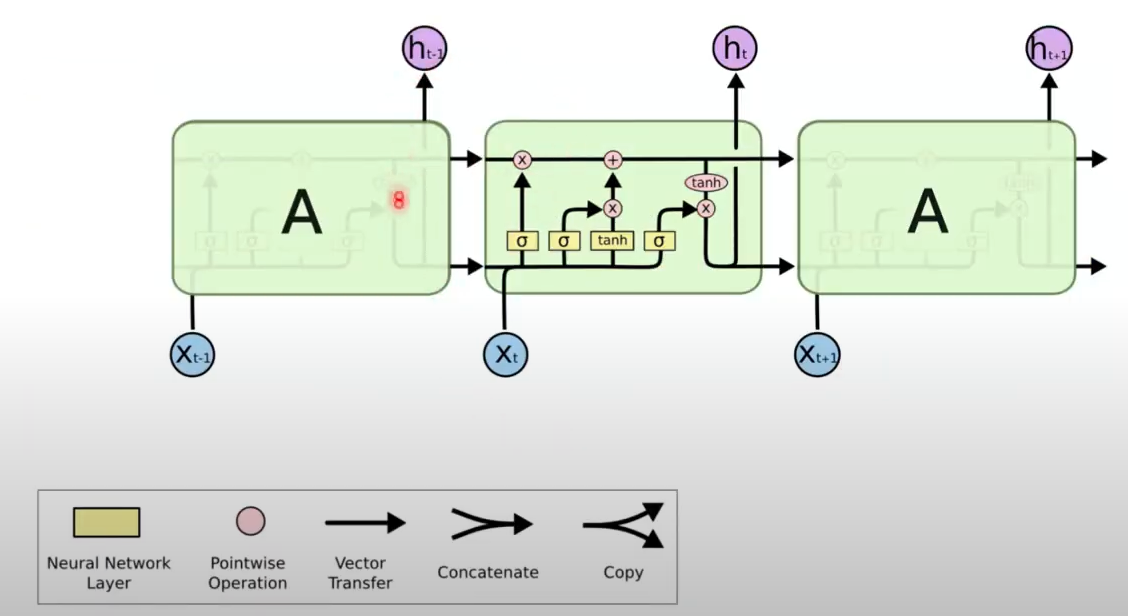
- 위 → 는 과거의 기억(Long term Memory). 아래 →는 최근 기억(Short Term Memory)
- 첫번째 Fully Connected Layer에 단기기억과 현재 word가 입력
- Sigmoid로 최근 기억을 0 ~ 1 사이로 만든 뒤, 장기기억의 중요도를 결정하는 요소가 됨
- 2, 3번째 layer에서도 tanh 함수와 sigmoid를 통해 최근 기억의 중요도를 결정 후 장기 기억에 반영
- 장기기억 정보는 다음 셀로 넘어가고, tanh와 sigmoid를 거친 최근 기억과 연산하여 다음 hidden state로 넘어가며 현재의 output이 됨
- GRU
- LSTM은 하나의 셀에 4개의 신경망이 있어 컴퓨팅이 느림 → GRU에서 3개로 줄임
Attention (2015)
- 문맥에 따라 집중할 단어를 결정하는 방식
Encoder, Decoder 구조
- Encoder : 모든 RNN 셀의 hidden state를 사용
- Decoder : 현재 셀의 hidden state만 사용
- 왜??
- 하나의 출력 단어와 입력 문장의 모든 단어의 Attention 상관관계를 비교하기 때문이다
- 즉 hidden state는 문맥으로 해석 가능
Attention 메커니즘
Encoder(h)와 Decoder(s)의 hidden state를 내적하여 Encoder의 셀 각각의 Attention Score를 구함
→ Attention Score = ${s_{t}}^{T} \cdot h_{i}$
Attention score를 $softmax$ 에 입력하여 Attention distribution을 구함 → 중요도를 0 ~ 1사이 확률로 표현
→ Attention distribution $a^{t} = softmax(e^{t})$
Encoder hidden state와 Attention distribution을 곱하고 더하여 Attention Value 행렬을 만든다.
→ Attention Value $\mathit {a}_{t} = \sum \alpha {_{i}}^{t}{h}_{i}$
- Decoder hidden state를 Attention Value 아래에 concatenate하여 Decoder의 문맥을 추가
- $tanh$, $sof]ㅣㅏ,tmax$ 등의 활성화 함수를 이용해 학습을 시켜 최종 출력 $y$를 얻을수 있다.
Transformer - Attention Is All You Need (2017)
RNN 계열 모델 없이 Attention 구조만 사용하여 만든 언어 모델
→ single Attention을 여러개 붙여 사용한 Multi-head Attention을 사용
Encoder 6개, Decoder 6개로 이루어진 구조
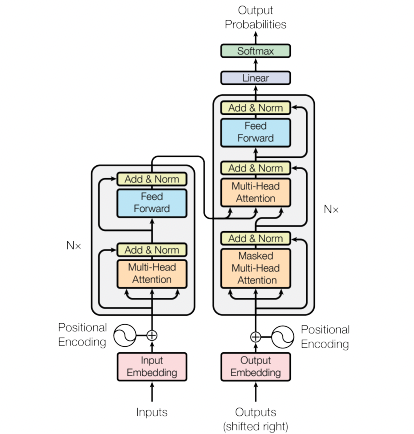
- Encoder 블록 각각은 Self-Attention, Neural Network으로 구성되어있다.
- Decoder 블록 각각은 Neural Network, Masked Self-Attention, Encoder-Decoder Selft-Attention으로 구성되어있다.
Multi Head Attention 과정
- 각 단어는 vector로 변환하고 Positional Ecoding을 통해 위치정보를 더하여 input vector를 만든다.
- 각 벡터는 self attention을 통해 동일 dimention의 output을 내보낸다.
- Self Attention : 단어 간의 연관성을 찾는 과정
- 들어온 Word Embedding값과 딥러닝의 weight값으로 Query, Key, Value vector를 구한다.
구하고자 하는 it의 Query vector를 문장의 모든 단어의 key vector와 내적하여 Attention Score를 구한다.
→ score가 가장 큰 벡터의 단어가 가장 의미적으로 유사한 단어 (자기 자신 제외)
Nomalize(차원 수로 나누고 softmax)하여 학습이 안정되게 한 후, 이를 value와 곱하여 최종 Attention Value를 구한다.
- Self Attention : 단어 간의 연관성을 찾는 과정
- 위 과정을 여러번 수행하면 Multi Head Attention이 된다.
- 여러개의 Attention에서 나온 벡터들을 concatenation하고 weight와 연산하여 초기 dimention을 맞춰준다.
Encoder
- Skip Connection와 Layer Nomalization을 거친 output을 Feed forward Neural Network로 입력
- Feed forward Neural Network
- $FFN(x) = max(0, xW_{1} + b_{1})W_{2} + b_{2}$
- 같은 인코더 내에서는 weight값 공유, 다른 인코더끼리는 공유 X
Decoder
- Masked Multi head Attention
- 앞에 나온 단어에만 Attention Score 부여, 뒤 단어들에는 0
- 뒤에 나온 단어를 넣지 않음으로써 치팅 방지
- 앞에 나온 단어에만 Attention Score 부여, 뒤 단어들에는 0
- Encoder Decoder Multi Head Attention

- Encoder의 Key와 Value를 Decoder에게 넘겨줌
- Decoder에 입력으로 들어오는 input vector는 넘겨받은 Key와 내적한 후에, Value를 곱해준다
이 output은 다음 Decoder에 Query로 들어가고, 또다시 넘겨받은 Key와 Value와 연산한다.
→ Decoder의 Query가 Encoder의 어떤 Vector에 더 많은 가중치를 두는지 결정
- Feed Forward Neural Network, Residual Connection, Layer Nomalization을 거쳐 문장의 각 단어별로 최종 Encoding된 단어 vector를 얻는다.
- 이를 선형 변환하여 target 문장의 언어의 vocabulary size크기의 벡터로 바꾸고, Softmax를 취하여 현재 단어의 다음에는 어떤 단어가 올지 확률분포를 구한다.
- 이 확률 분포와 실제 target문장의 오차를 줄이는 방향으로 학습을 진행.
요약
Encoder
- Source 문장의 단어들을 Positional encoding을 통해 위치정보를 더한 후 Multi Head Attention에 입력한다.
- Multi-head Attention
- 여러개의 head마다 Q, K, V를 만들고 연산하여 나온 output들을 모든 concatenation하고, 이를 weight와 연산하여 입력 vector와 같은 크기의 차원을 지니도록 한다.
- Residual Connection과 Layer Normalization을 적용한다.
- Feed Forward Neural Network
- 위 과정을 6번 반복
Decoder
- Target 문장에서 다음 단어로 어떤 단어가 올지 학습한다. (문장이 완성될때까지 예측을 반복, step)
- Masked Multi-Head Attention
- Positional Encoding된 Target 문장의 각 단어별 vector로 Q, K, V vector를 만든다.
- 뒤에 등장하는 단어의 정보는 학습에 방해되므로, Q K의 연산 결과에서 뒷 단어들의 Attention Score는 0으로 만든다.
- Residual Connection, Layer Normalization을 적용하여 최종 vector를 구한다.
- Encoder Decoder Multi Head Attention
- Masked에서 나온 Target 문장의 인코딩 vector가 Query가 되고, Encoder의 vector가 Decoder의 Key와 Value로 들어간다.
- Target문장의 각 단어는 Source 문장에서 어느 단어에 가중치를 많이 부여할 것인지를 구하여 인코딩 vector를 구한다.
- Residual Connection, Layer Normalization을 적용하여 최종 vector를 구한다.
- Feed Forward Neural Network
위 과정을 6번 반복
- 각 step별, 단어별로 선형 변환한 결과 vector에 softmax를 통해 다음에 어떤 단어가 올지 확률분포를 구한다.
- 이 확률 분포와 Target 문장의 실제 다음 단어가 같도록 오차를 줄이는 방향으로 Train