[Paper Review] Transfusion
[논문 리뷰] Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
Chunting Zhou, Lili Yu
2024.

Transfusion은 2024년 8월 Meta에서 공개한 이미지-텍스트 처리 멀티모달 모델로, Language Modeling loss(다음 토큰 예측)와 Diffusion을 결합하여 discrete(이산) 및 continuous(연속) 데이터 모두를 처리할 수 있는 단일 Transformer모델이다.
Background
Language Modeling
텍스트의 discrete한 특성을 modeling한다.
닫힌 어휘집 $V$의 discrete token $y=y_1, …, y_n$에서 언어 모델은 각 $y$의 확률인 $P(y)$를 예측한다. 이 모델은 $P(y)$를 조건부 확률의 곱으로 분해하여, 각 토큰 $y_i$의 확률 분포를 이전 토큰들 $y_{<i}$에 조건화하여 예측한다. 각 토큰의 확률 분포를 $\theta$로 매개변수화된 단일 분포 $P_\theta$를 사용하여 예측한다.
데이터 분포와 $P_\theta$ 사이의 cross entropy를 최소화함으로써 optimize하며, 이를 언어 모델링 손실(LM loss)이라고 한다. 이는 다음 token 예측에 대한 log likelihood의 negative한 기대값으로 정의된다. \(\mathcal{L}_{LM} = \mathbb{E}_{y_i} \left[ -\log P_\theta(y_i | y_{<i}) \right]\)
Diffusion
이미지의 continuous한 특성을 modeling한다.
Diffusion은 두 가지 프로세스를 포함한다. 1. noise를 추가하는 foward process와 2. 모델이 학습하는 reverse process의 denoising이다.
Transfusion에서는 condition $c$가 포함된 Markov chain의 DDPM loss를 차용하였으며, 자세한 설명은 [Paper Review] DDPM을 참고하면 된다. \(\mathcal{L}_{DDPM} = \mathbb{E}_{x_0, t, \epsilon} \left[ ||\epsilon - \epsilon_\theta(x_t, t, c)||^2 \right]\)
Latent Image Representation
초기 Diffusion 모델은 픽셀 공간에서 직접 작동했지만, 이는 계산 비용이 많이 드는 방식이다. VAEs는 이미지를 더 낮은 차원의 latent space으로 인코딩하여 계산 비용을 절감할 수 있다. 이를 통해Latent Diffusion Models(LDMs)이 효율적으로 운영될 수 있도록 컴팩트한 이미지 패치 임베딩을 가능하게 한다. 예를 들어, 8×8 pixel patch가 8차원 vector로 표현될 수 있다.
Language Modeling에서는 이미지를 이산화해야 한다. 대표적인 Discrete AutoEncoders, VQ-VAE는 연속적인 latent embedding을 discrete token으로 매핑하는 양자화 layer를 도입함으로써 이를 달성한다. 이 방법은 이미지를 discrete token sequence로 변환하여, 언어 모델을 사용하여 모델링할 수 있게 한다.
(추가) Chameleon
같은해 2024년 5월, Meta에서 공개한 Chameleon은 별도의 인코더나 디코더의 사용 없이, 단일 프레임워크에서 이미지와 텍스트를 통합하고 생성하는 방식을 제시하였다.
Chameleon은 이미지를 텍스트를 동일한 방식으로 처리할 수 있는 discrete 토큰으로 변환한다. 이미지의 continuous한 특성을 그대로 활용하는 transfusion과는 상반된 방식이다.
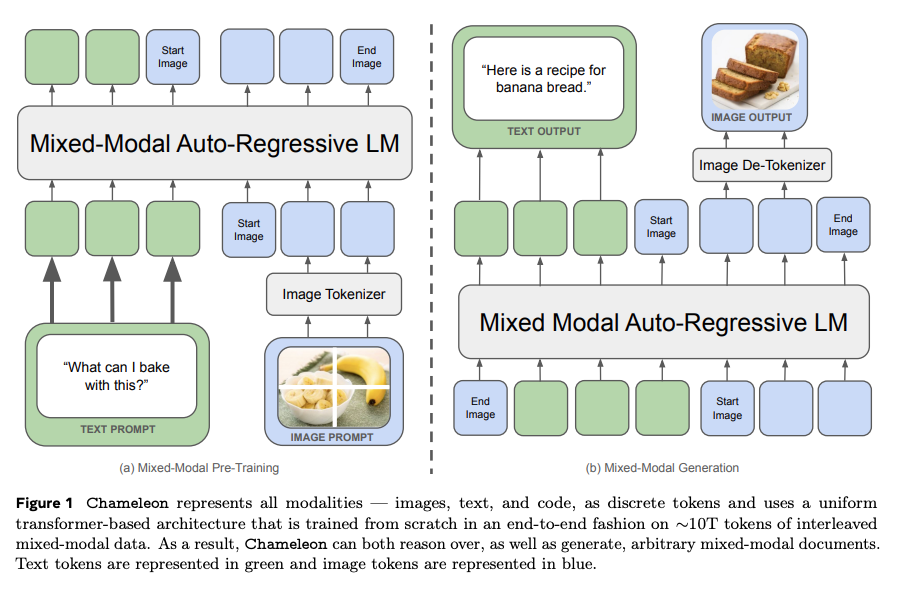
VQ-VAE를 사용하여 이미지의 각 patch를 token으로 변환하여 텍스트 단어와 유사하게 취급한다. 텍스트와 이미지를 입력 단계에서부터 결합하여 텍스트와 이미지가 통합된 토큰 기반 표현(unified token-based representation)을 통해 동일한 Transformer 아키텍처 내에서 처리할 수 있게 된다.
Transfusion
Data Representation
Transfusion에서는 Chameleon처럼 텍스트와 이미지 데이터를 동일한 시퀀스로 처리하기 위해 각각의 데이터를 적절한 형태로 변환한다.
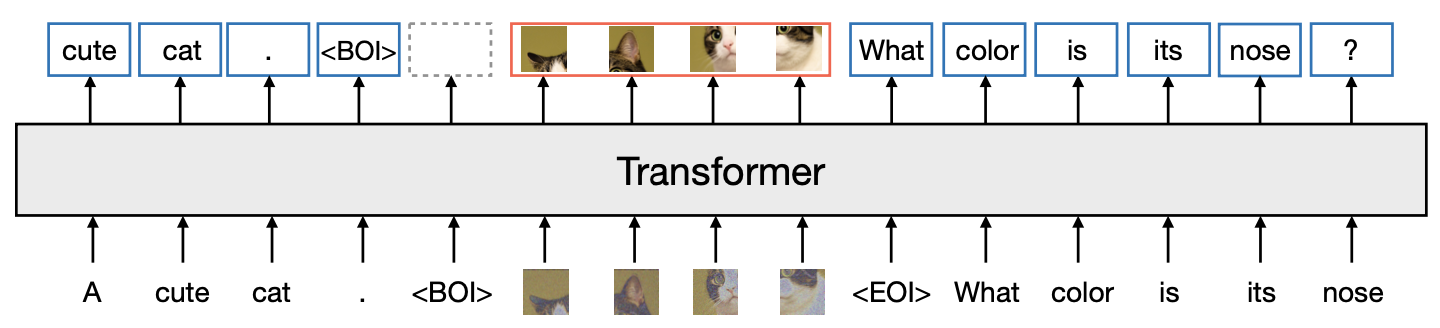
텍스트는 일반적으로 사용되는 언어 모델링 기법에 따라 고정된 어휘에서 discrete token으로 변환되며 트랜스포머 모델에 의해 처리된다.
이미지는 VAE를 통해 latent vector patch로 인코딩된다. continuous한 벡터로 표현되며, 이미지를 Transformer에서 처리할 수 있도록 변환하는 역할을 한다.
변환된 이미지는 BOI(시작), EOI(종료) token으로 둘러싸여 텍스트 시퀀스에 삽입된다. 이 결합된 시퀀스는 모델의 입력으로 사용되며, 이를 통해 텍스트와 이미지 데이터를 동시에 처리할 수 있다. discrete와 continuous한 데이터를 동시에 포함된 sequence는, 동일한 모델에 의해 처리되기 때문에 일관된 방식으로 통합된다.
Model Architecture
단일 Transformer는 고차원 벡터의 시퀀스를 입력으로 받고 유사한 벡터를 출력으로 생성한다. 데이터를 이 공간으로 변환하기 위해, 텍스트와 이미지에 대해 각각 다른 모델링을 적용하는 경량 모달리티별 구성 요소를 사용한다.
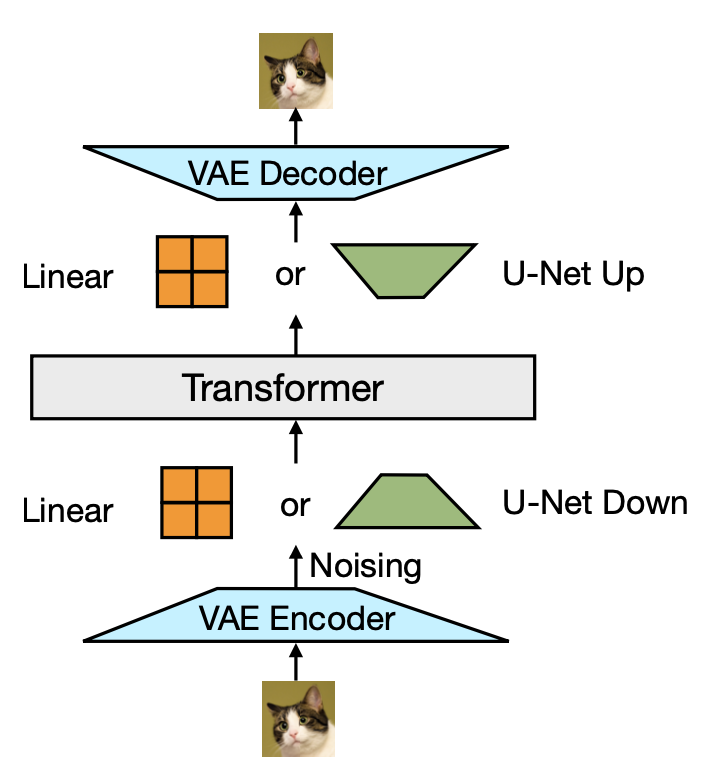
텍스트의 경우, 임베딩 matrix가 각 input 정수를 벡터 공간으로 변환하고 각 출력 벡터를 어휘에 대한 이산 분포로 변환한다.
이미지의 경우, $k × k$ patch 벡터의 local window를 단일 Transformer 벡터로 압축하는 두 가지 방법을 실험했다. (1. 선형 layer, 2. U-Net의 Up & Down blocks)
Transfusion Attention
Text의 경우, 언어 모델에서 일반적으로 사용되는 기법인 causal attention이 적용된다. causal attention은 각 token이 이전 token들에만 의존하도록 하여, 텍스트 생성 시 순서를 유지하면서 자연스럽게 생성한다.
Image는 텍스트와 달리 순차적인 요소가 아니기 때문에, bidirectional attention(양방향 어텐션)을 적용한다. 같은 이미지 내 모든 patch들에 대해 attention을 적용하여 patch 간의 정보를 자유롭게 교환할 수 있다.

Transfusion은 시퀀스의 모든 요소에 대해 causal attention를 적용하고, 각 이미지의 patch 내에서 bidirectional attention를 적용함으로써 두 Attention을 결합한다. 이를 통해 각 이미지 patch가 동일한 이미지 내의 다른 patch과 attention을 적용하면서, 시퀀스에서 이전에 나타난 텍스트나 다른 이미지의 patch들에만 attention을 적용할 수 있다. 이러한 내부 이미지 주의는 모델 성능을 크게 향상시킨다.
Training Objective
Language Modeling objective $L_{LLM}$과 Diffusion objective $L_{DDPM}$을 결합한다.
$L_{LLM}$은 token별로 계산되며, $L_{DDPM}$은 여러 요소(이미지 패치)를 포함할 수 있는 시퀀스 내의 이미지별로 계산된다. 두 loss는 각 모달리티에 대해 계산된 손실을 단순히 더함으로써 결합된다.
\[\mathcal{L}_{\text{Transfusion}} = \mathcal{L}_{\text{LM}} +\lambda \cdot \mathcal{L}_{\text{DDPM}}\]Inference
Inference과정은 Training Objective를 반영하여 LM 모드와 Diffusion 모드 사이를 전환하면서 이루어진다.
LM 모드: 추론 과정이 시작될 때, 모델은 표준 언어 모델의 텍스트 생성 방식을 따른다. 즉, 예측된 분포에서 토큰을 하나씩 샘플링하여 텍스트를 생성한다. 이 때, BOI(Begin of Image) token을 샘플링하면, 모델은 Diffusion 모드로 전환된다.
Diffusion 모드: Diffusion 모드에서는 표준 Diffusion 모델의 이미지 생성 절차를 따른다. 구체적으로, 입력 시퀀스에 noise $x_T$를 추가하고, $T$ 단계에 걸쳐 denoising하며 이미지를 복원한다. 각 단계 $t$에서, 모델은 $x_t$에서 누적된 noise를 예측하고, 이를 통해 $x_{t-1}$을 생성하여 시퀀스에서 $x_t$를 대체한다. 모델은 항상 noise가 첨가된 이미지의 마지막 timestep에 condition $c$를 추가하며, Diffusion 과정이 완료되면 예측된 이미지에 EOI(End of Image) token을 추가하고, 다시 LM 모드로 전환한다.
Experiments
Set Up
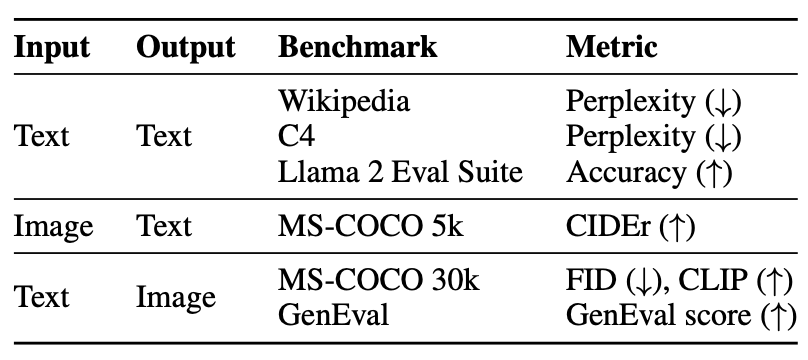
Evalutation
평가는 위 table의 벤치마크를 사용하여 평가된다.
- Text - Text : Wikipedia와 C4 코퍼스에서 2천만 개의 유보된 토큰에 대한 혼란도를 측정하고, Llama 2의 사전 훈련 평가 스위트의 정확도를 측정한다.
- Text - Image : MS-COCO 벤치마크를 사용하여 검증 세트에서 무작위 3만개의 prompt에 대해 생성된 이미지의 사실성을 측정하며, prompt와의 일치도를 CLIP score로 평가한다. 또한, 모델이 이미지 캡션을 생성하는 능력을 Karpathy의 MS-COCO 테스트 분할에서 CIDEr 점수를 사용하여 보고한다.
Baseline
현재 텍스트와 이미지 모두를 생성할 수 있는 단일 Mixed-modal 모델을 훈련하는 주요 방법은 이미지를 discrete token으로 양자화하고 표준 언어 모델로 전체 토큰 시퀀스를 모델링하는 것이다. 대표적으로, Chameleon을 Transfusion 모델과 직접 비교한다.
Chameleon과 Transfusion의 주요 차이점은 Chameleon이 이미지를 양자화하여 토큰으로 처리하는 반면, Transfusion은 이미지를 연속 공간에서 유지하여 양자화 정보의 병목 현상을 제거한다는 것이다.
Latent Image Representation
연구팀은 $86M$개 parameter의 VAE를 사용하여 이미지를 latent space에 인코딩한다. 이 VAE는 CNN Encoder와 Decoder를 사용하며, latent dimention은 8이다. Training Evalution은 Reconstruction loss와 Regularization loss를 조합한다. 이 구현은 $256\times256$ 픽셀의 이미지를 $32\times32\times8$ tensor로 줄이며, 개념적으로 각 8차원 latent pixel은 원본 이미지의 $8\times8$ 픽셀 패치를 대표한다. VQ-VAE에는 동일한 설정을 사용하지만, 표준 codebook commitment loss로 $L_{KL}$을 대체하고, 16,384 token 유형의 codebook을 사용한다.
Controlled Comparison with Chameleon
실험 결과, 모든 벤치마크에서 Transfusion이 Chameleon보다 우수한 스케일링을 보여준다.
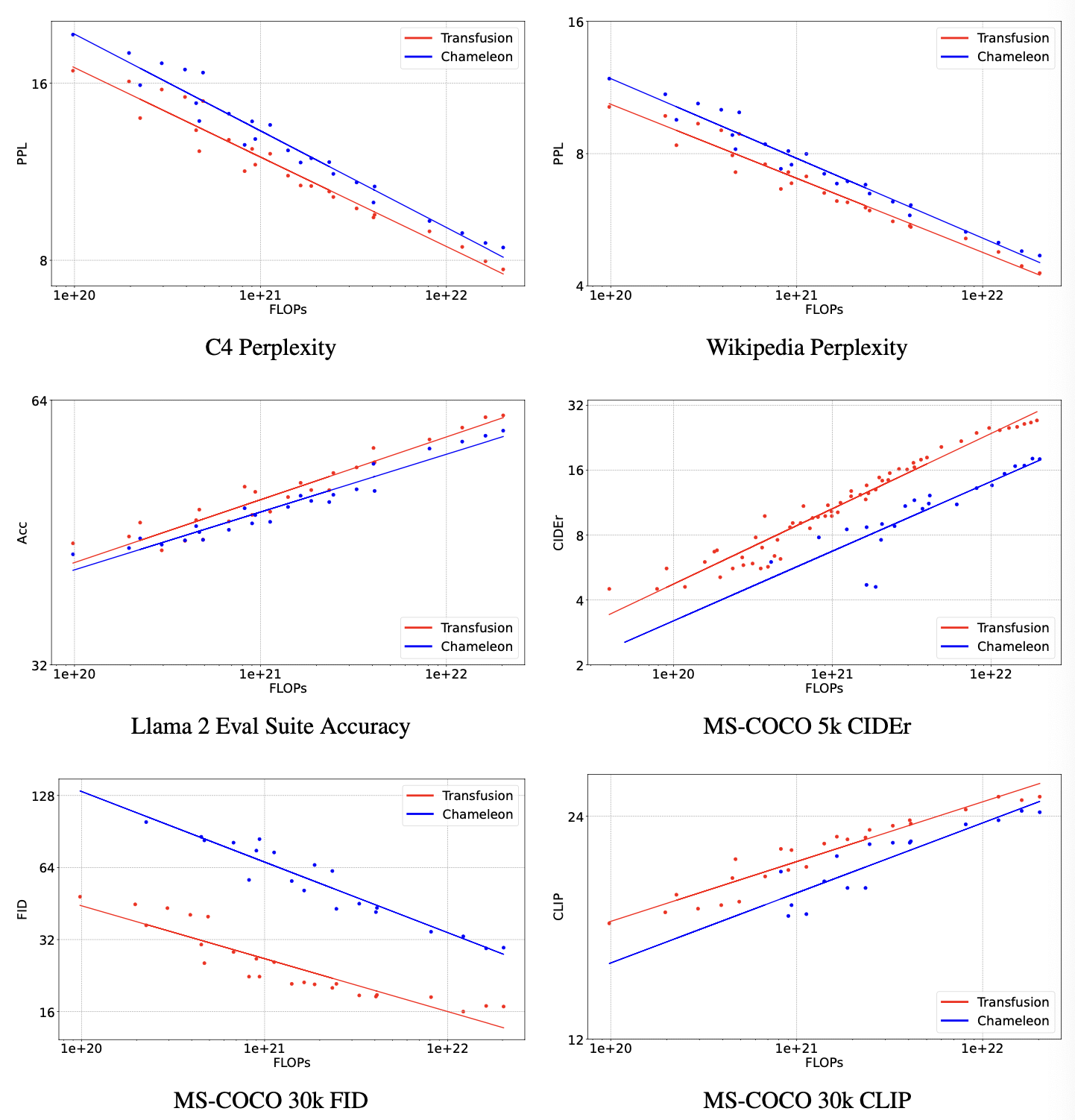
특히 이미지 생성 metric 중 FID score에서 Transfusion이 Chameleon보다 34배 더 적은 계산을 사용하여 동등한 성능을 달성한다.
텍스트 전용 벤치마크에서도 Transfusion이 더 나은 성능을 보이는데, 이는 두 모델이 텍스트를 동일한 방식으로 모델링하지만, Transfusion이 텍스트 성능을 더 효과적으로 향상시킬 수 있음을 시사한다.