[Paper Review] UniReal: Universal Image Generation and Editing via Learning Real-world Dynamics
[논문 리뷰] UniReal: Universal Image Generation and Editing via Learning Real-world Dynamics
UniReal: Universal Image Generation and Editing via Learning Real-world Dynamics
Xi Chen, Zhifei Zhang, He Zhang, Yuqian Zhou, Soo Ye Kim, Qing Liu, Yijun Li, Jianming Zhang, Nanxuan Zhao, Yilin Wang, Hui Ding, Zhe Lin, Hengshuang Zhao
CVPR 2025
[Arxiv] [Project Page]
Adobe + The University of Hong Kong의 공동연구
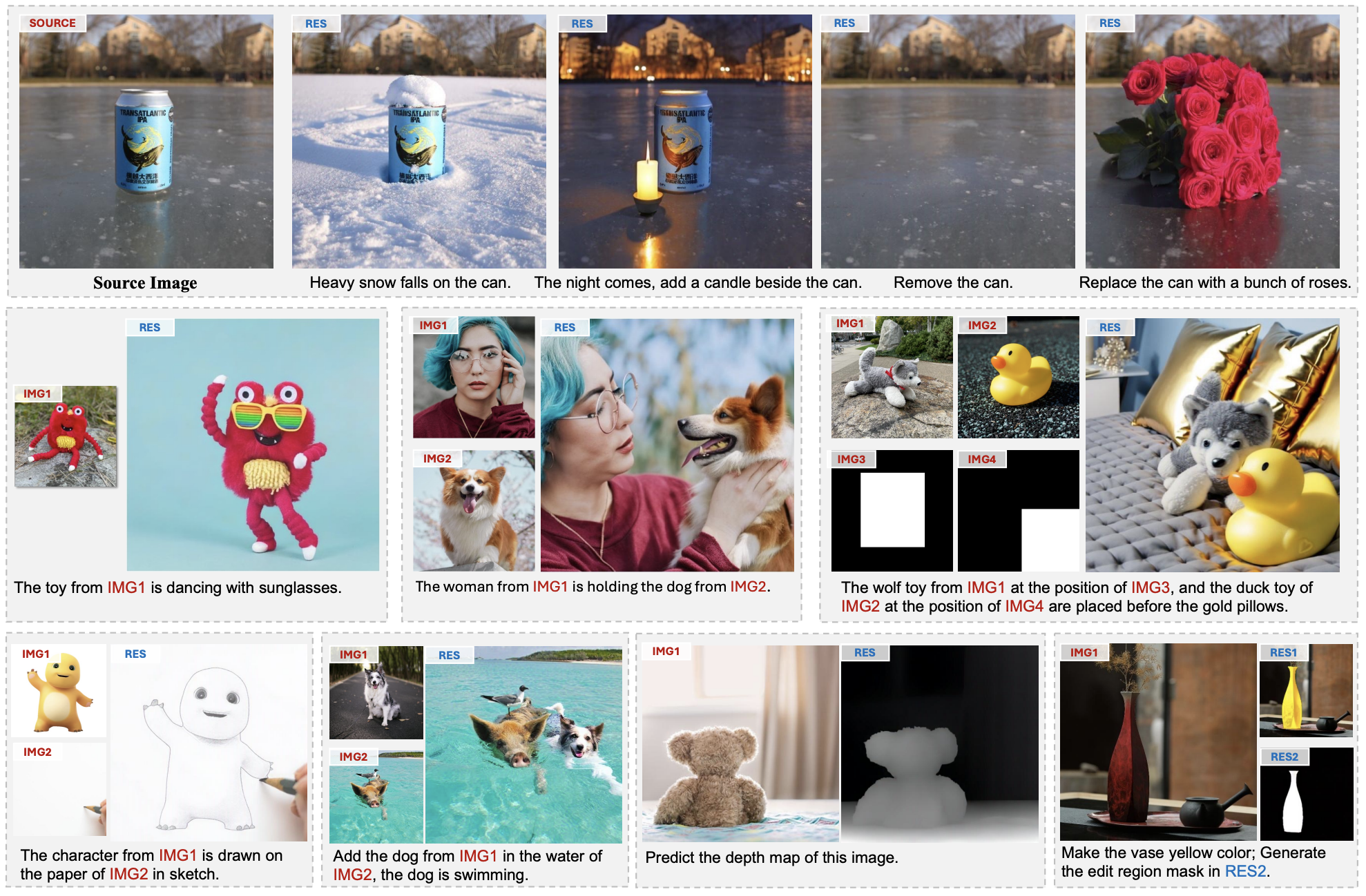
Introduction
이 논문에서는 Diffusion 모델로 인해 발전된 Image Generation & Editing 등의 다양한 task를 통합할 수 있는 프레임워크를 개발한다.
프레임 간 consistency과 variation의 균형을 효과적으로 맞추는 OpenAI의 비디오 생성 모델 Sora에서 영감을 받아, Image-level task를 불연속적인 비디오 생성으로 취급하는 통합 접근 방식 UniReal을 제안한다.
다양한 수의 Input/Ouput 이미지를 프레임으로 취급하여 이미지 생성, 편집, 커스터마이징, 합성 등의 작업을 원활하게 지원할 수 있다. Image-level task을 위해 설계되었지만 비디오를 supervision을 위한 source로 활용한다.
UniReal은 대규모 동영상에서 다양한 현상과 상호작용을 학습하여 그림자, 반사, 포즈 변화, 물체 상호 작용을 처리하는 고급 기능을 보여준다.
Method
1. Model Design
Diffusion transformer
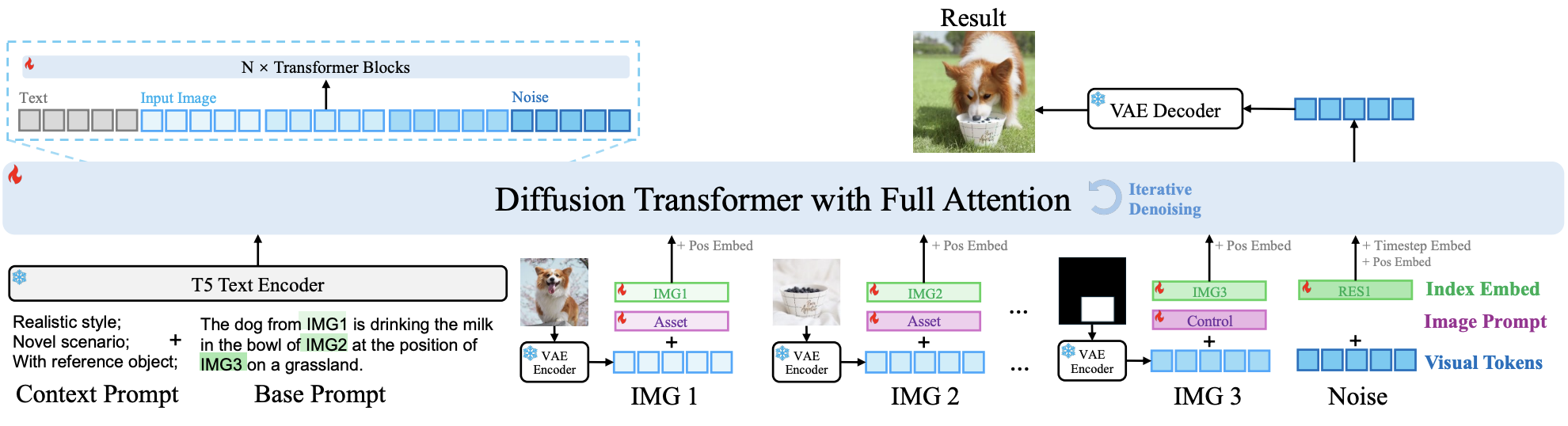
UniReal은 Input/Output 이미지를 비디오 프레임으로 취급하고 프롬프트를 사용하여 다양한 task를 수행한다.
이미지는 VAE를 통해 latent space로 인코딩되고, visual token에 인덱스 임베딩을 추가하여 순서를 구분하고 이미지의 역할을 나타내는 image prompt를 추가한다.

위 figure는 image prompt의 효과를 보여준다. position 임베딩은 각 image 토큰과 noise 토큰에 추가되고, timestep 임베딩은 noise token에 추가되며, text 토큰은 T5 인코더를 통해 추출된다.
image, noise, text 토큰은 1D tensor로 연결하여 Transformer에 입력된다. Transformer는 이미지와 텍스트 프롬프트 사이의 관계를 모델링하기 위해 Full attention을 사용한다.
Text-image association
텍스트 prompt에서 특정 이미지를 참조하기 위해, 우리는 visual 토큰과 해당 텍스트를 연결하는 임베딩 쌍을 구성한다.
예를 들어, IMG1과 IMG2 같은 참조 단어를 사용하여 Input 이미지를, RES1과 RES2를 사용하여 output 이미지를 참조하고 T5 tokenizer에 특수 토큰으로 추가한다. 동시에 각 참조 단어에 대한 이미지 인덱스 임베딩을 학습하고 해당 이미지의 토큰에 추가한다.
Hierarchical prompt
다양한 task 혹은 dataset은 동일한 input을 다르게 처리한다.
예를 들어 같은 prompt가 있을 때, Image Editing은 Input 이미지에서 local 변화를 만들지만, Image Generation은 reference 객체만 보존하고 완전히 다른 이미지를 생성한다. 이는 train 및 inference에서 모호성을 유발한다. 이러한 모호성을 줄이기 위해 Hierarchical(계층적) prompt를 제안한다.
base 프롬프트 외에도, context prompts와 Image prompt를 설계하여 detail한 설명을 추가한다.
context prompt
“realistic/synthetic data”, “static/dynamic senario”, “with reference object”와 같은 task와 데이터 source에 대한 Attribute 태그를 제공한다.
일부 keyword는 task 간에 공유되어 각 task들이 공통된 feature를 학습하도록 할 수 있다. 텍스트는 자연스러운 구성이 가능하기 때문에, 다양한 context prompt를 조합하여 새로운 기능을 구현할 수 있다.
Image prompt
input 이미지의 특정 역할을 나타낸다. 입력 이미지는 다음과 같이 세 가지로 분류된다
- canvas image
- 편집 대상의 배경으로 고정된 레이아웃을 제공한다.
- asset image
- image customization이나 composition을 위한 reference 객체나 시각 요소를 제공한다.
- 모델이 segmentation하고 객체의 크기/위치/자세 변화을 시뮬레이션한다.
- control image
- 레이아웃이나 형태를 규제하는 mask/edge/depth map을 제공한다.
- 모델은 각 map에 따라 learnable한 category 임베딩을 설계하고 해당 image 토큰에 image prompt로 추가한다.
Inference 중에는 context 프롬프트와 image 프롬프트를 자동으로 분석하며, 사용자는 task 및 image 프롬프트를 수동으로 수정할 수 있다.
2. Data Construction
다른 method와는 달리, UniReal은 비디오 데이터를 사용하여 비디오 프레임 사이의 자연스러운 변화를 활용한다.
Data construction pipline
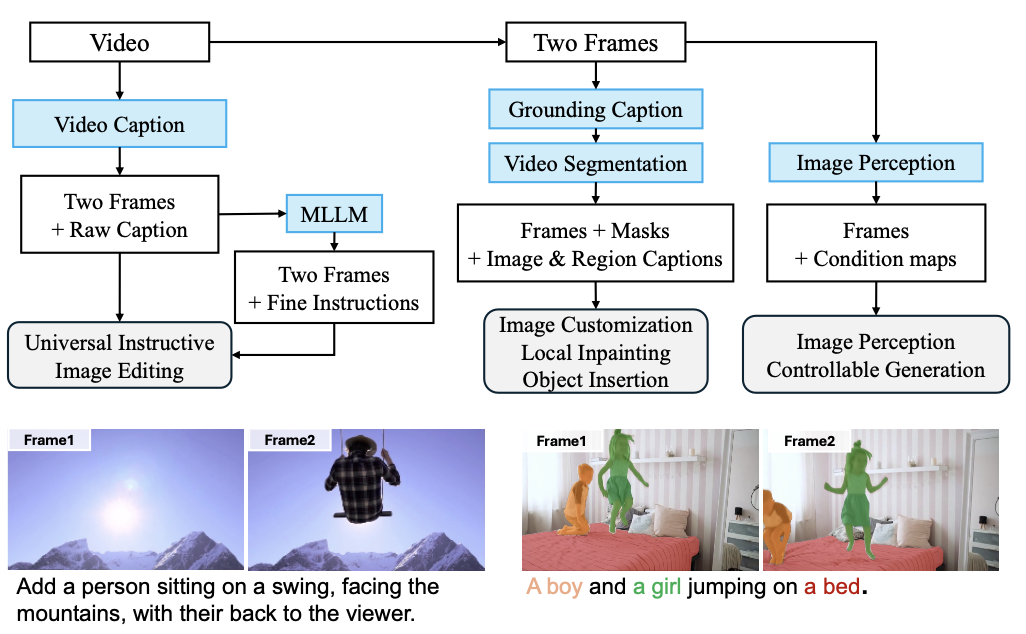
위 figure는 비디오 source에서 다양한 task에 사용되는 데이터셋을 구축하는 파이프라인이다.
- Video caption 모델을 사용하여 video-lavel caption을 얻는다.
- 무작위 2개의 프레임을 선택하고 caption을 instruction으로 사용한다.
이렇게 얻어진 데이터 유형을 Frame2Frame이라고 하며 기본적인 편집 능력을 train할 수 있는지 관찰한다. 20만개의 고품질 sample의 하위 집합에 대해 GPT-4o mini를 사용하여 보다 정확한 instruction을 얻는다.
또한,
- Kosmos-2를 사용하여 2개의 프레임에 대하여 bounding box와 caption을 생성한다.
- 한 프레임의 bounding box를 SAM2의 프롬프트로 사용하여 2개 프레임의 mask traklet을 얻는다.
이러한 데이터 유형은 Image Customization(Video Multi- object), object insertion (Video Object Insertion), local inpainting (Video ObjectAdd) 등을 지원할 수 있다.
Image Customization의 경우 한 프레임에서 각 객체를 segmentaion하여 다른 프레임을 생성하기 위해 reference로 사용한다.
또한, Kosmos-2로 라벨링된 maks와 caption을 재사용하여 referring segmentation (Video SEG)을 지원하며, 이미지 인식 모델을 사용하여 depth/edge map을 추출한다.
Training data overview
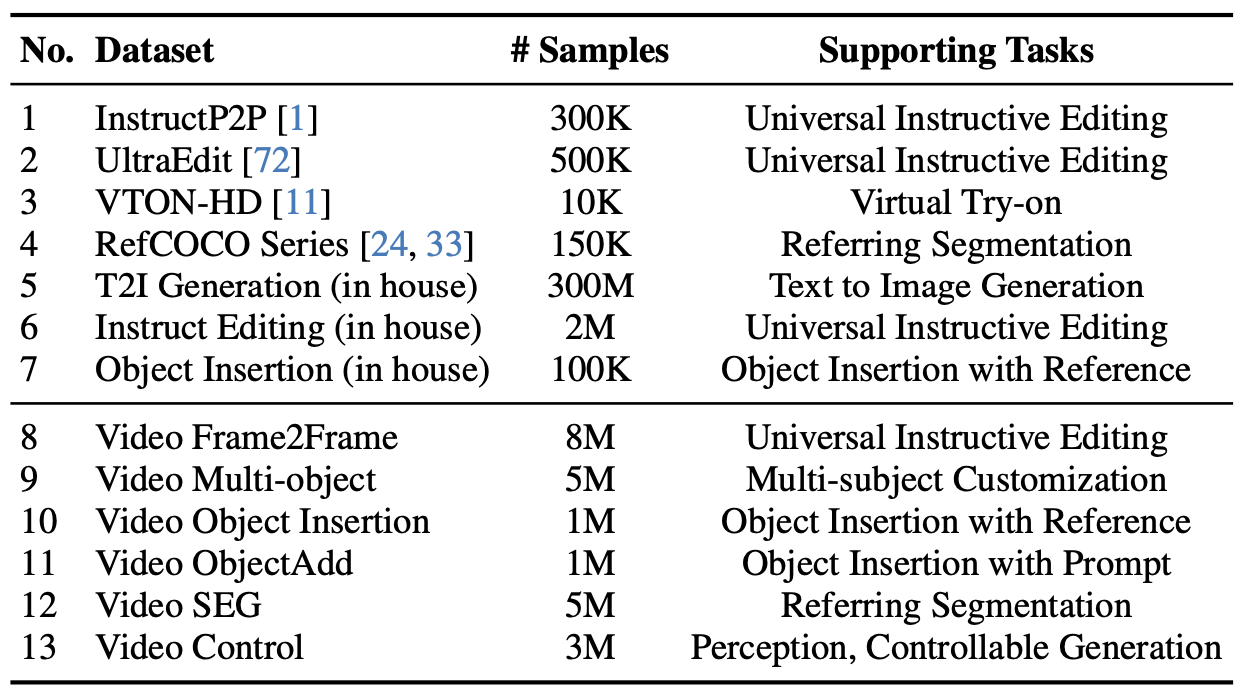
Train에 사용된 데이터셋은 위와 같다. 구축한 video-based 데이터셋 외에도 특정 task을 위한 오픈 소스 데이터와 instructive image editing과 reference-based object insertion을 위한 자체 데이터셋을 사용한다.
Image Editing 데이터를 구축하는 데 어려움을 고려할 때, 공개 데이터셋은 제한적이지만, Video-based 데이터는 확장성이 좋다.
Method-1.Model Design에서 설명한 것처럼, 이러한 데이터셋을 context prompt와 통합하는 것이 중요하다.
예를 들어,
Frame2Frame의 일부는 instruction에 의해 포착되지 않은 배경 움직임과 카메라 동작과 같은 변화가 존재한다. 이 경우, 프레임 간의 Optical Flow와 Pixel MSE를 분석하여 각 샘플에 “static/dynamic scenario”를 라벨링한다.
- instructive editing 데이터셋인 InstructP2P와 UltraEdit은 “synthetic style”로 태그하고 실제 이미지 데이터셋에 “realistic style”로 context prompt를 준다.
- Video Object Insertion에는 “with reference objects”로 context prompt를 주고, 모델이 mask나 depth map을 예측할 때는 “perception task”을 준다.
3. Trainging schemes
Transformer 모델 train 프로세스는 다음과 같다:
$256 \times 256$ 해상도에서 Text-Image, Text-Video 데이터셋을 사용해 pretrain된다.
위 표에 나온 데이터셋을 통합하여 여러 Image Generation/Editing task을 $256 \times 256$ 해상도에서 학습시킨다.
해상도를 $512$에서 $1024$까지 점진적으로 증가시켜, 다양한 크기의 가로/세로 비율을 가진 이미지들을 처리할 수 있게 한다.
Flow matching에 기반한 loss를 사용하며, warm-up과 함께 $1e-5$의 learning rate를 적용한다.
Experiments
1. Comparisons with Existing Works
UniReal은 다양한 task를 지원하지만 다음과 같은 대표적인 3가지 task에서 비교/분석한다.
- instructive image editing
- customized image generation
- object insertion
instructive image editing
사용자가 자유 형식의 프롬프트(예: 객체 추가/삭제, 속성 또는 스타일 변경 등)를 제공하면, input 이미지를 편집하는 작업이다.

여러 SOTA 모델들과의 비교를 보여준다.
UniReal은 물 속의 코끼리처럼 크기와 상태를 시뮬레이션하거나, 오리 장난감을 그림자까지 자연스럽게 제거하는 등 까다로운 task를 처리하는 데에 뚜렷한 강점을 보인다. 세 번째 예시에서는 UniReal이 개미와 자동차 사이의 상호작용을 이해하고 수면에 반사된 자동차까지 모델링하는 데 성공한다.
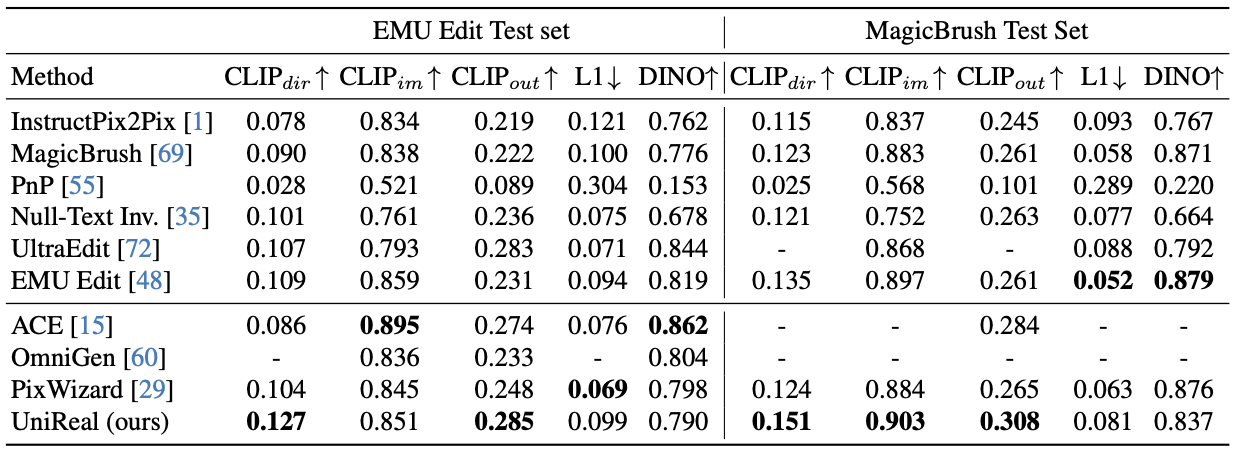
위는 2가지 test set에서의 정량적 결과를 보여준다.
• $\text{CLIP}_{dir}$: 텍스트 변화와 이미지 임베딩 간 변화의 일치 정도
• $\text{CLIP}_{out}$: 결과 이미지와 기대 출력 설명 간 유사도
• $\text{CLIP}_{im}$, $\text{DINO}$, $\text{L1}$: 결과 이미지와 Input 이미지 간 유사도
UniReal은 CLIPdir, CLIPout, 그리고 MagicBrush 세트에서의 CLIPim에서 sota를 달성한다. 결과가 input 이미지와 달라지는 것을 목표로 하기 때문에 DINO 및 L1 score가 낮은 것은 자연스러운 현상이다.
Customized image generation
reference 객체의 detail을 유지하면서 새로운 텍스트 프롬프트를 따라 생성하는 task이며 DreamBench 데이터셋을 사용한다.

UniReal은 reference의 로고나 detail를 정확히 보존하면서 고양이가 나무를 타는 등 상당히 다른 변화도 자연스럽게 처리하다. 또한 서로 다른 객체들 간의 상호작용까지 자연스럽게 모델링하는 것을 볼 수 있다.
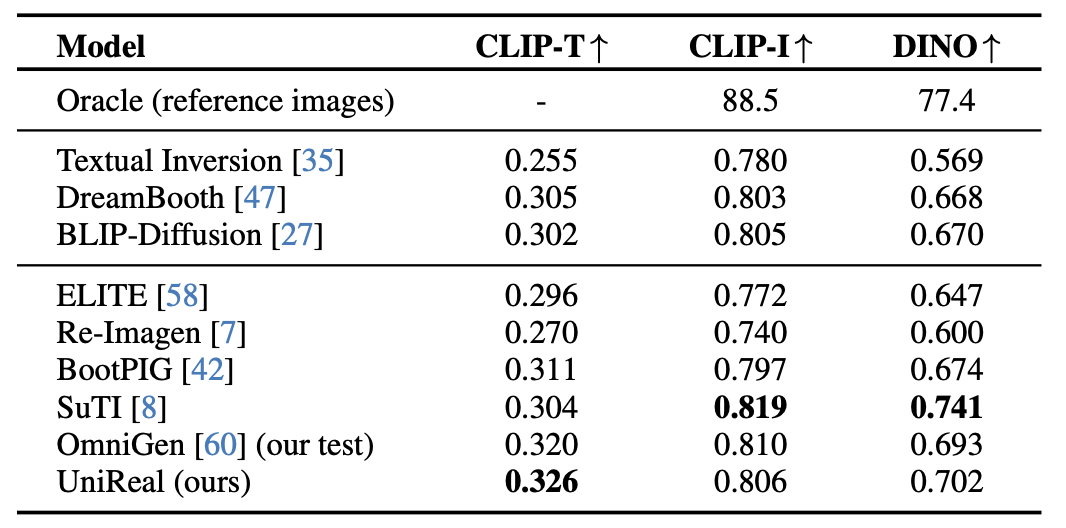
• CLIP-T : 생성된 이미지와 프롬프트 간의 유사도
• CLIP-I, DINO는 생성 이미지와 reference 이미지 간의 유사도
UniReal은 CLIP-T에서 가장 높은 점수를 기록하며 텍스트 프롬프트와 유사하게 생성되었음을 알 수 있다.
일부 프롬프트는 객체의 attribute 변경을 포함하고 있기 때문에 텍스트 응답성과 생성 fidelity 사이의 trade-off가 존재하지만, 그래도 UniReal이 상당히 높은 점수를 기록하고 있음을 알 수 있다.
Reference-based object insertion

객체를 삽입하는 task를 AnyDoor 모델과 비교한 결과이다.
AnyDoor는 reference 객체와 대상 위치 둘 다 mask map이 필요하다.
UniReal은 mask 없이 텍스트 프롬프트만으로 삽입 위치와 객체 변형을 자연스럽게 수행할 수 있다.
2. Analysis for the Core Components
Hierachical prompt
base prompt에 image prompt와 context prompt를 확장하여 추가하는 Hierachical prompt의 도입을 비교해보자.
동일한 (input 이미지, base prompt) 라도, image prompt(1행) 또는context prompt(2행)에 따라 전혀 다른 생성 결과가 나올 수 있으며, Hierachical prompt 설계를 통해 다양한 task과 데이터 source를 통합할 때의 모호성을 효과적으로 줄였음을 확인할 수 있다.
Training data

① Video Frame2Frame 데이터만 사용,
② Task 별 Expert 데이터만 사용 (3가지 task의 맞는 dataset)
③ Full dataset.
Frame2Frame 데이터만으로 학습된 모델도 다양한 editing task을 수행할 수 있음을 확인할 수 있다. Frame2Frame은 단일 input 이미지만 포함되지만, 훈련된 모델이 다중 입력 이미지까지도 부족하지만 처리할 수 있음을 확인할 수 있다. 이는 Frame2Frame이 supervision으로서 매우 유망함을 시사한다.
다만, 스타일 변경 등 일부 downstream task을 포함하지 못하고, instruction을 정확히 이해하지 못하는 경우도 있다. 이럴 때는 Task 별 Expert 데이터가 표준 학습 예시로서 여전히 필요하다.
Quantitative Analysis
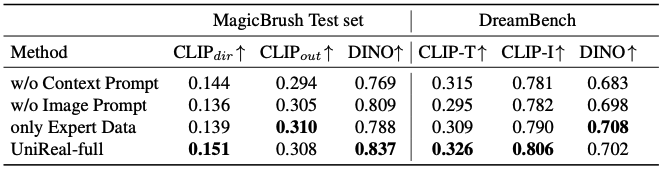
MagicBrush와 DreamBench에서 비교 진행
3. More Applications

왼쪽은 train 데이터를 통해 지원하는 다양한 task들이며, 오른쪽은 훈련되지 않은 상태에서도 일반화 능력으로 가능한 새로운 task들을 보여준다.
왼쪽 : Trained Tasks
Text-to-Image Generation
Controllable Generation
- depth/edge map 등 condition을 통해 생성
Reference-based Inpainting/Outpainting
- 마스킹된 이미지의 빈 부분을 다른 reference 이미지로 채움
Image Understanding
텍스트에서 지시된 객체의 영역만 정확하게 분리
이미지로부터 객체의 depth map을 예측
Multiple Outputs
- 하나의 프롬프트나 입력에 대해 여러 결과 이미지를 한 번에 생성
오른쪽 : Novel Abilities & Zero-shot Generalization
- Multi-object Insertion
- 여러 reference 객체를 동시에 삽입
- Insertion with Editing
- 삽입하면서 색상, 포즈 등 속성 변경
- Local Reference Editing
- 특정 mask 영역만 reference 이미지에 따라 편집
- Layer-aware Editing
- 배경과 전경을 구분하여 배경 레이어에만 삽입/편집
- Object Moving/Resizing
Conclusion
UniReal은 다양한 이미지 생성 및 편집 작업에서 State-Of-The-Art을 달성하며, 현실 세계의 동역학(world dynamics)을 이해하고 새로운 작업으로 일반화할 수 있는 가능성을 보여준다. 다양한 task를 통합하였으며, Input/Output 이미지 수를 다양하게 처리할 수 있다.
Limitation
UniReal은 이론적으로 Input/Output 이미지 수에 제한이 없지만, 5개를 초과하는 이미지를 다룰 경우 안정성이 떨어지고 계산량이 크게 증가한다.
개인적으로 느낀점
최근 읽어본 논문 중에 가장 재미있었다.
기존 이미지 Editing method와 달리 “프레임 간 자연스러운 변환” 이라는 비디오의 특성을 사용하여 train 데이터로 사용한 점이 재미있었으며, 이를 통해 인공지능 모델이 실제 세계의 역학을 이해하였다는 것이 매우 인상깊은 부분이었다.
전에 VLM의 domain generalization 성능 향상을 위해 합성 Dataset을 생성하는 연구를 진행한 적이 있었는데, Reference 객체를 다양한 상황과 camera view에서 보게 하는 task가 필요했지만 성공하지 못하여 아쉬움이 많이 남았다. 이 때문인지, UniReal이 수행하는 다양한 task와 Image Editing에서 발생하는 detail한 task 분류의 모호성을 해결한 점이 재밌었다.