[개념 정리] VAE
VAE
강의영상 : https://youtu.be/rNh2CrTFpm4
매니폴드 상에서 latend variable인 z. p(z)는 random variable이며 보통 uniform distribution또는 normal distribution을 사용
Generator의 확률 모델을 Gaussian으로 할 경우, MSE 관점에서 가장 가까운 것이 구해야 하는 p(x)에 기여하는 바가 더 크다. MSE가 더 작은 이미지가 의미적으로 더 가까운 경우가 아닌 이미지들이 많기 때문에 올바른 확률값을 구하기 어렵다.
Uniform Sampling으로 학습을 그냥 시킬 경우, MSE가 작은 잘못된 결과에 대한 확률이 도출됨.
- z를 정규분포에서 샘플링하는 것보다 x와 유사한 샘플이 나올수 있는 이상적인 확률분포 함수 p(z|x)로부터 샘플링 하면 됨.
하지만, p(z|x)가 무엇인지 알지 못하므로, 우리가 알고있는 확률 분포 중 하나(q𝛗(z|x))를 택해서 이의 파라미터를 조정(𝛗)하여 p(z|x)와 유사하게 만들어 사용한다.
-> (Variational Inference, 변분 추론 방식)

- KL Divergence : 두 확률분포 간의 차이(거리) 이며, 여기서는 p(z|x)를 모르기 때문에, KL을 최소화하는 대신, ELBO를 최대화하는 𝛗를 찾는다.
- ㏒(𝑝(𝑥)) = ELBO(𝛗) + KL(𝑞𝛗(𝑧|𝑥) | 𝑝(𝑧|𝑥)) 이며, 𝑞𝛗(𝑧\|𝑥) = argmax ELBO(𝛗)이다
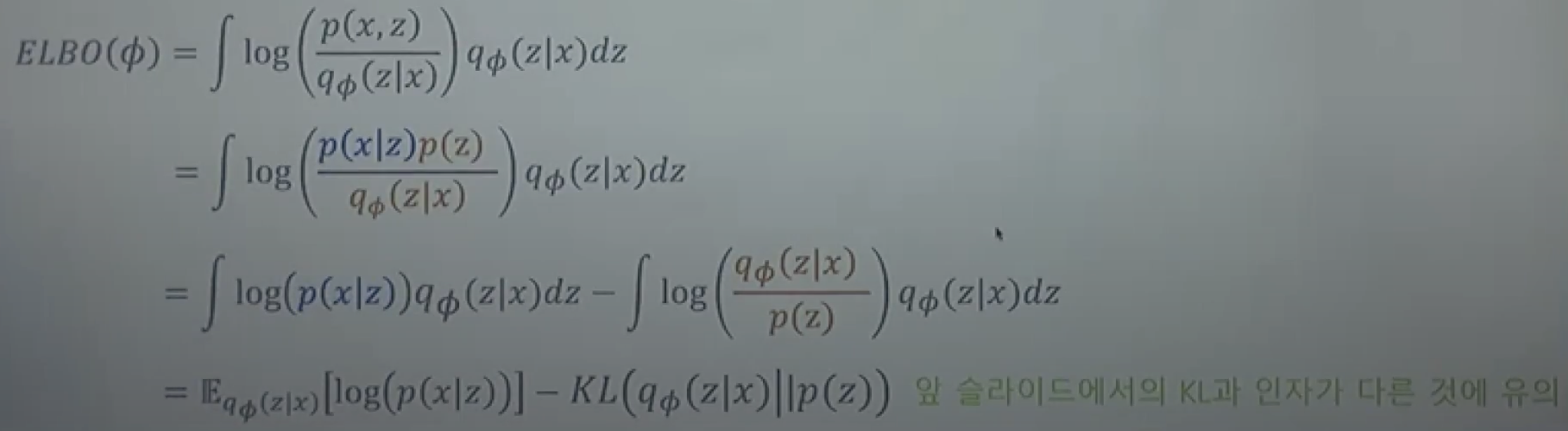
- ELBO를 최대화 하는것이 이상적인 샘플링 함수를 찾는 것. ELBO(𝛗) 식에서 likehood를 최대화 하는 것이 포함되어있음.
즉,

- 2가지 파라미터를 Optimization 해야함.
- 샘플링 함수를 찾기 위해 ELBO를 최대화 해야함. 즉 𝛗를 찾는 것
- likelihood를 최대화 하기 위해 Generator의 𝜃를 찾는 것.
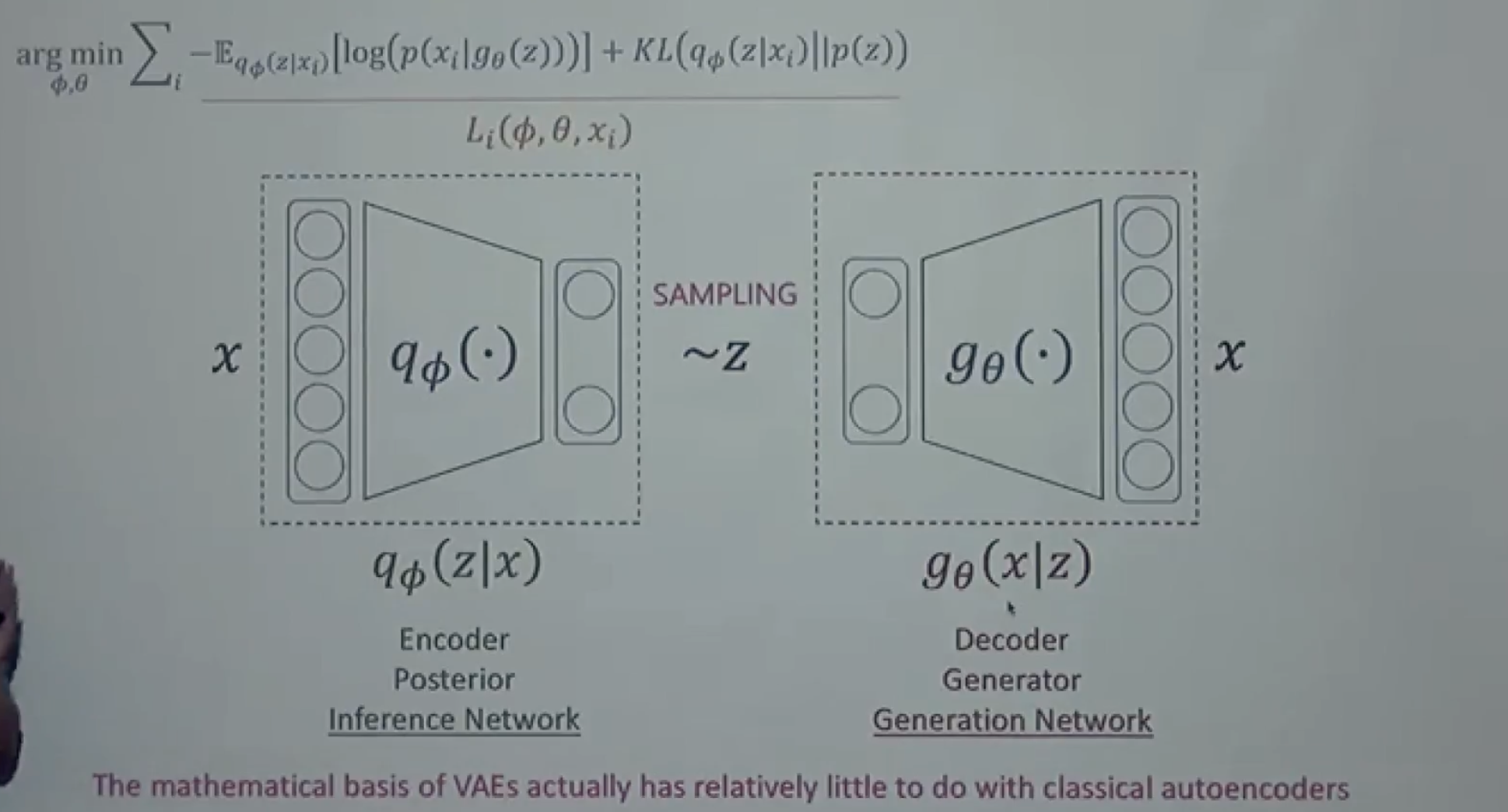

수학적으로는 VAE와 AE는 관계가 없음. (확률적으로 Encoding, Decoding 하다보니 구조가 유사해진 것)
Encoder 부분의 구조는 비슷, Decoder 부분은 Gaussian, Bernoulli분포 등에 따라 다름.
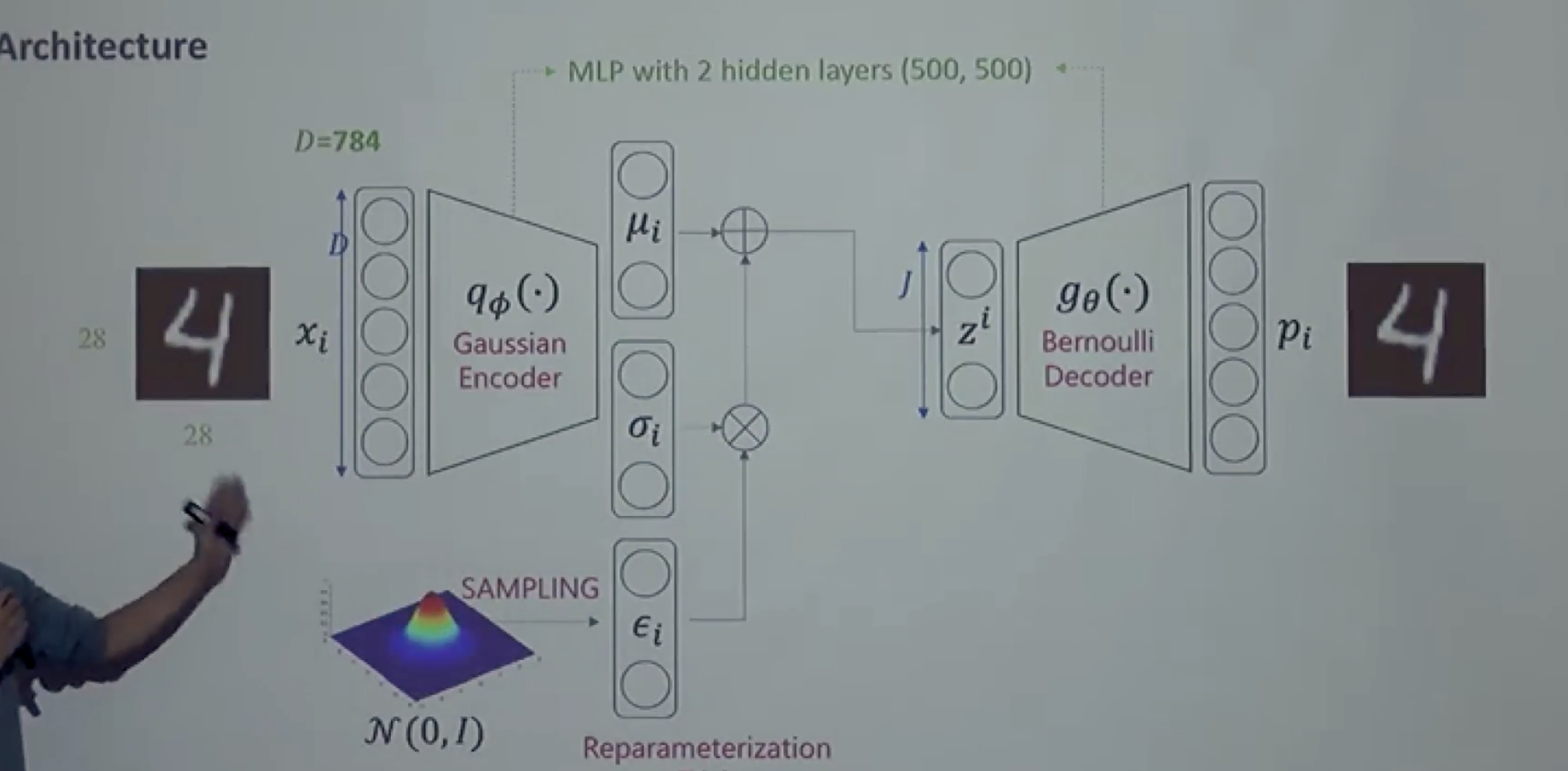
뮤(μ)와 시그마(𝜎)를 추정, 분포에서 샘플링(𝜖)
- CVAE * Conditional Variational AutoEncoder
- CVAE(Conditional Variational AutoEncoder)는 Label 정보를 함께 학습시켜 보다 유용한 정보를 추출하는 방식
- AAE * Adversarial AutoEncoder
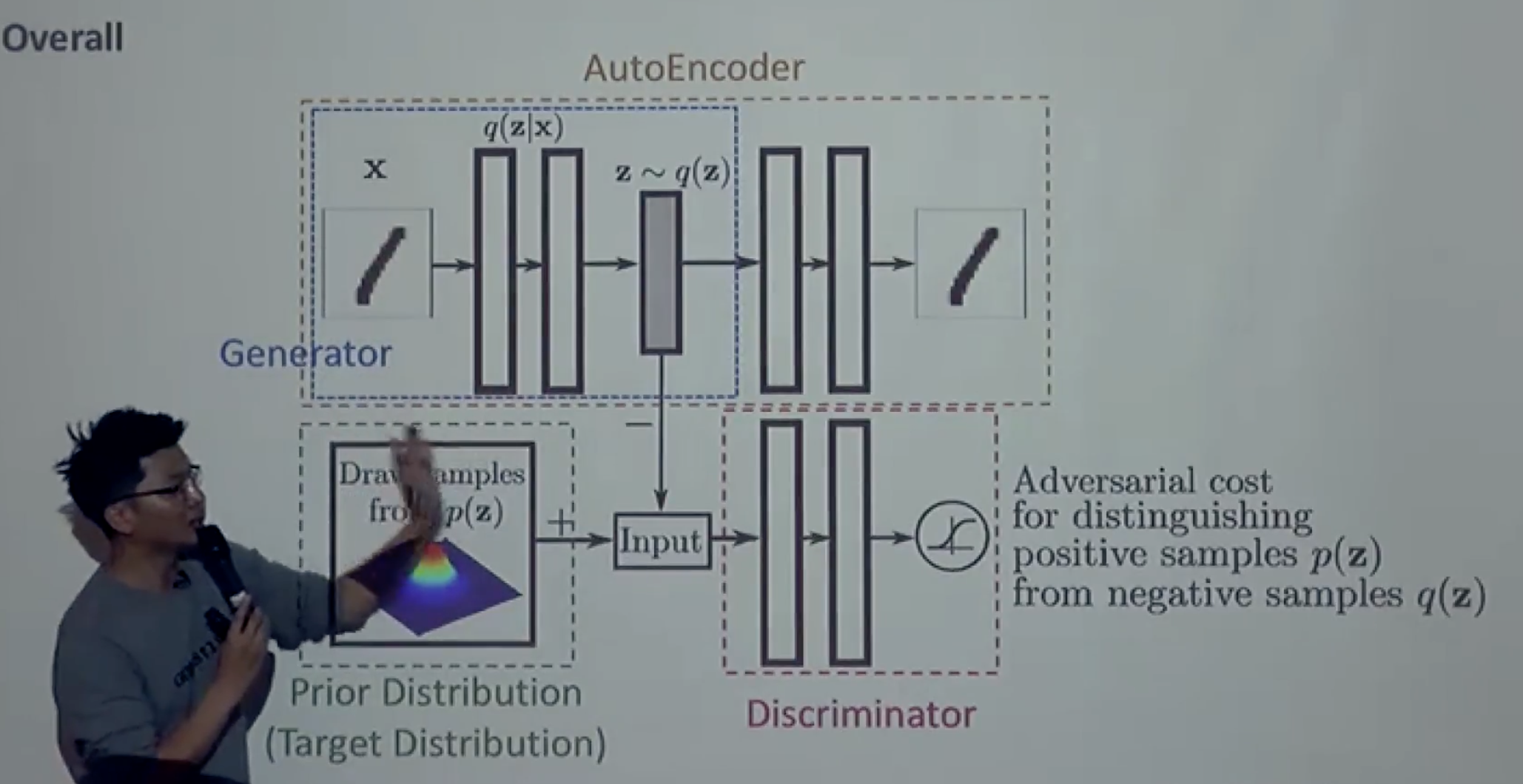
- Encoder를 못바꾸는 VAE는 KL Divergence를 가우시안 말고는 계산이 안됨
- 이를 깨기 위해서, 샘플링을 하되, KL divergence를 사용하지 않는 함수를 쓰자
- KL은 확률분포 2개를 같게 만들어야함 → 𝑞𝛗와 p를 같게 만듬
Prior에서 샘플링한거(Real), AE가 생성한거(Fake) 를 Discriminator를 사용하여 q 함수가 Prior Distribution이랑 같게 만듬 (KL Divergence 대신)
GAN vs VAE
Model VAE GAN Optimization 학습에 용이 (Encoder와 Decoder가 서로 ELOB를 Maximize하기 위해 협력) 경쟁적인 학습이라 어려움 Mode Collapse Image Quality Smooth, Blurry Sharp, Artifact Gerneralization 입력 이미지를 기억하여 생성하는ㅜ 경향이 있음 새로운 이미지를 생성 
- StackGAN
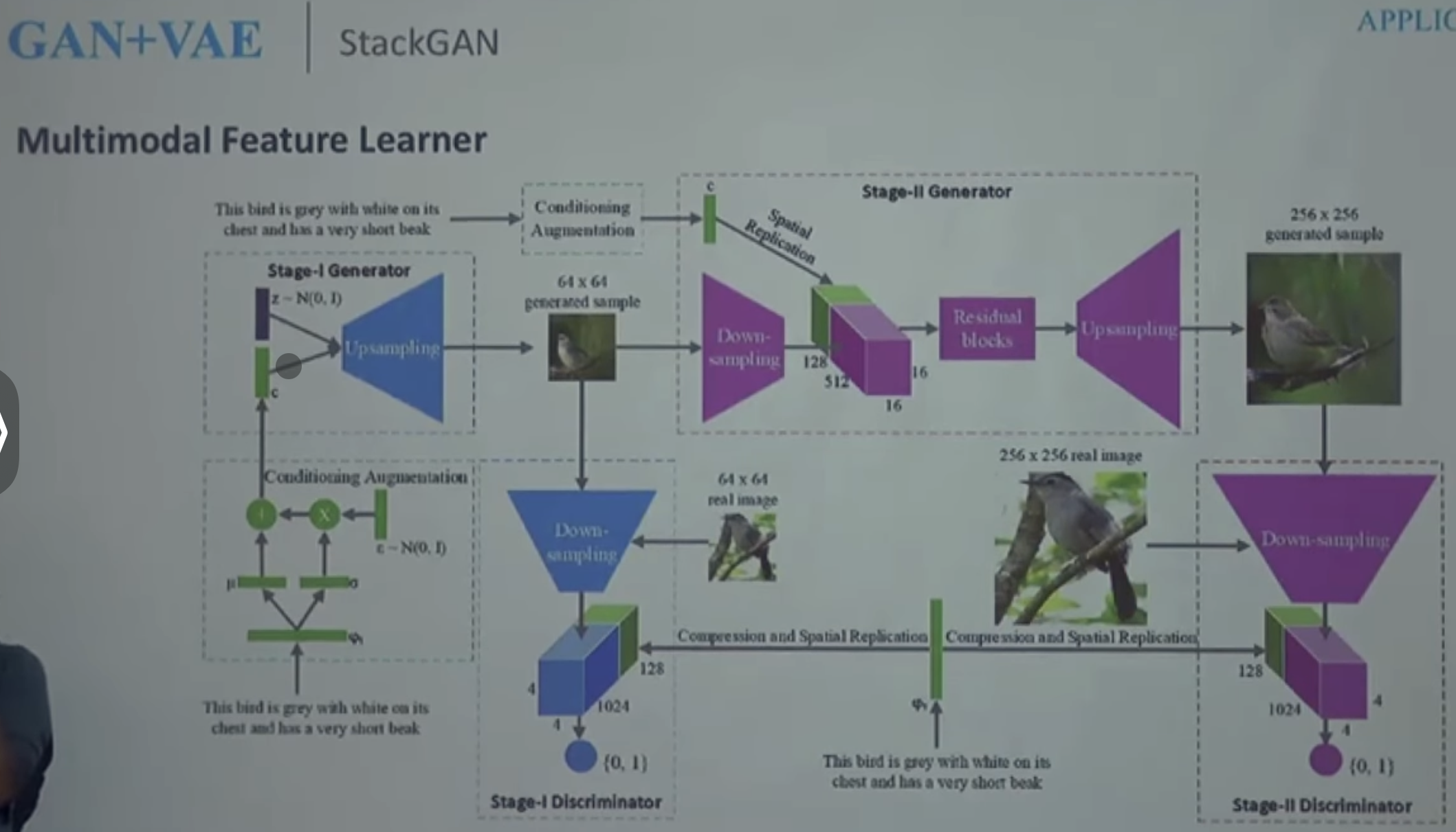
cGAN에서 텍스트에서 Condition을 넣어줄때, Text에서 Encoding 방식을 사용하여 Condition을 추출