[Paper Review] Visual Representation Alignment for MLLMs
[논문 리뷰] Visual Representation Alignment for MLLMs
Visual Representation Alignment for MLLMs
Heeji Yoon, Jaewoo Jung et al
[arXiv] [Github] [Project Page]
Background
MLLMs
MLLM은 텍스트와 이미지 등 여러 모달리티를 함께 처리할 수 있는 대형 언어 모델을 의미한다.
일반적으로 대형 언어 모델(LLM)인 언어 생성 모듈 $LM_{\theta}$와, vision 인코더 $V_{\psi}$로 구성되며, 이 둘 사이에 vision-language projector $P_{\phi}$가 연결된 구조를 가진다.
vision 인코더 $V_{\psi}$는 입력 이미지 $I$에서 patch 단위의 시각 feature을 추출하여 비주얼 token 시퀀스 $z$를 생성한다.
이어서 projector $P_{\phi}$가 이 시각 feature $z$를 LLM이 사용하는 embedding 공간으로 매핑하여 시각 embedding token $e_{\text{img}}$을 생성한다.
한편 텍스트 입력은 LLM의 tokenizer와 embedding layer을 거쳐 텍스트 embedding token $e_{\text{text}}$을 얻는다.
최종적으로 LLM은 visual token과 text token을 연결(concatenate)한 시퀀스 $[e_{\text{img}}; e_{\text{text}}]$을 입력받아, 멀티모달 문맥에 대한 다음 단어 생성 확률을 모델링한다 .
Visual Instruction Tuning
Visual Instruction Tuning은 이미지와 그에 대한 Question-Answering이나 설명 같은 visual instruction 데이터를 활용한 LLM fine-tuning 기법이다.
대표적으로 LLaVA와 같은 모델이 이러한 방법으로 학습
미리 학습된 LLM과 vision 인코더를 작은 projector로 연결한 뒤, 이미지-텍스트 pair의 지시(예: “이 이미지에서 무슨 일이 벌어지고 있나요?”)에 답하도록 supervised learning을 한다.
이때
- 1단계 : LLM을 동결하고 projector만 학습하는 vision-language pre-training
- 2단계 : LLM과 projector를 함께 학습하는 Visual Instruction Tuning
가 일반적이다.
두 단계 모두 언어 모델링 목표를 사용하며, 이미지 입력이 있더라도 텍스트 생성의 log-likelihood 최대화라는 동일한 loss 함수를 최적화한다.
다시 말해, 모델은 주어진 이미지와 텍스트 프롬프트로부터 올바른 응답 문장을 생성하는 데 집중하여 학습된다.
Representation Alignment
하나의 모델 내부 또는 서로 다른 모델 간의 feature representation을 정합하게 맞추는 것을 의미한다.
본 논문에서는 MLLM 내부의 시각 경로 feature representation을 다른 강력한 시각 모델의 representation에 정렬시키는 전략을 취한다.
이를 통해 MLLM이 시각 인코더가 제공하는 풍부한 정보를 잃지 않고 유지하도록 유도한다.
특히 중간 layer의 feature를 외부 teacher 모델의 representation과 가깝게 만들면, 모델이 세밀한 시각 정보를 계속 활용할 수 있게 된다.
이때 정렬 대상이 되는 외부 모델로 vision Foundation 모델(VFM)을 활용하며, 정렬 정도를 측정하거나 최적화할 때는 코사인 유사도 등의 척도를 사용한다.
VIRAL은 이러한 representation 정렬 기법을 MLLM 학습에 도입한 본 논문의 제안 방식
Visual Representation ALignment
VFM (Vision Foundation Model)
대규모 데이터로 학습되어 일반적인 시각 representation을 풍부하게 담고 있는 pre-training vision 모델
예를 들어 DINOv2, SAM, CLIP 등은 각각 다양한 시각적 목표(self-supervised learning, 세그멘테이션, contrastive learning 등)로 훈련되어, 객체의 세부 속성이나 공간적 구조 같은 풍부한 시각 정보를 인코딩
이러한 VFM의 representation은 MLLM의 자체 vision 인코더가 생성하는 feature보다 더 많은 시각 지식을 담고 있을 수 있으며, 따라서 MLLM의 내부 시각 representation을 VFM에 정렬시킴으로써 추가적인 시각적 지식을 주입하는 것이 가능하다.
VFM은 학습 시 동결(frozen)되어 사용되며, MLLM의 내부 representation을 지도(supervise)하는 teacher 역할을 수행한다.
Introduction
MLLM은 이미지와 텍스트를 함께 이해하고 생성하는 능력으로 다양한 작업에서 뛰어난 성능을 보여주고 있다.
그러나 최근 연구들에 따르면 MLLM들은 객체 개수 세기나 공간 관계 이해와 같은 시각 중심 task에서는 아직 한계를 보인다.
본 논문에서는 이러한 한계의 원인을 텍스트 기반의 간접적인 학습 신호에서 찾는다.
현재의 MLLM 훈련은 대부분 텍스트 생성 loss만을 사용하기 때문에, 이미지로부터 얻은 시각적 feature들이 직접적인 감독 없이 언어 모델에 통합된다.
그 결과 모델은 텍스트 예측에 바로 도움이 되는 정보만 남기고 나머지 세밀한 시각 단서는 훈련 중 버리는 경향이 있다고 가설을 세웠다.
예를 들어, 캡션 데이터에 “큰 깃발을 들고 있는 사람들의 사진“이라는 문장만 있다면,
모델은 사람 수나 깃발 색상 등의 정보를 굳이 유지하지 않아도 답을 맞출 수 있으므로 해당 시각 정보를 잃어버릴 수 있다는 것
이 문제를 해결하기 위해, 저자들은 VIsual Representation ALignment (VIRAL)이라는 간단하지만 효과적인 정규화 전략을 제안한다.
VIRAL은 MLLM의 내부 시각 representation을 강력한 pre-training vision 모델(VFM)의 representation에 직접 정렬시킴으로써, 모델이 시각 인코더로부터 받은 세밀한 시각 속성을 버리지 않도록 만든다.
코사인 유사도 기반의 정렬 loss을 도입하여, MLLM 중간 layer의 visual token이 VFM의 feature와 최대한 유사해지도록 학습한다.
이를 통해 모델은 입력 이미지의 중요한 시각적 세부사항을 유지할 뿐 아니라, VFM으로부터 추가적인 시각 지식을 보충받아 복잡한 시각 추론 능력을 향상시킬 수 있게 된다.
실제로 VIRAL을 LLaVA-1.5 등 기존 기법에 적용한 결과, 다양한 멀티모달 benchmark task 전반에서 일관된 성능 향상을 달성하였고, 세분화 실험을 통해 본 접근법의 핵심 설계 요소들을 검증하였다.
저자들은 VIRAL의 발견이 MLLM 훈련 시 시각 정보 통합을 개선하는 새로운 방향을 열어줄 것으로 기대하고 있다.
Goal
텍스트 위주로 학습되는 기존 멀티모달 LLM에서 시각 경로의 정보 loss 문제를 규명하고, 내부 시각 representation을 정렬시키는 새로운 기법을 통해 세밀한 시각 정보 보존 및 활용 능력을 향상시키는 것이다.
Motivation
텍스트만으로 감독되는 MLLM은 시각적 세부 정보가 훈련 중 소실되는 한계를 보인다.
이러한 현상을 해결하기 위해, 외부 강력한 시각 모델의 representation을 활용하여 MLLM 내부 representation을 보강하면 모델이 더 풍부한 시각 지식을 유지할 수 있을 것이라는 직관에서 연구가 시작되었다.
Contributions
- 시각 정보 loss 현상 규명
- 시각 지시 학습 과정에서 MLLM 내부의 시각 representation이 입력 vision 인코더의 풍부한 feature과 정렬을 잃고, 그에 따라 세밀한 시각 정보가 열화됨을 보였다 (문제 진단).
- 새로운 정규화 전략 제안
- VFM로부터 얻은 유용한 시각 representation에 MLLM의 시각 representation을 명시적으로 정렬시키는 정규화 기법 VIRAL을 제안
- 세밀한 시각 속성 loss을 방지하고 더 풍부한 멀티모달 이해를 가능하게 한다
- 광범위한 실험 검증
- 표준 멀티모달 benchmark에서 VIRAL의 일관된 성능 향상을 실증
- 다양한 제거 연구를 통해 제안 기법의 설계 선택들이 유효함을 검증
Related Works
MLLM 내부 정보 흐름 분석
최근 여러 연구들은 멀티모달 LLM의 layer별 정보 처리 구조를 밝혀내고 있다.
- MLLM의 초기 layer은 주로 전반적인 시각 문맥을 통합하고, 중간 layer에서 세밀하고 공간적인 feature이 포착되며, 후반 layer에서는 이러한 시각 정보와 텍스트 정보가 결합되어 최종 응답 생성에 활용되는 layer적 처리 구조가 나타난다.
- 특히 중간 layer의 representation이 시각적 이해에 중요하다는 보고가 있다.
- 중간 layer을 정보 강화 단계와 정제 단계로 구분하며, 초반 단계에서 충분한 시각 정보가 공급되지 않으면 이후 객체 환각(object hallucination) 현상이 발생함을 보였다.
- 중간 layer의 일부 attention 헤드만이 시각적 그라운딩에 핵심적임을 확인하였다.
이러한 결과들과 일치하게, 본 논문의 시각 representation 정렬 분석 실험에서도 중간 layer에서 시각 정보가 얼마나 보존되는지가 공간 추론 능력과 강한 상관을 보임을 확인했다.
이는 vision 중심 task에서 중간 layer의 시각 정보 유지가 중요함을 시사한다.
MLLM의 시각 정보 개선
MLLM 내부 정보 흐름에 대한 관심이 높아지고 있으나, 대부분의 선행 연구들은 입력 단계에 집중되어 있다.
예를 들어,
- 더 강력한 vision 인코더를 도입
- visual token 수를 줄여 효율성을 높이는
등의 개선이 많이 시도되었다.
이러한 접근들은 초기 시각 representation의 품질과 효율성을 높이는 데에는 효과적이지만, 투입된 시각 정보가 모델 내부에서 어떻게 처리되고 유지되는지에 대한 대책은 부족했다.
최근 일부 연구는 visual token에 대한 직접적인 감독을 도입하기도 했으나, 이 또한 최종 출력 단계에서의 감독에 치중되어 내부 과정 개선으로는 충분하지 않았다.
특히 재구성 기반 목표를 사용한 경우 낮은 수준의 화질 유지에는 도움이 되지만, 고차원의 의미적 추론에는 한계가 있음이 지적되었다 .
이러한 맥락에서 본 논문의 접근법은 기존 방향을 보완한다.
중간 layer의 내부 시각 representation에 초점을 맞추어, 그 중에서도 세밀한 의미가 나타나기 시작하는 중간 layer의 feature을 pre-training VFM의 embedding에 정렬시킨다.
이를 통해 구조화된 감독 신호를 제공함으로써, 모델 전반에 걸쳐 의미적으로 중요한 시각 콘텐츠가 유지되도록 한다.
다시 말해, 단순히 입력 표상을 개선하는 것을 넘어 모델 내부의 시각 정보 처리 과정 자체를 개선하는 새로운 방향을 제시한다.
Preliminaries
먼저 멀티모달 LLM의 형식을 수식으로 정의하겠다. MLLM 구성요소는 크게 세 부분으로 나뉜다:
- $LM_{\theta}$: pre-training된 언어 모델(LLM)
- $V_{\psi}$: pre-training된 vision 인코더, frozen
- $P_{\phi}$: vision 인코더와 LLM을 이어주는 projector
MLLMs
이미지 $I \in \mathbb{R}^{H\times W \times 3}$ (높이 $H$, 너비 $W$)가 주어지면, vision 인코더 $V_{\psi}$가 이를 처리하여 $N$개의 비주얼 token으로 이루어진 feature map $z = V_{\psi}(I) \in \mathbb{R}^{N \times D_z}$를 추출한다.
여기서 $N$은 visual token의 개수, $D_z$는 vision 인코더 출력 feature의 차원이다.
이어서 projector $P_{\phi}$는 $z$를 LLM의 embedding 차원 $D$으로 매핑하여 시각 embedding token 시퀀스 $e_{\text{img}} = P_{\phi}(z) \in \mathbb{R}^{N \times D}$를 생성한다.
한편 텍스트 입력(예: 질문이나 프롬프트)은 LLM의 tokenizer와 embedding layer을 통해 텍스트 embedding token 시퀀스 $e_{\text{text}} \in \mathbb{R}^{K \times D}$로 변환된다.
$K$는 text token의 개수
마지막으로 언어 모델 $LM_{\theta}$는 visual token과 text token을 연결한 $[e^{\text{img}}; e^{\text{text}}] \in \mathbb{R}^{(N+K) \times D}$를 입력으로 받아, text token 시퀀스의 확률 분포 $p_{\theta,\phi}(e^\text{text}_{1:K} \mid e^{\text{img}})$를 모델링한다.
이 분포는 chain rule에 따라 인덱스 $i=1$부터 $K$까지의 각 token에 대해 다음과 같이 인과적 곱으로 나타난다:
\[p_{\theta,\phi}(e^\text{text}_{1:K} \mid e^{\text{img}}) = \prod_{i=1}^{K} p_{\theta,\phi}\Big(e^\text{text}_i \Big| e^\text{text}_{<i}, e^{\text{img}}\Big) \tag{1}\]- $e_{\text{text}_{1:K}}$: 텍스트 전체 token 시퀀스
- $e_{\text{img}}$: 시각 embedding token 시퀀스 (이미지로부터 생성)
- $e_{\text{text}_{<i}}$: $i$번째 이전까지의 text token
- $p_{\theta,\phi}( \cdot | \cdot)$: LLM $LM_{\theta}$와 projector $P_{\phi}$로 정의되는 조건부 확률 분포
Training stages of MLLMs.
MLLM 훈련은 보통 두 단계로 진행된다.
- vision-언어 pre-training 단계에서는 LLM($\theta$)은 frozen하고 projector($\phi$)만을 최적화하면서, 이미지-텍스트 pair에 대한 언어 생성(예: 캡션 생성)으로 학습
- 시각 지시 튜닝 단계에서는 LLM($\theta$)과 projector($\phi$)를 공동으로 fine-tuning
- 이때 시각적 질문-응답과 같은 지시 데이터로 학습
두 단계 모두 동일한 **언어 모델링 목표를 공유하는데, 이는 **텍스트 출력 시퀀스의 likelihood(log-likelihood)를 최대화하는 것이다.
구체적으로, 언어 모델링 loss $L_{\mathrm{LM}}$은 다음과 같이 정의된다:
\[L_{\mathrm{LM}} = -\frac{1}{K} \sum_{i=1}^{K} \log, p_{\theta,\phi}\Big(e^\text{text}_{i} \Big| e^{\text{text}}_{<i}, e^{\text{img}}\Big) \tag{2}\]- $K$: text token의 길이 (타겟 단어 수)
- $p_{\theta,\phi}(e^{\text{text}}_i \mid e^\text{text}_{<i}, e^{\text{img}})$: $i$번째 text token의 출력 확률 (언어모델 분포)
- $L_{\mathrm{LM}}$: 언어 모델링 loss, 텍스트 출력의 로그-확률의 음수 평균값
이 언어 중심의 loss 함수만으로 모델을 학습하면, visual token $e_{\text{img}}$ 자체에는 경로-특화된 오류역전파 신호(pathway-specific supervision)가 거의 주어지지 않는다.
다시 말해, 모델의 학습 신호가 전부 텍스트 생성 목표를 통해서만 전달되기 때문에, 시각 경로의 내부 representation이 직접적인 감독 없이 언어 경로에 종속되는 구조이다.
이러한 기존 학습 체제의 문제점을 다음 절에서 구체적으로 진단한다.
Methology
4.1 Do MLLMs undergo visual information loss?
MLLM은 입력으로 상당히 많은 수의 visual token을 받지만, 앞서 언급한 바와 같이 텍스트 출력에 대한 loss만으로 학습된다.
그 결과, 모든 학습 신호가 언어 감독을 매개로 전달되고 시각 representation $e_{\text{img}}$ 자체에는 명시적인 시각적 피드백이 주어지지 않는다.
저자들은 이러한 상황에서 모델이 텍스트 예측에 즉각 필요하지 않은 시각 feature은 과감히 버리고, 텍스트 예측에 도움이 되는 일부 feature만 남기도록 학습될 것이라고 가정하였다.
이는 장기적으로 내부 시각 representation이 초기 vision 인코더의 풍부한 representation과 점차 멀어지게 되어, 복잡한 시각 추론이나 정확한 시각적 근거 제공에 방해가 될 수 있다.
이러한 시각 정보 loss 가설을 검증하기 위해, 저자들은 LLaVA 모델을 대상으로 내부 시각 representation과 원본 vision 인코더 feature 간의 유사도를 layer별로 측정했다.
구체적으로, CLIP 인코더로부터 얻은 입력 feature $z$와, MLLM의 각 layer $\ell$에서의 시각 representation $e^{\text{img}}_{\ell}$ 사이의 대표성 유사도를 평가했다.
유사도 평가지표로는 CKNNA(Centered Kernel Alignment Nearest-Neighbor) 방법 을 활용하여, layer별로 CLIP feature에 얼마나 정렬되어 있는지를 수치화했다.
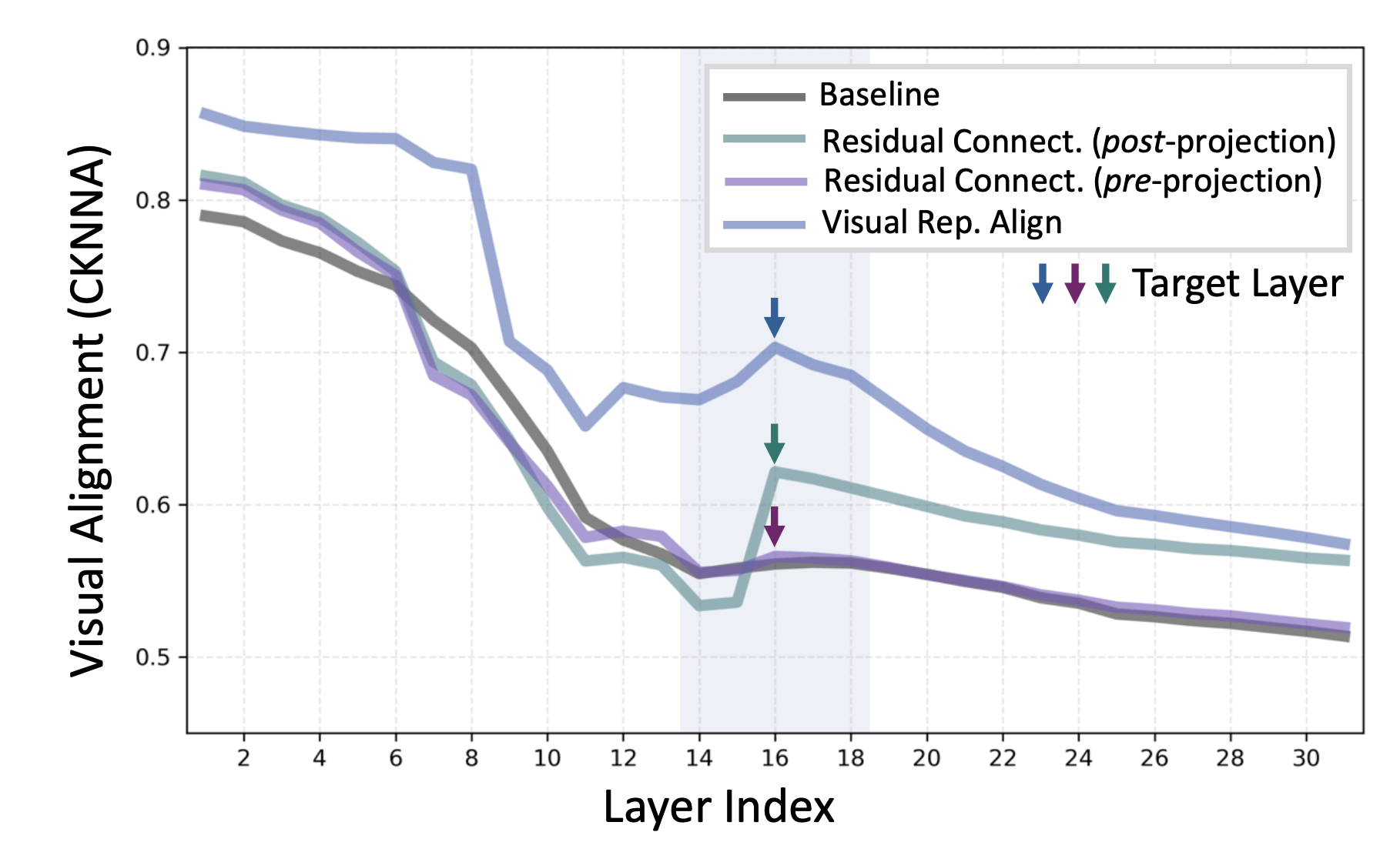
그 결과, 초기 layer 이후로 유사도가 급격히 하락하여 후반부 깊은 layer으로 갈수록 시각 representation이 원본 인코더와 크게 괴리되는 현상이 확인되었다.
이는 명시적 시각 감독이 부재한 상황에서 모델이 인코더의 풍부한 시각 정보를 유지할 동기가 거의 없음을 시사
흥미롭게도, 전체적인 하락 추세 속에서도 중간 layer에서 일시적으로 유사도가 다소 상승하는 패턴이 관찰되었다.
이는 모델이 중간 layer에서 일부 시각 representation을 유지하는 것이 시각적 답변 생성에 유리함을 암묵적으로 활용하고 있을 가능성을 보여준다.
이러한 관찰은 앞서 관련 연구에서 지적된 중간 layer의 중요성과도 맥락을 같이 한다.
저자들은 추가로 layer별 representation 정렬도가 공간 추론 성능과 밀접한 관련이 있음을 layer 삭제 실험 등을 통해 확인하였으며, 중간 layer의 시각 정보 보존이 vision-센트릭 작업 성능 향상에 특히 중요함을 강조한다 .
4.2 Is preserving visual information beneficial?
시각 representation이 훈련 중 손실되는 현상을 확인한 다음, 그렇다면 이를 인위적으로 보존하면 성능이 개선되는지 탐구한다.
Residual connection with post-projection features
특히 중간 layer에서의 시각 정보 유지가 중요해 보이므로, 저자들은 시각 feature을 중간 layer에 다시 주입하는 간단한 방식을 시도했다.
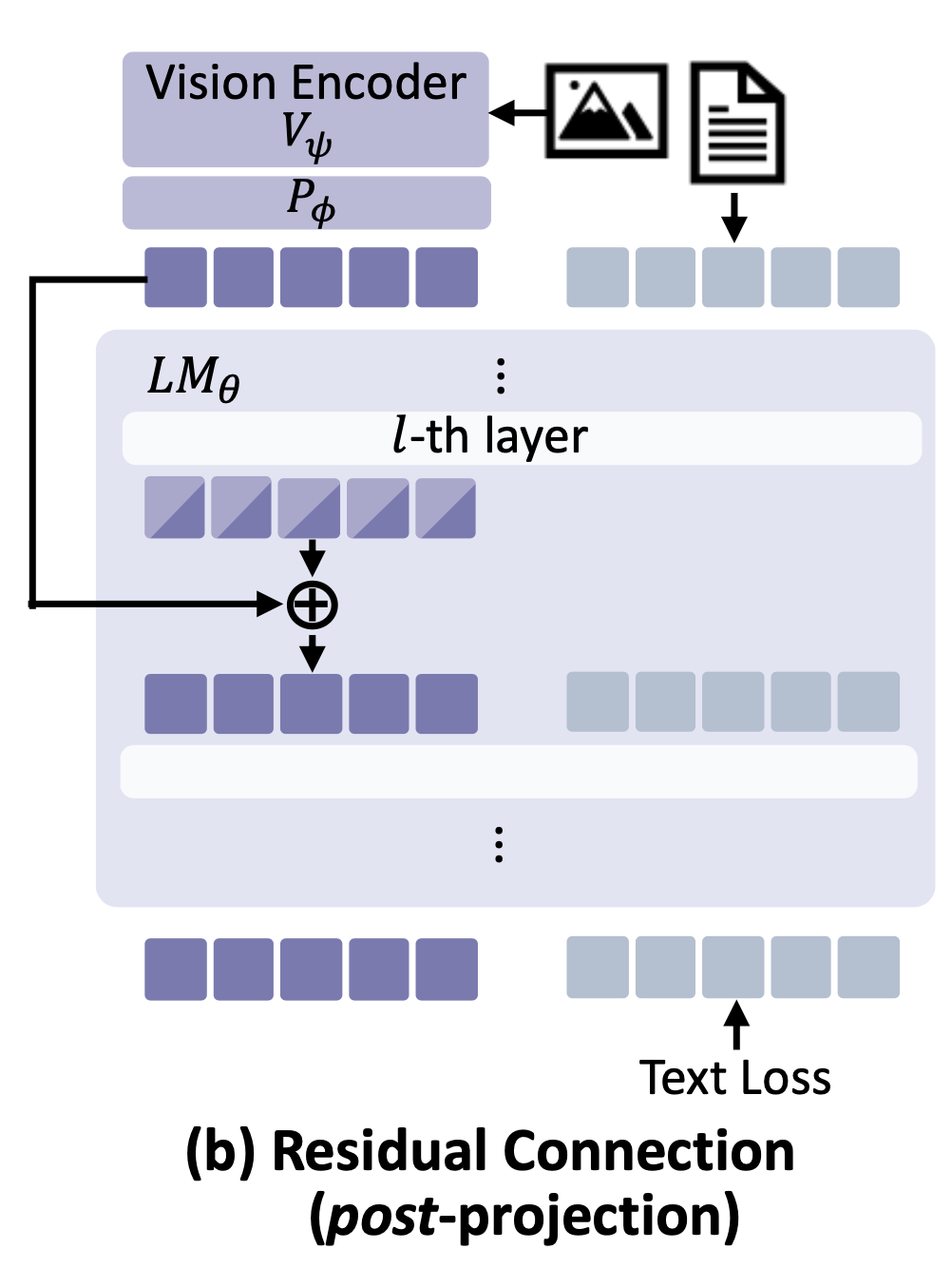
구체적으로, projector 출력 $P_{\phi}(z)$ (즉 초기 입력 visual token $e_{\text{img}}^{(0)}$와 동등한 representation)를 MLLM의 $\ell$번째 중간 layer 출력 $e^{\text{img}}_{\ell}$에 residual connection으로 더해주었다. 이를 수식으로 나타내면 다음과 같다:
\[e_{\text{img}}^{(\ell)} \leftarrow e_{\text{img}}^{(\ell)} + P_{\phi}(z),. \tag{3}\]- $e^{\text{img}}_{\ell}$: MLLM의 $\ell$번째 layer에서의 시각 representation
- $P_{\phi}(z)$: projector를 통과한 입력 시각 feature (초기 visual token)
- $\ell$: residual connection을 적용하는 중간 layer 인덱스 (기본값 16 layer 사용)
이 방법은 MLLM의 학습 알고리즘을 바꾸지 않고, 텍스트 loss $L_{\mathrm{LM}}$만으로 동일하게 훈련하면서 단지 중간에 시각 정보를 보강하는 형태이다.
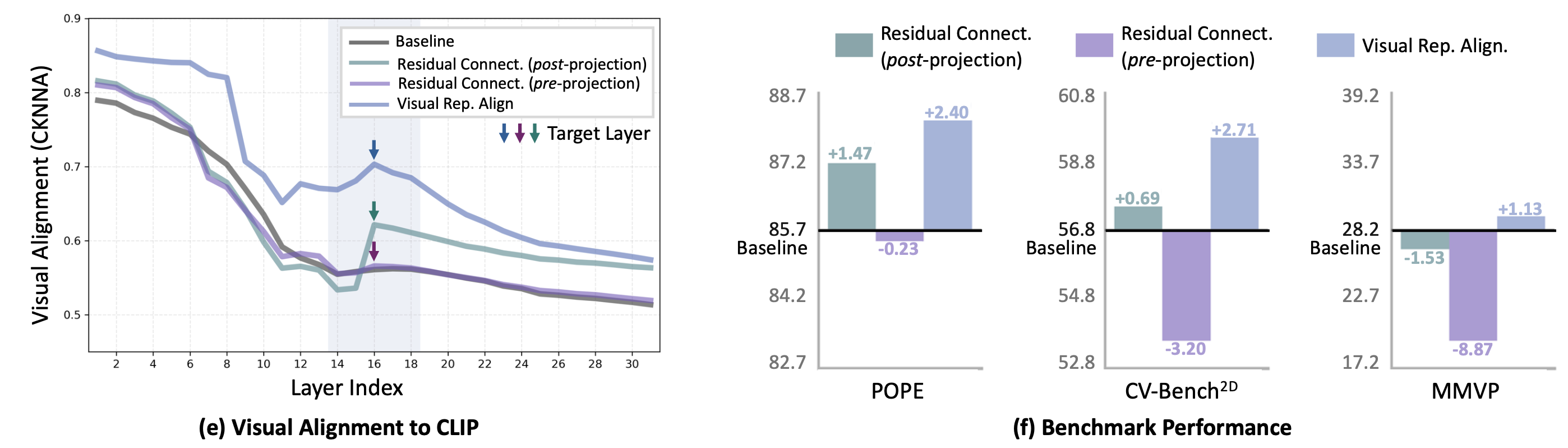
이 post-projection feature residual connection 실험 결과, 시각 representation 정렬도가 유지되어 높은 CKNNA 유사도를 보였고 (위 그래프 초록 곡선) , 다중모달 benchmark 성능도 전반적으로 향상되는 것이 확인되었다.
즉, 인코더에 정렬된 시각 정보를 유지하면 downstream task에 이익이 있다는 가설을 뒷받침한 것이다.
다만 저자들은 이 방법으로도 여전히 제한점이 남음을 지적한다.
예를 들어, projector $P_{\phi}$ 자체가 인코더의 모든 정보를 전달하지 못할 수 있으며 , 단순 residual connection만으로는 시각 representation을 최적으로 활용하지 못할 가능성이 제기되었다.
Residual connection with pre-projection features
저자들은 projector를 통과하기 전의 원본 인코더 feature $z$를 직접 중간 layer에 주입하는 방안도 실험했다. 이 경우 차원 차이를 해결하기 위해 경량 어댑터 $A_{\phi’}$를 사용하였다.
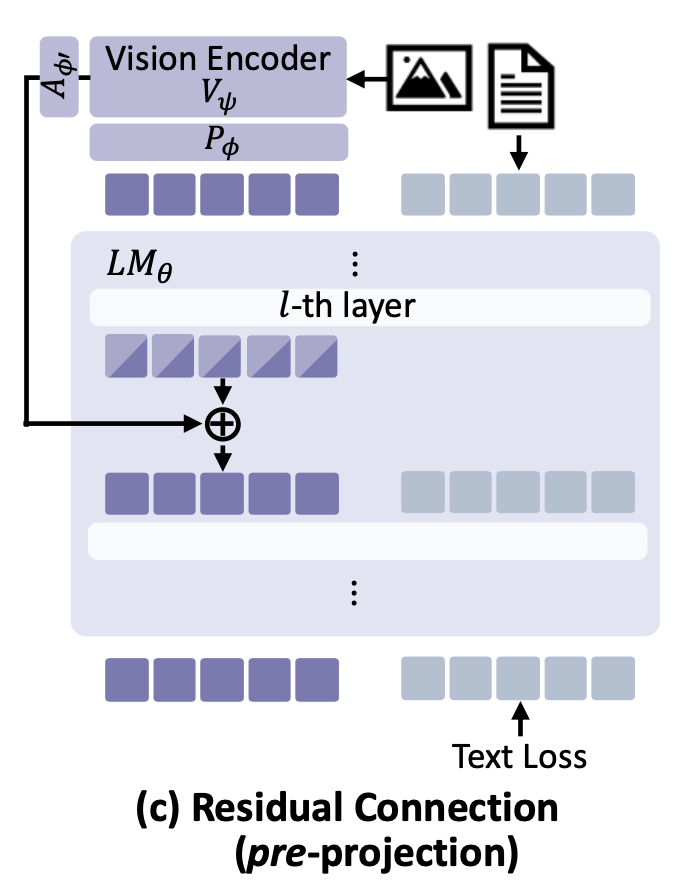
수식으로 표현하면 다음과 같다:
\[e^{\text{img}}_{\ell} \leftarrow e^{\text{img}}_{\ell} + A_{\phi’}(z),. \tag{4}\]그러나 이 접근은 오히려 성능이 하락하여 기준선보다 나쁜 결과를 보였다.
그 이유는 projector를 거치지 않은 원본 인코더 feature은 언어 공간에 정렬되지 않은 상태이기 때문에, 이를 중간 layer에 섣불리 섞어버리면 내부 representation 교란이 발생했기 때문으로 분석된다.
다시 말해, 언어 feature과 충분히 호환되지 않은 외부 feature을 주입하면 오히려 멀티모달 representation의 일관성이 깨져 성능이 악화된다는 것이다.
요약하면, 단순 residual connection로 시각 정보 보존의 이점은 확인되었으나, 보다 구조적인 해결책이 요구된다는 결론에 이르렀다.
4.3 Visual Representation Alignment for MLLMs (VIRAL)
위 결과를 바탕으로, 저자들은 보다 원칙적인 접근법으로 시각 representation을 정렬시키는 방법을 제안한다.
핵심 아이디어는 Residual 연결 대신, 아예 MLLM의 중간 시각 representation이 특정 목표 시각 representation과 일치하도록 명시적인 loss 함수를 주는 것이다.
이를 Visual Representation Alignment (VRA) loss이라고 부르며, 먼저 정렬 대상으로는 기존 인코더의 자체 feature $z$를 사용해보았다.
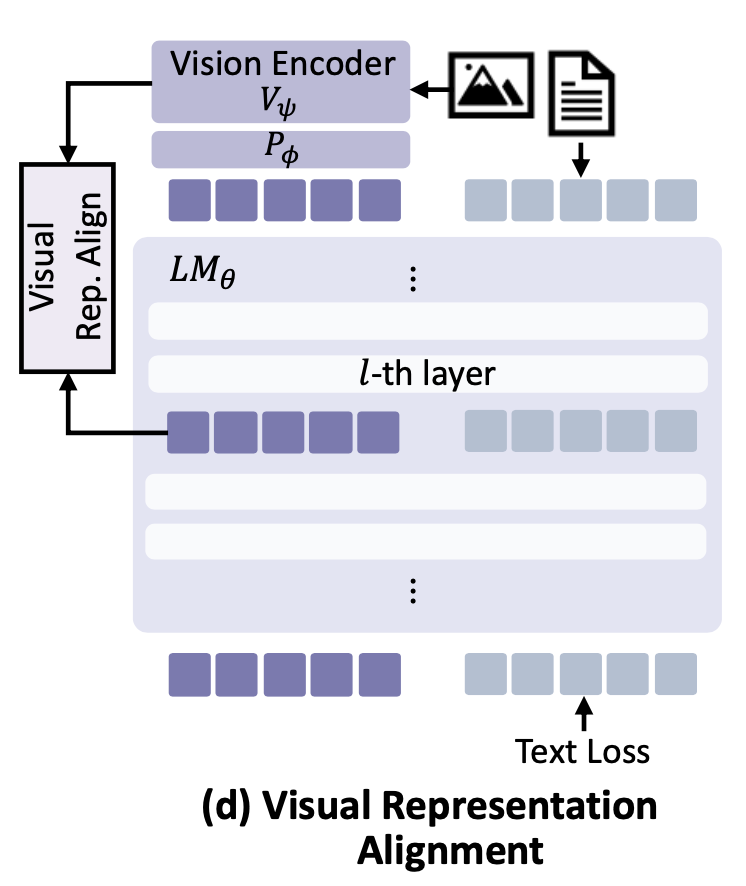
이 방법에서, $\ell$ 번째 layer의 MLLM 시각 representation $e^{\text{img}}_{\ell}$와 동결된 인코더 feature $z$를 정렬시키기 위해, $e^{\text{img}}_{\ell}$를 인코더 공간으로 사영하는 별도의 프로젝션 $P_{\pi}$를 도입한다. 그리고 다음과 같은 정렬 loss 함수 $L_{\mathrm{VRA}}$를 정의한다:
\[L_{\mathrm{VRA}} = -\frac{1}{N} \sum_{i=1}^{N} \mathrm{sim}\Big(P_{\pi}(e^{\text{img}}_{\ell, i}), z_i\Big) \tag{5}\]- $N$: visual token의 개수
- $e^{\text{img}}_{\ell, i}$: $\ell$층에서의 $i$번째 visual token representation
- $P_{\pi}$: $;e^{\text{img}}_{\ell}$를 인코더 feature 공간(차원 $D_z$)으로 투영하는 학습가능 프로젝션
- $z_i$: 동결된 vision 인코더 $V_{\psi}$로부터 얻은 $i$번째 patch feature (정렬의 타겟)
- $\mathrm{sim}( \cdot,\cdot )$: 두 벡터 간 코사인 유사도 함수 (역전파 시 $z$에는 gradient를 흘리지 않음)
이 loss $L_{\mathrm{VRA}}$는 MLLM의 내부 시각 representation이 인코더의 원본 feature과 최대한 유사하도록 학습을 유도한다.
최종 훈련 목표 함수는 기존의 언어 모델링 loss에 정렬 loss을 가중합하여 사용한다:
\[L_{\text{total}} = L_{\mathrm{LM}} + \lambda L_{\mathrm{VRA}} \tag{6}\]- $\lambda$: 정렬 loss의 기여 정도를 조절하는 가중치 hyperparameter
이처럼 텍스트 loss + 정렬 loss로 모델을 공동 최적화하면, MLLM은 텍스트 생성 성능을 유지하면서도 내부 시각 경로에 별도의 감독을 받게 된다.
residual connection과 달리, 정렬 loss은 representation 공간 자체를 구조적으로 제약하기 때문에, 세밀한 시각 정보의 보존에 보다 효과적일 것으로 기대된다.
실제 실험에서, 이 representation 정렬 방식은 residual connection보다도 우수한 성능 개선을 보였다.
그래프에서 확인할 수 있듯이, 정렬 loss을 사용한 모델이 layer별 시각 representation 유사도와 benchmark accuracy에서 모두 Residual 방법보다 향상되었음을 알 수 있다.
이는 중간 feature을 직접 제약하여 미세한 시각 정보까지 보존하는 것이, 단순히 feature을 전달하는 것보다 언어 모델이 시각 정보를 통합하기 쉽게 만들어준다는 통찰을 제공한다.
한편, 정렬 loss을 도입한 모델에서도 일부 한계가 관찰되었다.
대부분의 benchmark에서 향상되었지만, MMVP (이미지-비디오 대조학습 기반 평가)에서는 약간의 성능 저하가 나타난 것이다.
저자들은 이 현상이 CLIP과 같은 인코더 feature이 갖는 편향이 함께 전달되었기 때문으로 추측한다.
즉, 원본 인코더 $z$에 계속 정렬하도록 강제하면 해당 인코더의 representation 한계까지 모델에 이식되므로, 정렬 대상을 더 정보풍부한 것으로 바꾸면 어떨까? 하는 후속 의문이 제기되었다.
사실 원본 인코더 $V_{\psi}$의 representation력은 한정되어 있으며, CLIP 등 대조학습 인코더는 특정 상황(예: MMVP task)에서 부적절할 수 있다.
따라서 정렬 대상을 보다 강력한 시각 representation으로 교체하여 MLLM이 더 풍부한 시각 정보를 유지하도록 유도하는 방향이 자연스럽게 떠오른다.
From encoder features to other VFMs
위 논의를 바탕으로 최종적으로 제안되는 방법이 VIRAL이다.
VIRAL은 기존 인코더 feature $z$ 대신, VFM $E(\cdot)$의 feature $y$를 정렬 목표로 사용하는 것을 핵심으로 한다.
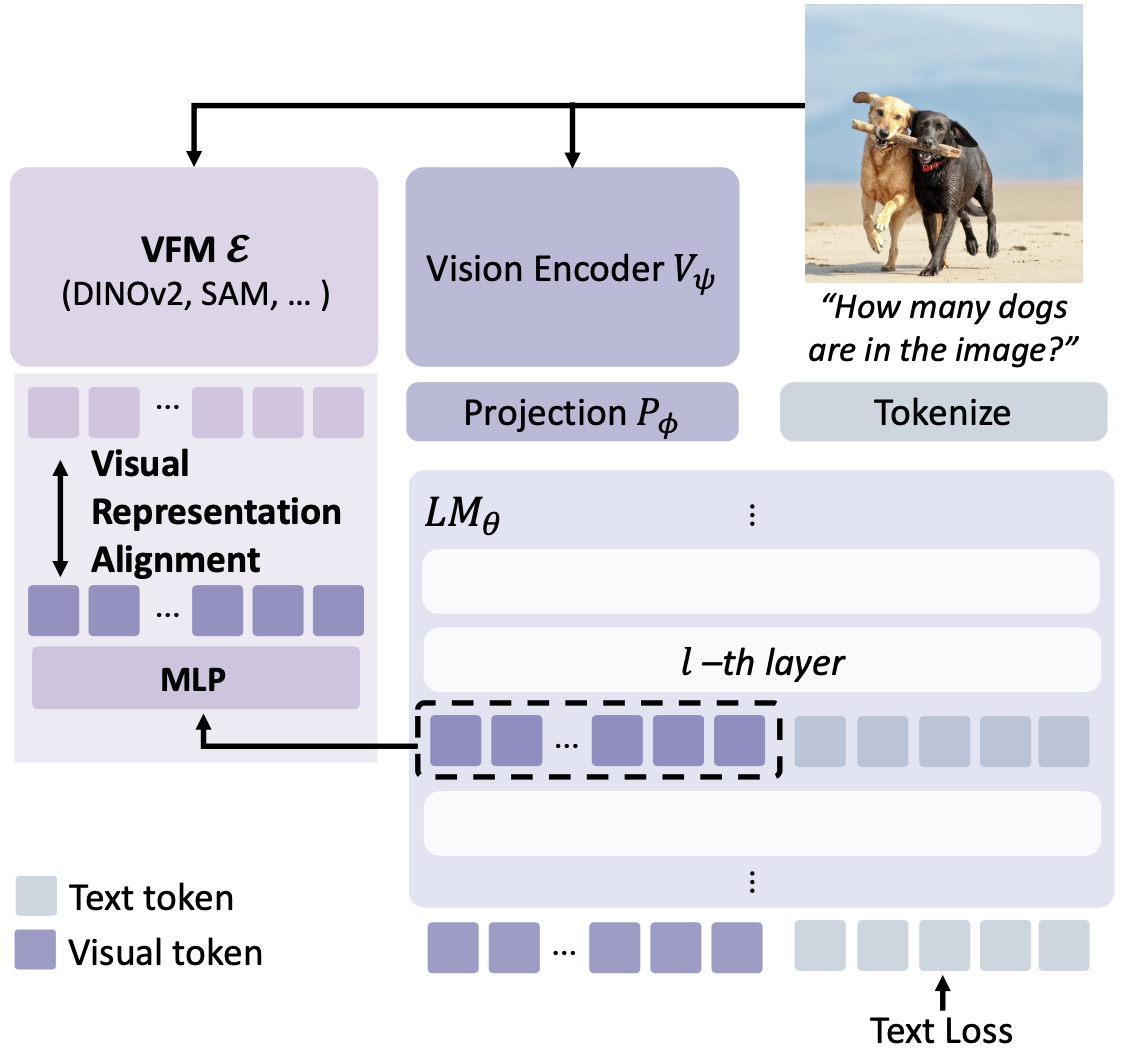
위은 VIRAL의 개념을 보여주며, MLLM의 중간 시각 representation을 VFM의 풍부한 representation에 맞춤으로써 MLLM의 시각 이해 능력을 향상시키는 프레임워크를 묘사한다.
왼쪽에는 강력한 VFM으로부터 얻은 풍부한 시각 representation이 보이고, 오른쪽에는 MLLM 구조가 표시되어 있다.
VIRAL은 MLLM의 중간 layer의 시각 feature들이 VFM의 feature과 직접 정렬되도록 학습시킴으로써, 세밀한 시각 정보와 의미 구조를 MLLM이 내재화하도록 만든다.
(예시 질문: “이미지에 개가 몇 마리 있나요?“에 대해, VIRAL은 VFM의 도움으로 정확한 개체 수를 파악할 수 있게 된다.)
구체적으로, VFM encoder $E$에 동일한 입력 이미지 $I$를 통과시켜 타겟 feature $y = E(I) \in \mathbb{R}^{N \times d}$를 얻다. 여기서 $d$는 VFM feature의 채널 차원이다 (일반적으로 MLLM의 $D$와 다를 수 있음).
이제 $P_{\pi}$ projector는 MLLM $\ell$층의 시각 representation $e^{\text{img}}_{\ell} \in \mathbb{R}^{N \times D}$을 VFM feature 공간($d$차원)으로 매핑하며, 정렬 loss은 식 (5)의 $z$를 $y$로 대체하여 아래와 같이 정의된다:
\[L_{\mathrm{VRA}} = -\frac{1}{N} \sum_{i=1}^{N} \mathrm{sim}\Big(P_{\pi}(e^{\text{img}}_{\ell,i}), y_i\Big) \tag{7}\]- $y = E(I)$: VFM 인코더 $E$로부터 얻은 타겟 시각 feature (차원 $d$, 동결됨)
- 나머지 기호와 의미는 식 (5)와 동일하며, 이제 정렬 대상이 VFM의 feature $y$로 변경됨
식 (7)의 loss $L_{\mathrm{VRA}}$를 최소화하면, MLLM의 내부 시각 경로가 VFM의 강건한 feature에 맞춰 정규화된다.
이를 통해 공간적, 의미적으로 구조화된 시각 representation을 MLLM이 유지하도록 하는 효과가 있다.
Experiments
이 절에서는 VIRAL의 효과를 다양한 실험을 통해 검증한 내용을 정리한다. 각 실험들은 제안한 방법의 장점이나 설계 선택의 유효성을 확인하기 위한 목적으로 구성되었다.
Experimental Settings
모델 및 학습 구성
저자들은 실험에 LLaVA-1.5 프레임워크를 기반으로 사용하였다.
구체적으로, Vicuna-1.5-7B 언어모델(7억 파라미터)과 CLIP vision 인코더를 연결한 구조이며, 효율적인 fine-tuning을 위해 LoRA 기법을 적용했다. (참고로, LoRA 적용 시 성능이 풀튜닝과 유사한 수준으로 보고되었음).
학습 데이터는 LLaVA-665K 시각 지시 데이터만을 사용하였고, 추가 데이터 없이 실험을 진행했다.
projector $P_{\pi}$ (VIRAL에서 사용하는 내부 정렬 projector)는 3층 MLP로 구성하였고, 활성함수로 SiLU를 사용하였다.
모든 실험은 NVIDIA A100 (40GB) GPU 4장으로 수행되었다.
정렬에 사용된 VFM
VIRAL의 정렬 신호를 제공하기 위한 teacher VFM으로 다양한 pre-training vision 모델을 활용하였다. 실험에 언급된 VFM들은 다음과 같다:
- DINOv2: 자기 지도학습 기반의 강건한 feature 추출 모델
- CLIP: 이미지-텍스트 대조학습으로 훈련된 vision-언어 모델
- Depth-aware SAM: 세그멘테이션 파운데이션 모델 (여기 Depth Anything v2, RADIO 등 변형 포함)
- RADIO-v2.5: 다양한 시각 representation을 학습한 모델 (논문에서 사용)
- SAM: 이미지의 범용 분할을 위한 모델
이들 VFM은 모두 동결된 상태로, 정렬 대상 feature만을 제공하며 (backpropagation 시 gradient 미전달), VIRAL의 loss은 해당 feature과 MLLM 내부 representation의 유사도를 높이도록 작용한다 .
평가 지표 및 benchmark
VIRAL의 효과를 검증하기 위해 세 가지 범주의 benchmark에 대해 평가를 수행했다 :
- 시각-중심 task: 공간 추론 또는 객체 계수 등이 필요한 task들로, CV-Bench2D (2D 공간 이해), What’s Up (vision QA), MMVP (멀티모달 비디오 QA) 등이 포함된다.
- 멀티모달 환각 검출: 모델이 부정확한 시각 정보를 환각으로 생성하는지 평가하는 task로 POPE(PhOtometric Evaluation) benchmark를 활용했다.
- 일반적 멀티모달 이해: 일반적인 이미지-텍스트 종합 능력을 평가하는 MME 및 MMStar 데이터셋 을 사용했다.
각 benchmark의 지표는 해당 프로토콜을 따랐으며, CV-Bench2D, MMVP, What’s Up, POPE, MMStar는 정답 accuracy(Accuracy), MME는 총점으로 보고된다.
VIRAL의 목표는 시각적 그라운딩 향상을 통해 시각 중심 및 환각 민감 task에서의 성능 향상을 이루면서, 동시에 일반 멀티모달 능력도 유지 또는 향상하는 것이다 .
Main Results
제안한 VIRAL 기법을 적용한 모델과 기존 베이스라인 모델을 다양한 설정에서 비교한 결과, 모든 benchmark task에서 VIRAL이 일관된 향상을 보였다.
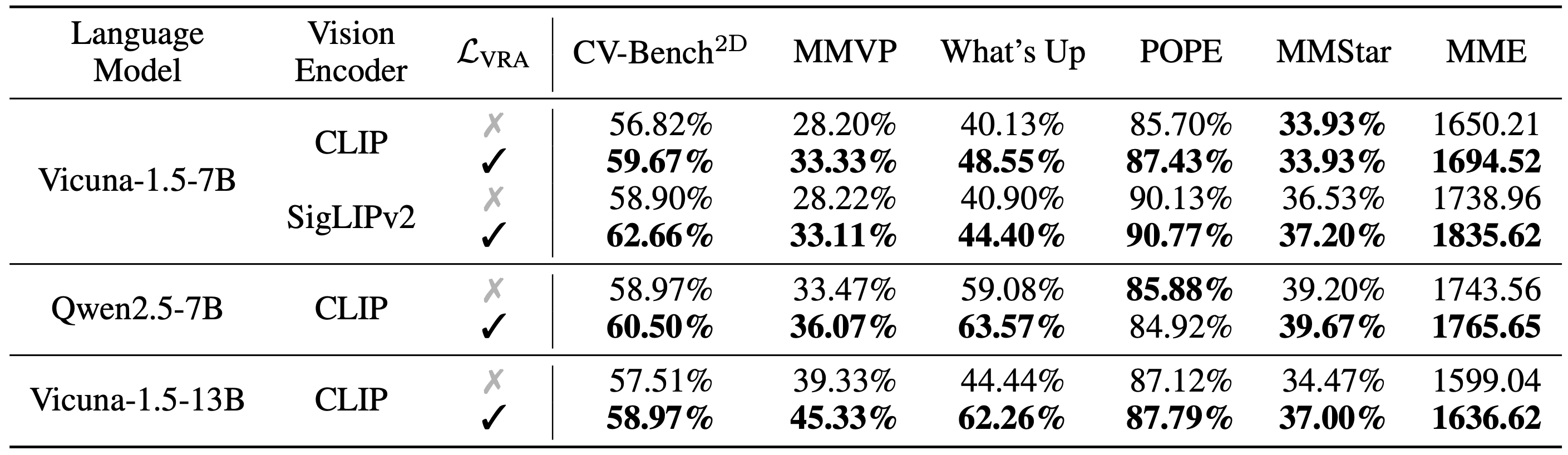
표 1은 주요 결과를 요약한 것으로, 동일한 조건에서 학습된 VIRAL 적용 모델이 기준선 대비 우수한 성능을 달성했음을 보여준다.
특히 세밀한 시각 이해가 요구되는 task들(예: CV-Bench2D의 공간 추론, What’s Up의 객체 카운팅 등)에서 가장 큰 성능 향상이 나타났다.
이는 VIRAL의 중간 representation 정렬이 실제로 세밀한 시각 정보 처리 능력을 높여주었음을 시사한다.
한편 POPE 환각 검출이나 MME 종합 평가 등에서도 성능 개선이 확인되어, VIRAL이 전반적인 멀티모달 이해 능력을 저해하지 않으면서도 시각적 정확성을 높인 것을 알 수 있다 .
흥미로운 점은, 이러한 성능 향상이 단지 “CLIP 인코더의 한계를 보완”하는 데에서 그치지 않았다는 것이다.
즉, 이미 더 강력한 인코더를 사용한 경우에도 VIRAL은 추가 이득을 주었다.
저자들은 SigLIPv2 인코더(대조학습 + 자기지도 결합으로 학습된 강력한 vision 인코더)를 사용해 실험했는데, 이처럼 인코더 자체 성능이 좋은 경우에도 정렬 loss을 추가하면 지속적인 개선이 나타났다.
예를 들어 CLIP 대신 SigLIPv2를 쓴 모델에서도 VIRAL 적용 시 CV-Bench2D, MMVP 등의 점수가 모두 상승하였다.
이는 VIRAL의 효과가 단순히 약한 인코더를 보완하는 것을 넘어서, 시각 representation의 구조적 정규화가 근본적으로 멀티모달 모델에 유익함을 보여준다 .
또한 VIRAL의 효과는 모델 크기와 종류에 상관없이 일반적으로 나타났다.
Vicuna-1.5-7B(7B 파라미터) vs Vicuna-1.5-13B(13B 파라미터) 크기 비교와, Vicuna 계열 vs Qwen2.5-7B 등 다른 LLM 백본에 대한 비교에서도, VIRAL을 적용한 쪽이 항상 더 나은 성능을 보였다.
이는 VIRAL의 정규화 접근법이 모델 규모가 커져도 계속 유효하며, 특정 LLM 아키텍처에 종속적이지 않고 범용적인 개선을 가져옴을 의미한다.
요컨대, VIRAL은 다양한 멀티모달 LLM 설정에서 시각 정보 활용 능력을 향상시키는 보편적 기법으로 확인되었다.
Ablation Studies
VIRAL의 성능에 영향을 주는 핵심 설계 요소들을 분석했다.
실험은 LLaVA-1.5-7B + DINOv2 설정을 기본으로 하여 진행되었으며, 표 2에 주요 결과가 정리되어 있다.
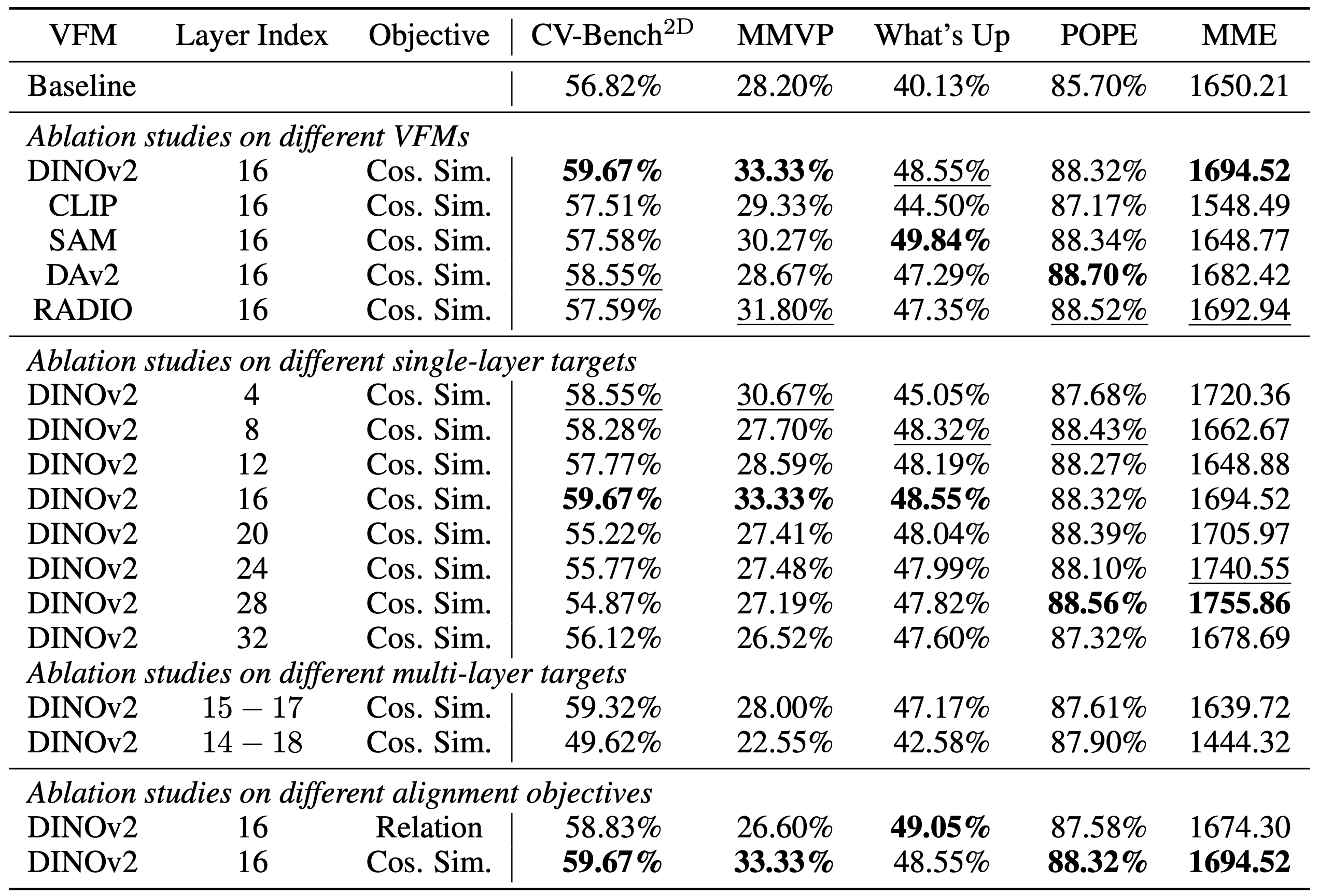
VFM
우선 어떤 VFM을 정렬 teacher로 쓰는 것이 가장 효과적인지 비교했다.
DINOv2, CLIP, SAM, Depth Anything v2(DAv2), RADIO 등 다양한 VFM을 시험한 결과, 전반적으로 DINOv2 사용 시 가장 좋은 성능 향상을 보였다.
예를 들어 CV-Bench2D, MMVP, What’s Up 등 시각 task에서는 DINOv2 기반 VIRAL이 다른 VFM 기반 대비 우세했다 (표 2 상단 섹션).
이는 자기 지도학습으로 학습된 DINOv2의 representation이 다른 모델보다 풍부한 시각 정보를 제공하여 MLLM을 보강하는 데 유리했기 때문으로 보이다.
반면 CLIP이나 SAM 등도 개선을 주었으나, CLIP의 경우 MMVP에서의 한계 등 모델 고유 편향이 일부 나타나는 것으로 보이다.
Different single-layer targets
VIRAL은 기본적으로 16번째 layer의 시각 representation을 정렬하도록 설정했는데, 어느 layer에 적용하는 것이 최적인지 실험했다.
단일 layer을 대상으로 4, 8, 12, 16, 20, 24, 28, 32층 등 여러 후보를 비교한 결과, **16층에서 정렬할 때 성능이 가장 좋았다 . **
특히 CV-Bench2D 등의 성능이 16L에서 최고였고, 너무 초기 layer(예: 4L)이나 너무 후반 layer(28L, 32L)은 효과가 떨어졌다.
이는 중간 layer이 시각 정보와 언어 정보의 접점이 되는 중요한 구간임을 다시 한번 시사
또한 멀티-layer 정렬(예: 15–17층 등)을 시도한 결과, 단일 16층 정렬보다 오히려 성능이 낮아졌다.
여러 layer을 함께 맞추면 모델의 representation learning에 과부하가 걸리거나 과적합적 제약이 될 수 있음을 보여준다.
따라서 하나의 중간 layer을 골라 정렬하는 현재 방법이 가장 효율적임이 확인되었다.
Alignment objectives.
정렬 loss로 논문에서는 코사인 유사도(Cosine Similarity)를 채택하였는데, 이에 더해 관계형 특성 정렬(Relation alignment)도 시험했다.
관계형 정렬은 시각 feature 간 자기-유사도 행렬(self-similarity matrix)을 맞추는 방법으로, 보다 관계적인 정보를 보존하려는 목표이다.
그러나 실험 결과 관계 정렬(loss)은 직접 feature 정렬보다 성능이 낮았다 .
예컨대 CV-Bench2D, MMVP 등에서 코사인 정렬이 더 높은 수치를 기록했다. 이는 고차원 관계 대신, 개별 patch feature을 직접 맞추는 단순한 방식이 오히려 효과적임을 보여준다.
VIRAL의 간결한 정렬 전략이 최적임을 뒷받침하는 결과라 하겠다.
Conclusion of ablation study
- DINOv2를 정렬 teacher로 사용
- 중간 16번째 layer의 feature을 대상
- 사인 유사도 기반 정렬loss을 적용
하는 현재 VIRAL 설계가 가장 합리적이고 성능이 좋다는 결론을 얻었다.
이러한 설계 선택들이 각각 모델 향상에 기여함이 검증되어, VIRAL 기법의 구성 요소에 대한 신뢰성을 높였다.
추가 Analysis
VIRAL이 가져온 모델 내부 변화를 심층적으로 들여다보기 위해, 저자들은 attention 분포와 학습 곡선, 입력 교란 실험 등을 수행했다.
Attention analysis
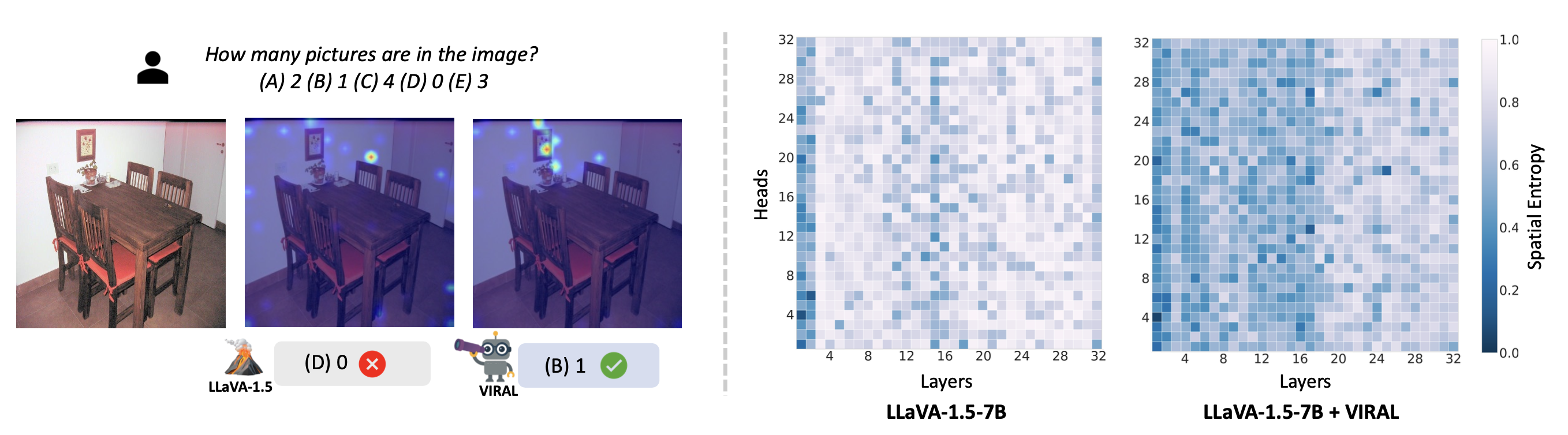
VIRAL 적용 전후의 텍스트-투-이미지 attention map을 비교하고, layer/헤드별 attention의 공간적 entropy를 정량화하였다.
결과에 따르면, VIRAL을 적용한 모델은 보다 명확하고 집중된 attention 패턴을 보였다.
시각적으로도, 질문과 관련된 이미지 영역에 attention이 모이고 불필요한 부분에는 덜 할당되어, 맥락적으로 중요한 콘텐츠에 집중함을 확인할 수 있었다.
이는 VIRAL이 내부 representation을 정규화하면서 모델이 중요한 시각 단서에 주목하도록 도와주는 효과가 있음을 시사한다.
Training efficiency

POPE나 CV-Bench2D 등에 대해 학습 단계별 성능 곡선을 그린 결과, 정렬 loss을 도입한 모델이 초기 단계부터 더 높은 성능으로 출발하고 빠르게 수렴하는 경향을 보였다.
이는 추가적인 시각 감독 신호가 모델의 학습을 가속하고, 효율적인 최적화 경로를 제공할 수 있음을 암시한다.
저자들은 VIRAL이 훈련 효율성 측면에서도 이점이 있다고 언급했다.
Robustness analysis
시각 정보 보존의 효과를 직접 검증하기 위해, 입력 이미지의 공간적 위치를 무작위로 섞었을 때 성능 변화를 측정하는 실험도 수행되었다.
CV-Bench2D의 공간 추론 태스크에서, 원본 이미지와 patch 순서를 랜덤하게 뒤섞은 이미지를 각각 입력하여 정답률 감소폭을 비교했다.
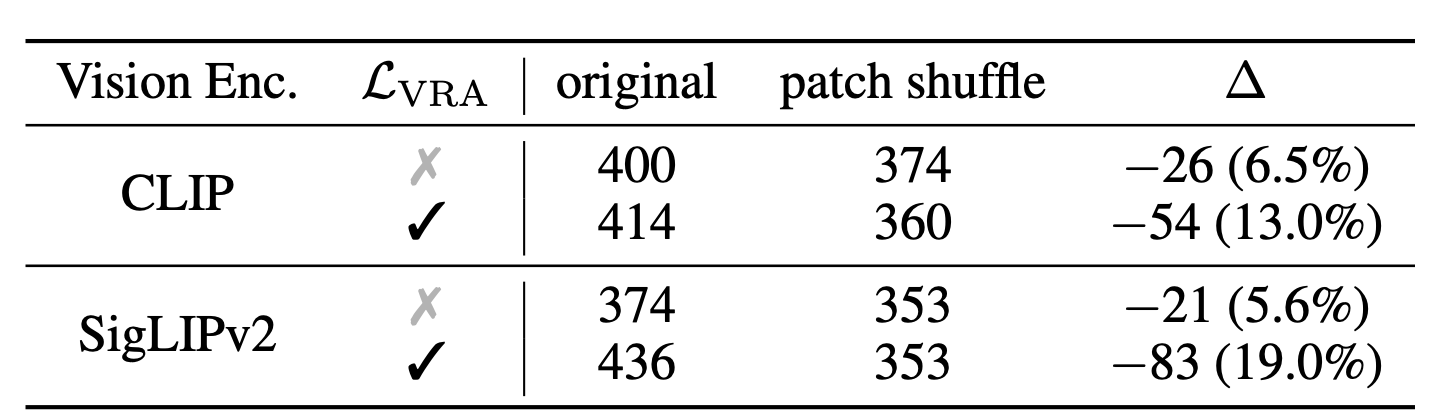
그 결과, 기존 텍스트-전용 학습된 모델은 이미지 token 순서가 뒤집혀도 성능 감소가 미미했지만 , VIRAL로 학습된 모델은 순서 교란 시 성능이 크게 하락했다.
이는 VIRAL 모델이 이미지 내 patch들의 상대적 위치 정보를 예민하게 활용하고 있다는 증거이다.
다시 말해, 공간적 token 배열을 중요한 단서로 인식하기 때문에 순서가 뒤섞이면 답을 잘 못하게 되는 것이다.
반면 기존 모델은 애초에 공간적 구조를 거의 무시하고 답했기 때문에 순서가 바뀌어도 영향이 없었던 것이다.
이 실험은 VIRAL의 정렬 loss이 MLLM이 세밀한 공간 관계까지 학습하도록 동기화함을 보여주는 직접적인 증거이다 .
Qualitative Results
마지막으로, VIRAL의 효과를 직관적으로 시각화하기 위해 모델 응답 비교와 내부 representation 시각화를 수행했다.
아래 그림은 베이스라인(LLaVA-1.5-7B)과 VIRAL 적용 모델(Ours)의 차이를 사례로 보여준다:
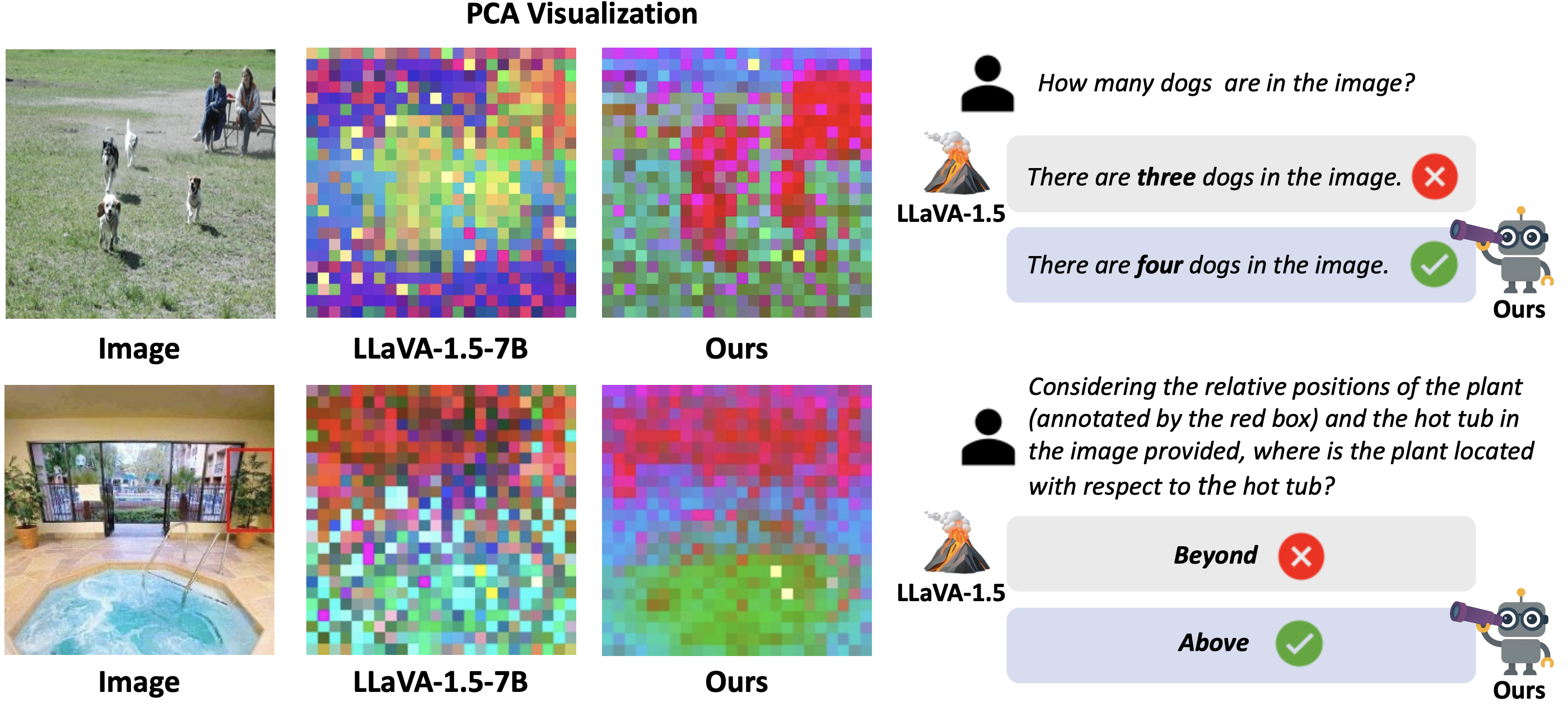
VIRAL 적용 전후 모델의 정성적 비교
(좌) PCA 시각화
- 중간 layer(16층)에서의 시각 feature들을 PCA로 2차원 투영하여 컬러로 representation한 것
- 동일한 이미지를 넣었을 때, 기존 모델의 내부 embedding은 무작위 색점에 가깝게 분포
- VIRAL 모델의 embedding은 더 구조화되고 의미별로 뭉쳐진 패턴
이는 VIRAL이 내부 시각 embedding 공간을 의미적으로 정돈했음을 나타낸다.
(우) 질문 응답 비교
- 상단 예시는 “이미지에 개가 몇 마리 있나요?“라는 질문에 대해, 베이스라인은 “개 3마리”라고 틀리게 답했지만 VIRAL은 “개 4마리”로 정확히 객체 수를 카운팅
- 하단 예시는 공간 관계 질문으로, 온수 욕조 사진에서 “화분이 온수 욕조에 대해 어디에 위치하나요?“라는 물음에 대해
- 기존 모델은 엉뚱하게 “Beyond(너머)”라고 대답
- VIRAL 모델은 “Above(위쪽)”라고 정확한 상대 위치를 답변
- 이처럼 VIRAL을 적용한 모델은 객체의 개수 식별이나 공간적 위치 관계 파악과 같은 도전적인 시각 질문에도 정확히 대답하는 반면, 기존 모델은 자주 실패
이는 VIRAL이 세밀한 시각 정보에 기반한 추론 능력을 향상시켰음을 직접적으로 보여주는 예시
Conclusion
본 논문에서는 멀티모달 LLM의 시각 경로가 텍스트-only 학습으로 인해 정보를 loss하는 문제를 짚어내고, 이를 해결하기 위해 VIRAL이라는 시각 representation 정렬 기법을 제안하였다.
VIRAL은 MLLM 내부의 시각 representation을 VFM의 representation과 직접 맞춤으로써, 기존에 학습 중 버려지던 세밀한 시각 의미를 보존하도록 유도한다.
이 간단하면서도 효과적인 정규화 전략은 모델로 하여금 더 정확한 객체 인식, 공간 추론 등을 수행하게 만들었고, 다양한 benchmark 실험에서 성능 및 학습 효율 향상을 확인하였다.
VIRAL은 특정 인코더나 언어모델에 국한되지 않고 범용적으로 적용 가능하며, 모델의 멀티모달 정보 통합 방식을 근본적으로 개선하는 방향으로 기여한다.
Limitation
VIRAL은 새로운 시각 감독 신호를 도입함으로써 성능을 높였지만, 동시에 몇 가지 고려할 점도 있다.
- 추가적인 VFM 사용에 따른 계산 자원 요구 증가
- 훈련 시 매번 이미지를 VFM에도 통과시켜야 하므로, 학습 비용이 상승
- 다만 정렬 신호 덕분에 학습 효율이 높아지는 면도 관찰되었기에 절대 비용은 과하지 않을 수 있다.
- 정렬 대상인 VFM의 한계가 그대로 전이될 가능성
- 실제로 CLIP을 사용할 경우 특정 task(MMVP)에서 성능이 떨어졌듯이 , VFM 선택에 따라 성능 편차가 있을 수 있다.
- 따라서 다양한 VFM의 조합이나 더 전문화된 VFM 활용 등으로 보완할 여지가 있다.
VIRAL은 주로 이미지 이해에 초점을 맞춘 기법이므로, OCR처럼 텍스트가 포함된 이미지 처리나 동영상 등 다른 모달리티 확장에 대한 추가 연구도 향후 task로 남아 있다.
그럼에도 불구하고, VIRAL은 MLLM 훈련에서 시각 정보 통합의 새로운 가능성을 제시한 의미 있는 성과로 평가된다.