[Paper Review] Vision-Language-Vision Auto-Encoder:Scalable Knowledge Distillation from Diffusion Models
[논문 리뷰] Vision-Language-Vision Auto-Encoder: Scalable Knowledge Distillation from Diffusion Models
Vision-Language-Vision Auto-Encoder: Scalable Knowledge Distillation from Diffusion Models
Tiezheng Zhang et al,.
NeurIPS 2025
[arXiv] [Project Page]
Background
Variational Autoencoder (VAE)
VAE는 입력 데이터를 latent space으로 인코딩한 후 이를 원래 데이터 분포로 다시 디코딩하는 생성 모델이다.
VAE는 입력(예: 이미지 $x$)을 잠재 representation(보통 $z$로 표기)으로 매핑하는 인코더와, $z$로부터 입력을 재구성하는 디코더로 구성된다.
VAE는 latent space에 확률 분포(일반적으로 가우시안)를 부과하고 KL divergence 정규화를 추가한다.
이를 통해 VAE는 잠재 분포에서 sampling하여 새로운 데이터를 생성할 수 있다.
즉, VAE는 입력 데이터의 확률 분포를 배우며 새로운 샘플을 생성할 수 있는 확률적 AutoEncoder이다.
이러한 구조는 이미지 생성 모델의 pre-training 등에 활용되며, 예를 들어 Stable Diffusion 등의 diffusion model에서는 고해상도 이미지를 낮은 차원의 latent vector로 압축하고 복원하기 위해 VAE를 사용한다.
Representation Learning with Diffusion Models
Diffusion 모델을 representation learning에 활용하려는 연구 흐름은 크게 “Diffusion 모델이 가진 생성 지식을 어떻게 feature나 embedding으로 뽑아내어 downstream에 쓰는가”로 정리된다.
- Frozen T2I diffusion을 언어 정렬 embedding 학습에 활용
- De-Diffusion, ViLex는 pre-training된 텍스트-조건 Diffusion 모델을 동결한 채로 사용하면서, 그 모델이 내재한 멀티모달 의미 구조를 이용해 언어 공간에 정렬된 embedding을 학습
- Diffusion 모델의 내부 representation을 ‘교사’로 증류
- DreamTeacher는 Diffusion 모델이 제공하는 생성적 feature을 분류(backbone) 모델로 증류하여 인식 성능을 강화
- denoising 과정을 자기지도 representation학습으로 재해석
- DiffMAE는 Diffusion의 노이즈 제거를 masked autoencoding 관점에서 재구성하여 representation learning task로 변환
- vision-언어 영역에서 diffusion prior를 활용한 확장
- SPAE는 semantic autoencoding으로, RLEG는 synthetic contrastive supervision으로 이미지-언어 이해를 연결
- ODISE와 DIVA는 diffusion priors로 open-vocabulary segmentation이나 CLIP의 시각적 지각을 강화RepFusion은 time-step별 feature을 명시적으로 채굴하여 분류에 활용
이 논문의 위치는 위 흐름들 가운데,
- text/vision을 함께 co-train하지 않고,
- 사람이 설계한 병목(handcrafted bottleneck)이나 synthetic supervision 없이,
- 동결된 텍스트-조건 Diffusion 모델의 생성 지식을 연속 latent로 “직접 전이(transfer)”
하여, 그 latent가 고충실도 재구성과 경쟁력 있는 캡션 생성을 동시에 지지하도록 만든다는 점으로 요약된다.
Introduction
최신 Vision-Language 모델로 강력한 Image Captioning 성능을 달성하려면 대규모의 고품질 이미지-텍스트 데이터로 거대한 모델을 학습해야 한다. 이는 수십 억 pair의 데이터와 막대한 GPU 연산을 필요로 하며, 훈련 비용이 매우 높다.
본 연구의 Vision-Language-Vision (VLV) AutoEncoder 프레임워크는 이러한 부담을 획기적으로 줄이면서도 동급 최고 수준의 이미지 캡션 생성기를 구축하는 새로운 방법을 제시한다.
VLV는 세 가지의 사전 학습된 모듈을 전략적으로 활용한다:
- 시각 인코더(이미지 인코더)
- 텍스트-투-이미지 diffusion model의 디코더
- 대규모 언어 모델(LLM)
핵심 아이디어는 diffusion model을 AutoEncoder의 디코더로 활용하여, 이미지로부터 추출된 embedding이 diffusion model을 통해 다시 이미지로 재구성되도록 하는 것이다.
이때 diffusion model은 동결(freeze)되어 업데이트되지 않으므로, 이미지 인코더가 생성하는 중간 representation 공간이 자연히 “언어적” 정보 병목 역할을 하게 된다.
다시 말해, diffusion model이 이해할 수 있는 형태로 제한된 representation 공간을 형성함으로써, 시각 정보의 핵심적인 언어 representation만 남도록 유도한다.
이렇게 학습된 연속형 embedding을 다시 LLM 디코더를 통해 텍스트 설명으로 풀어내면, 결과적으로 거대한 이미지-텍스트 페어 없이도 뛰어난 캡션 생성 성능을 얻을 수 있다.
실제로 VLV 모델은 GPT-4나 Gemini 2.0 Flash 등 최첨단 상용 모델에 견줄 만한 캡션 품질을 보이면서도, 훈련 비용을 $1,000 이하로 억제하는 데 성공하였다.
Goal
거대 멀티모달 모델의 지식을 효율적으로 distillation하여, 대량의 이미지-텍스트 쌍 데이터 없이도 인간 수준의 상세한 이미지 설명을 자동 생성할 수 있는 새로운 비용 효율적 캡션 생성 시스템을 구축
Motivation
기존 비전-언어 모델들은 방대한 자원 없이 개발하기 어려웠다. 이에 대한 돌파구로, 사전 학습된 강력한 생성 모델이 이미 지니고 있는 멀티모달 지식을 활용하고자 했다.
Diffusion 모델은 이미지 생성 능력을 통해 시각 정보를 언어적 의미 공간으로 암묵적으로 투영하고 있으며, 이를 거꾸로 이용해보자는 아이디어가 연구의 출발점이다.
BLIP-2 등 일부 선행 연구에서 이미지 → 임베딩 → 언어 모델로 이어지는 효율적 파이프라인의 가능성을 보였으나, 연산 효율성과 세부 정보 손실 문제
본 연구는 Diffusion 모델을 디코더로 통합함으로써 이러한 한계를 극복
Contributions
- Vision-Language-Vision 오토인코더라는 새로운 프레임워크를 제안하였다.
- 이는 연속적인 임베딩 공간을 통해 시각과 언어를 연결함으로써, 기존의 토큰 단위 중간 표현이 갖는 비효율성과 정보 손실을 줄였다 .
- 사전 학습된 이미지 인코더 + Diffusion 디코더를 활용한 자기 지도 학습으로 대규모 병렬 데이터 없이도 이미지의 세밀한 의미를 캡처하는 방법을 보였다.
- 학습된 임베딩을 대규모 언어 모델에 연결하여 최소한의 fine-tuning으로도 인간 수준의 장문 캡션을 생성하는 데 성공하였고, 그 결과 품질 면에서 GPT-4 등과 동등하면서 세 자릿수 이상 비용 절감을 달성
요약하면, VLV는 강력한 성능과 효율성을 동시에 입증한 멀티모달 모델로서, 한정된 자원으로도 최첨단 VLM을 구현할 수 있는 가능성을 제시한다.
Method
Pipeline Overview
VLV Autoencoder는 Autoencoder 형태의 전체 구조를 갖추고 있으며, 입력 이미지를 압축했다가 다시 복원하는 과정을 통해 학습한다. 이를 구성하는 핵심 모듈은 세 가지이다 :
VLV 인코더 (Vision Encoder)
- 이미지 입력을 받아 연속적인 “캡션” 임베딩으로 변환하는 인코더
- 사전 학습된 Vision backbone(예: ViT 등)을 기반으로 하며, 그 상단에 경량 멀티모달 어댑터가 붙어 있음
- 이 어댑터는 이미지로부터 추출된 피처들을 학습 가능한 쿼리 토큰들과 함께 Transformer를 통해 처리
- 시각 정보가 언어 의미에 맞게 요약된 임베딩 표현을 생성
- 이렇게 얻어진 임베딩은 “캡션 임베딩”으로서, 입력 이미지의 중요한 시각적 내용과 의미를 압축한 벡터 표현
Diffusion Decoder
텍스트-투-이미지 Diffusion 모델의 디코더 부분을 그대로 사용
“디코더”란 Diffusion 모델에서 텍스트 조건을 받아 이미지를 생성하는 모듈
Stable Diffusion의 경우 CLIP 텍스트 인코더와 U-Net을 포함한 전체 생성 과정을 지칭
- VLV에서는 이 Diffusion Decoder를 동결
- VLV 인코더가 출력한 임베딩은 Diffusion 디코더의 텍스트 조건 입력으로 들어가며, Diffusion 모델은 해당 임베딩에 따라 입력 이미지를 복원하도록 동작
- 이미지 → 임베딩 → (고정된) Diffusion 모델 → 이미지 재생성**
캡션 디코더 (Caption Decoder):
- 사전 학습된 대규모 언어 모델(LLM)을 기반으로 하는 텍스트 생성 모듈
- 위에서 얻은 동일한 캡션 임베딩을 입력받아 자연언어 문장(이미지 설명)을 생성
- VLV 인코더가 뽑아낸 임베딩을 LLM의 입력 공간에 맞게 변환하기 위해 소형 MLP 프로젝터를 사용
- 이 프로젝터가 출력한 벡터들을 LLM의 입력에 프롬프트 토큰처럼 첨부하면, LLM이 이를 조건으로 삼아 이어지는 캡션 단어들을 autoregressive하게 생성
- LLM 자체는 GPT 계열 또는 그와 유사한 구조(decoder 구조)이며, 훈련 과정에서 이 모듈을 파인튜닝하여 임베딩→텍스트 변환 능력을 갖춤
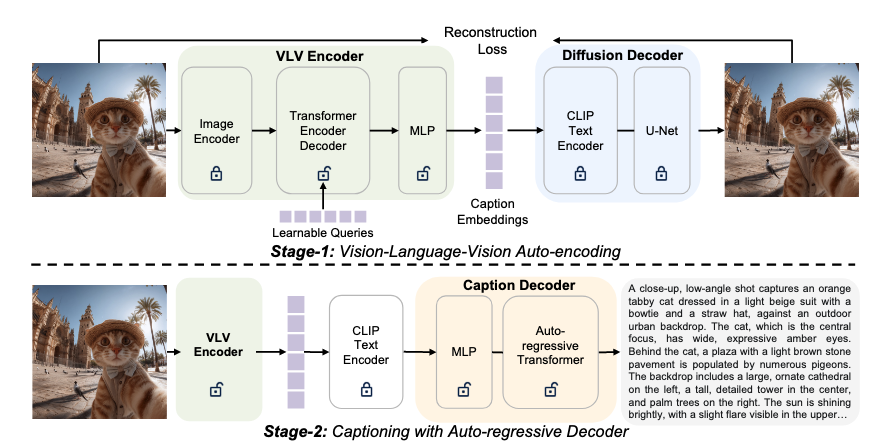
VLV의 전체 학습은 두 단계(Stage)로 이루어진다.
- 1단계 : 지식 증류 단계
- 여기서는 대량의 이미지 단일 모달 데이터만으로도 학습이 가능
- 2단계 : 학습된 임베딩을 텍스트로 풀어내는 단계
- 비교적 소량의 이미지-텍스트 쌍 데이터를 사용하여 LLM 디코더를 fine-tuning
**Stage 1: Knowledge Distillation from Diffusion Models **
1단계에서는 텍스트 조건부 Diffusion 모델에 내재된 시각-언어 지식을 이미지 인코더로 distillation하는 과정을 거친다 .
- 우선 입력 이미지 $x$를 VLV 인코더에 통과시켜 캡션 임베딩 $z$를 얻는다.
- 이 임베딩은 학습 가능한 projector를 거쳐 CLIP 텍스트 인코더의 입력 공간으로 매핑되며, 마치 문장 임베딩인 것처럼 CLIP 인코더에 입력된다 .
- CLIP 텍스트 인코더 (동결된 상태)는 이 임베딩을 처리하여 텍스트 조건 표현을 생성하고, Diffusion 모델의 U-Net 디코더는 이를 조건으로 이미지를 생성/복원한다.
훈련 시에는 실제 입력 이미지와 동일한 결과가 나오도록 모델을 최적화해야 하지만, Diffusion 모델 파라미터는 고정되어 변화하지 않는다.
따라서 VLV 인코더의 파라미터만 학습되며, 이 인코더는 이미지의 의미를 최대한 보존하는 임베딩을 뽑아내도록 압박받는다.
이를 위해 논문에서는 Diffusion 모델 학습에 쓰이는 표준 denoising 손실 함수를 활용한다 :
\[\mathcal{L}_\text{denoise} = \mathbb{E}_{t,\epsilon,x}\Vert \epsilon_\theta(z_t,t,z) - \epsilon \Vert^2_2\]위 손실 함수는 Diffusion 모델의 노이즈 예측 오류를 최소화하도록 VLV 인코더를 학습시킨다 .
쉽게 말해, 이미지 인코더가 뽑은 임베딩 $z$가 정확하면 Diffusion 모델이 $\epsilon$을 더 잘 예측해 원본 이미지를 복원할 수 있고, 부정확하면 오차가 커진다.
따라서 인코더는 점차 이미지의 모든 재구성 가능한 시각 정보를 임베딩 $z$에 압축하도록 훈련된다.
이는 곧 이미지의 중요한 객체, 속성, 배경 맥락 등에 관한 의미론적 정보가 $z$에 담긴다는 뜻
원래 diffusion 모델 학습에서는 고정된 VAE로 만든 $z_t$로 Unet($\epsilon$)이 noise 예측을 잘하게 하는 방향으로 학습
하지만 여기서는 Unet이 고정되어있고, $z_t$를 더 잘 생성하도록 VAE기반의 VLV encoder를 학습하는 것임
결과적으로 VLV 인코더는 Diffusion 디코더(텍스트 조건부 생성기)를 거쳐 이미지를 복원할 수 있을 만큼 풍부한 시맨틱 임베딩을 획득하게 된다.
이 임베딩은 연속적인 벡터 공간을 형성하기 때문에 기존의 discrete token이나 Gumbel-Softmax 등을 사용하는 방법보다 훈련이 효율적이고 미세한 정보까지 보존할 수 있다는 장점이 있다.
이렇게 1단계 과정을 통해 이미지 → 임베딩 → 이미지로 이어지는 Vision-Language-Vision 오토인코더가 완성된다.
저자들은 이 과정을 “Knowledge distillation”라고 부르며, 거대한 텍스트-투-이미지 모델이 가지고 있는 지식을 연속 임베딩 형태로 추출해낸 것으로 해석한다 .
Stage 2: Caption Decoding from Language-centric Representations
2단계에서는 1단계에서 학습된 캡션 임베딩 $z$를 텍스트로 변환하는 언어 디코더를 훈련한다.
이 디코더는 pretrained LLM을 기반으로 하며, 이미지로부터 얻은 임베딩을 입력으로 받아 자연어 캡션을 생성하도록 fine-tuning된다. 구체적으로, 1단계에서 사용했던 CLIP 텍스트 인코더 역시 그대로 동결하여 활용한다.
VLV 인코더가 출력한 임베딩 $z$를 CLIP text encoder $T(\cdot)$에 넣으면, 해당 임베딩에 대응하는 컨텍스트 표현 $c = T(z)$를 얻을 수 있다.
이것은 마치 실제 문장을 넣었을 때 CLIP가 출력하는 문맥 벡터들과 유사한 형상
이후 이 $c$를 학습 가능한 MLP 프로젝터 $\psi$에 통과시켜 LLM의 hidden space으로 투영한 벡터 $e = \psi(c)$를 얻는다.
벡터 $e$는 최종적으로 LLM의 입력 토큰 시퀀스 앞부분에 prepending되어, 대화 맥락처럼 작용
원래 캡션 입력: $[\mathrm{Embed}(y_1), \ldots, \mathrm{Embed}(y_T)]$
prepending 후 입력: $[e;\mathrm{Embed}(y_1), \ldots, \mathrm{Embed}(y_T)]$
LLM은 이러한 벡터 $e$와 실제 캡션의 일부 단어들을 입력받아 나머지 단어들을 생성하도록 학습된다.
훈련 목표는 일반적인 자기회귀 언어 모델의 손실과 동일하게, 다음 단어 예측의 교차 엔트로피 최소화이다.
논문에서는 이를 다음과 같이 수식으로 표현하였다 :
\[\mathcal{L}_\text{LM} = -\sum^T_{t=1} \log p_\theta(y_t \mid e, y_{<t})\]위 손실함수는 주어진 이미지 임베딩 $e$가 있을 때 올바른 캡션 $y_1, y_2, \dots, y_T$를 생성하도록 LLM의 파라미터를 조정한다 .
이때 $e$에는 마스킹 처리를 통해 autoregressive loss에서 제외
다시 말해, LLM이 이미지 임베딩 $e$을 조건으로 받아들여 해당 이미지에 대한 자연스러운 서술문을 이어서 쓸 수 있게끔 학습되는 것이다.
실제로 VLV에서는 공개된 오픈소스 LLM (예: Qwen-7B 등)을 초기화 모델로 사용하여 학습비용을 절감하였다.
또한 훈련 데이터로는 1단계에서 모은 이미지들 중 일부에 대해 대형 모델 GPT-4 계열을 활용해 생성한 캡션을 정답 레이블로 사용하였다 .
이렇게 함으로써 인간 주석 데이터가 거의 없음에도 고품질의 이미지-텍스트 쌍을 확보하여 지도 학습을 수행할 수 있었다.
결국 2단계를 마치면, 이미지 → VLV 인코더 → 연속 임베딩 → LLM 디코더 → 캡션 텍스트의 완전한 이미지 캡션 생성 파이프라인이 완성된다.
VLV 모델은 입력 이미지를 고정된 Diffusion 모델을 통해 재구성할 수 있을 뿐만 아니라, LLM을 통해 자세한 문자 설명으로도 풀어낼 수 있게 된 것이다.
Experiment
Experimental Setup
Dataset
- Stage 1: 대용량의 이미지 데이터만으로 이루어진 단일 모달 데이터셋이 사용
- LAION-5B 데이터 중 품질이 높은 하위집합인 LAION-2B-en-aesthetic에서 4천만 장의 이미지를 엄선
- 이미지의 해상도(짧은 변 기준 512px 이상), 종횡비(0.52.0), 워터마크 유무 등을 기준으로 엄격한 필터링을 거쳐 고품질 샘플을 확보
- Stage 2:을 위해서는 별도로 6M 쌍의 이미지-텍스트 데이터
- 텍스트(캡션)은 1단계에서 모은 이미지들 중 6백만 장에 대해 Gemini 2.0 Flash 모델을 사용하여 생성
- 이렇게 얻은 자동 캡션들은 일반적인 사람 작성 캡션보다 훨씬 길고 자세하며 (평균 226.8자, 대부분 170280자 범위) , 이미지의 공간 배치와 세부 묘사까지 포함
- 고화질 이미지와 대형 모델이 생성한 고품질 캡션 pair
- 텍스트(캡션)은 1단계에서 모은 이미지들 중 6백만 장에 대해 Gemini 2.0 Flash 모델을 사용하여 생성
이러한 2단계 데이터의 활용으로 VLV의 언어 디코더는 사람 주석 없이도 충분히 상세한 텍스트 생성 능력을 학습할 수 있었다.
VLV가 사용한 전체 데이터량은 WebLI 등 기존 대규모 멀티모달 학습에 사용되는 10억 장 규모 데이터의 0.4% 수준에 불과
Training Details
VLV 인코더
backbone: 사전 학습된 ViT 계열 모델이 사용
multi-modal adapter: 몇 개의 학습 가능한 쿼리 토큰과 Transformer 레이어로 구성된 모듈
쿼리 토큰의 개수 등의 세부 설정은 성능을 고려해 최적화
뒤의 Ablation 실험에서 분석
Diffusion 디코더
- Stable Diffusion 계열 모델
- 해당 모델의 텍스트 인코더와 U-Net는 모두 freeze
- Stable Diffusion 계열 모델
LLM 기반의 캡션 디코더
- Qwen-2.5
- 6M 이미지-텍스트 쌍에 대하여 수 epoch 파인튜닝
훈련 비용
- 1단계는 대량의 이미지에 대해 자기 지도 학습이지만 텍스트 처리 부담이 없고, 2단계는 비교적 데이터셋이 적음
- 전체 VLV 훈련은 총 $1,000 달러 이하의 비용으로 완료
- 이는 동일한 작업을 거대 모델(GPT-4 등)로 달성하기 위한 비용 대비 3자리 수 이상 낮음
Main Results
1. Text-Conditioned Reconstruction
실험 개요
목적: 생성된 캡션이 원본 이미지의 시각적 정보를 얼마나 잘 담고 있는지 평가.
방법: 모델이 생성한 캡션을 Stable Diffusion 3.5 Medium에 입력하여 이미지를 다시 만들고, 원본 이미지와의 차이를 FID 지표로 측정
점수가 낮을수록 좋음
데이터: MS-COCO 2014 검증 데이터셋 30,000장.
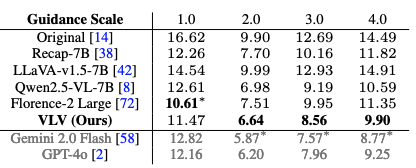
주요 결과 (정량적 평가)
GPT-4o와 대등
- VLV의 캡션 성능은 가장 강력한 상용 모델인 GPT-4o와 FID 차이가 0.5 미만으로, 사실상 구별 불가능한 수준의 시각적 묘사력
기존 모델 압도: Florence-2, Qwen2.5-VL 등 다른 공개 모델들보다 현저히 좋은 FID 점수를 기록
SOTA는 비공개 모델인 Gemini 2.0 Flash만이 VLV보다 근소하게 앞선 성능을 보임

정성적 평가
- VLV의 캡션 embedding과 이를 통해 디코딩된 텍스트 모두 원본 이미지의 시각적 의미(Visual Semantics)를 매우 충실하게(Faithfulness) 보존하고 있음을 확인
2. Captioner Arena: Rating with VLMs and Humans
사람과 고성능 AI가 보기에 캡션이 얼마나 자연스럽고 정확한지를 평가한 실험
실험 개요
- 평가 대상: VLV, Qwen-2.5-VL, GPT-4o가 생성한 캡션.
- 평가자
- AI 심사위원: Gemini 2.0 Flash (최신 고성능 VLM).
- 인간 평가자: 3명의 독립적인 평가자.
- 평가 기준
- 포괄성 (Coverage)
- 할루시네이션 부재 (No Hallucination)
- 공간 배치 일관성 (Spatial-layout Consistency)
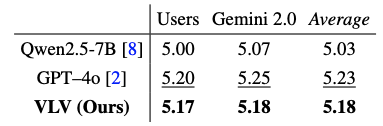
주요 결과
- GPT-4o와 대등: VLV의 평점은 GPT-4o와 0.05점 미만의 미미한 차이를 보여, 사실상 동등한 품질
- Qwen-2.5-VL 능가: VLV는 Qwen-2.5-VL-7B 모델보다 평균 0.15점 더 높은 점수를 기록함.
- 인간 선호도: 3명의 인간 평가자 중 1명은 오히려 GPT-4o보다 VLV의 캡션을 더 선호함.
3. Text-Only Question-Answering
실험 개요
- 목적: VLV가 생성한 캡션이 이미지의 ‘전역적 의미(Global Semantics)’와 ‘세부적인 외형 정보(Fine-grained appearance cues)’를 얼마나 논리적으로 잘 포함하고 있는지 검증.
- 평가 방법 (Text-Only VQA)
- 이미지를 사용하지 않음: 시각적 질문에 답하는 과제에서, DeepSeek-V3에게 이미지를 보여주는 대신 VLV가 생성한 텍스트 캡션만을 문맥(Context)으로 제공하여 질문을 풀게 함.
- 정답 기준: LLM의 답변이 Ground Truth과 ‘정확히 일치’해야 정답으로 인정.
- 설정: 별도 Fine-tuning 없이 Zero-shot과 Few-shot (4, 32) 환경에서 평가.
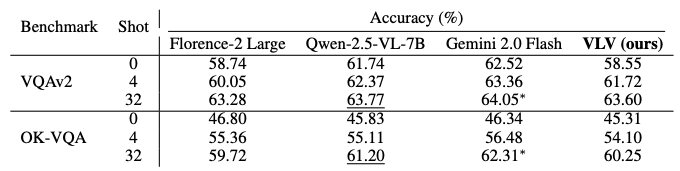
주요 결과
- Zero-shot 성능: 예시가 없는 엄격한 환경에서는 SOTA 보다 약 3% 낮은 성능을 보임.
- Few-shot에서의 압도적 향상: 문맥 예시가 주어졌을 때 성능 향상 폭이 타 모델 대비 가장 큼
- 최종 경쟁력: 32-shot 설정에서는 SOTA 모델(Gemini 2.0 Flash)과 1% 포인트 이내의 차이로 격차를 좁힘.
- 결론: VLV가 모든 설정에서 1위를 한 것은 아니지만, 압도적으로 낮은 학습 비용으로도 최상위 모델들과 대등한 수준의 정보를 담은 캡션을 생성할 수 있음을 입증
Ablation Studies
1. Progressive Training Leads Better Performance
모델을 학습시킬 때 “얼마나 많은 부분을 학습시키느냐”에 따른 성능 변화를 측정
- 실험 변수
- 쿼리 토큰 수 ($N_q$): VLV 오토인코더의 학습 가능한 쿼리 개수를 16개, 32개, 77개로 늘려봄.
- 모듈 동결 해제 (Unfreezing) 범위: 2단계 학습(캡션 생성) 시, [MLP만 학습] $\rightarrow$ [+LLM 디코더 학습] $\rightarrow$ [+VLV 인코더까지 학습] 순으로 학습 범위를 넓혀봄.

- 결과
- 쿼리 토큰 수가 많을수록 ($16 \to 77$), 그리고 학습에 참여하는 모듈이 많을수록 재구성된 이미지의 품질(FID)과 캡션의 성능이 점진적으로 향상
- 이는 더 많은 파라미터를 최적화할수록 더 세밀한 정보를 학습할 수 있음을 의미
2. 확장성 분석 (Scalability Analysis)
데이터 양과 모델 크기를 늘렸을 때 성능이 계속 좋아지는지(Scaling Law)를 확인
- 실험 변수
- 데이터 규모: 학습 이미지를 600만(6M) $\rightarrow$ 1,800만(18M) $\rightarrow$ 4,000만(40M) 장으로 확장.
- 디코더 크기: 캡션 생성 모델(Qwen-2.5)의 크기를 0.5B $\rightarrow$ 1.5B $\rightarrow$ 3B 파라미터로 확장.

- 결과
- 데이터: 학습 이미지가 늘어날수록 FID 수치가 낮아지며(좋아지며) 성능이 뚜렷하게 개선
- 모델: 캡션 디코더가 클수록 성능이 예측 가능하게 향상
- 결론: VLV 프레임워크는 더 많은 데이터와 더 큰 모델을 투입하면 성능이 비례해서 오르는 강력한 확장성(Scalability)을 가지고 있음이 입증
Emergent Properties
1. Representation Learning beyond Text: 3D Visual Awareness
캡션 임베딩이 확장 가능한(scalable) 공간 인식 능력을 가지고 있음을 발견
- 실험 방법
- Gemini 2.0 Flash를 사용하여 원본 이미지 내 주요 객체들의 3D 바운딩 박스를 복원
- 캡션 임베딩으로 재구성된 이미지의 바운딩 박스와 L1 distance deviation을 측정
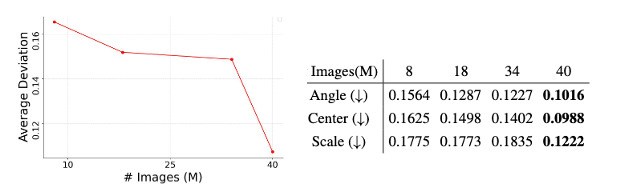
- 정량적 평가: pose estimation 오류가 일관되게 감소

- 정성적 평가
- 원본 이미지(왼쪽) vs 임베딩을 통해 재구성된 이미지(오른쪽)
- VLV Autoencoder 방법이 공간 구조를 포착하는 능력을 보유하게 함
2 Compositionality with Multi-image Semantics
서로 다른 두 이미지의 특징을 섞어서 새로운 이미지를 만들 수 있는지(스타일 전이 등)를 실험
- 실험 방법
- 두 개의 서로 다른 이미지(예: 고양이 사진 + 반 고흐 그림)에서 각각 임베딩을 추출.
- 이 벡터들을 잘라내어 이어 붙인(Concatenate) 후, 추가 학습이나 텍스트 프롬프트 없이 이미지 생성기에 입력.

결과
- Style Transfer
- [시베리아 고양이] + [반 고흐 그림] $\rightarrow$ 고양이의 위치와 자세는 유지한 채 반 고흐 화풍이 입혀진 고양이 생성.
- [시바견] + [캐릭터] $\rightarrow$ 시바견 + 캐릭터 생성
- 가상 착용 (Virtual Try-on)
- [시바견/남자] + [후드티/선글라스] $\rightarrow$ 시바견/남자가 해당 아이템을 착용한 모습 생성.
- 객체 합성
- [고양이] + [후지산] $\rightarrow$ 후지산 앞에 있는 고양이 생성.
- Style Transfer
Conclusion
Vision-Language-Vision Auto-Encoder (VLV AE)는 사전 학습된 시각 및 언어 모델들의 지식을 효과적으로 활용하여 초저비용으로 최첨단 수준의 이미지 캡션너를 구현한 혁신적인 접근법이다.
이미지→텍스트 생성을 위한 중간 representation으로 연속형 embedding을 도입하고, 텍스트-투-이미지 diffusion model을 AutoEncoder 디코더로 활용함으로써 정보 병목을 형성한 아이디어가 주효했다.
이를 통해 VLV는 대규모 병렬 데이터 없이도 고해상도 시맨틱 embedding을 학습하였고, 최종적으로 GPT-4 수준의 상세한 캡션 생성을 달성하였다.
실험 결과 VLV의 캡션 품질은 정량적·정성적으로 모두 기존 공개 모델을 앞서거나 동등했으며, 특히 공간적 상세 묘사와 일관성 측면에서 우수함이 확인되었다.
또한 하나의 embedding으로 이미지와 텍스트를 모두 생성하는 등 멀티모달 통합 representation으로서의 가능성도 보여주었다.
결론적으로, VLV는 멀티모달 AI에서 knowledge distillation와 모듈 재사용을 통해 효율성과 성능을 모두 잡은 모범적인 사례로 볼 수 있다.
Limitations
이미지 인코더, diffusion model, LLM 등 세 가지 거대 사전 모델에 크게 의존
비록 모두 동결 또는 일부만 fine-tuning하여 효율성을 얻었지만, 기본 성능은 여전히 이러한 기성 모델들의 품질에 좌우된다.
예를 들어 Diffusion 디코더가 학습되지 않으므로, 해당 모델이 잘 못 생성하는 종류의 시각 정보(예: 이미지 속 글자 인식 등)는 embedding에도 반영
향후에는 diffusion model 자체를 개선하거나, 추가 모듈을 통해 이 한계를 보완
제한된 downstream 활용: Image captioning에 특화
연속 embedding이 시맨틱한 정보는 담고 있으나, 이를 활용한 다른 작업(예: VQA, 이미지 검색 등)에 직접 응용되지는 않음
따라서 해당 embedding의 범용성을 입증하려면 추가 연구가 필요
또한 캡션 내용이 매우 장황하고 상세하기 때문에, 실제 응용에서 간결한 요약이나 특정 질문에 대한 대답 등으로 조정하는 것도 task로 남는다
훈련 데이터 품질
- 2단계 학습을 위해 사용한 600만 개 캡션은 인간 대신 대형 언어 모델이 생성한 것
- 이로 인해 생길 수 있는 편향이나 사실성 문제가 존재
- 예를 들어 Gemini 2.0 Flash가 특정 스타일이나 관점을 가미해서 캡션을 달았다면, VLV도 그 영향을 받음
- 미래에는 인간 검수 데이터나 다양한 스타일의 캡션 데이터를 추가하여 편향을 줄이고 일반화 성능을 높일 필요
- 2단계 학습을 위해 사용한 600만 개 캡션은 인간 대신 대형 언어 모델이 생성한 것
SOTA와의 격차
- VLV는 GPT-4 등과 거의 대등한 성능을 보였지만 아직 완전히 추월 X
- FID 기준으로 소폭이지만 Gemini 2.0 Flash가 더 나은 점수였고, 일부 매우 복잡한 장면에서 GPT-4가 더 나은 언어 representation을 보임
- 추후 연구에서는 VLV embedding 공간을 더 확장하거나, LLM 디코더를 한층 고도화하여 최고 성능 격차를 좁히는 방향으로 발전
- VLV는 GPT-4 등과 거의 대등한 성능을 보였지만 아직 완전히 추월 X