[Paper Review] Do Vision Transformers See Like Convolutional Neural Networks?
[논문 리뷰] Do Vision Transformers See Like Convolutional Neural Networks?
Do Vision Transformers See Like Convolutional Neural Networks?
Maithra Raghu, Thomas Unterthiner, Simon Kornblith, Chiyuan Zhang, Alexey Dosovitskiy
NeurIPS 2021
[Arxiv]
이 논문은 ViT와 CNN의 내부 표현 구조를 비교 분석하여, 두 아키텍처가 시각 정보를 처리하고 표현하는 방식의 차이를 정량적으로 규명하고자 한다.
0. Background
Convolutional Neural Network (CNN)
CNN은 이미지 처리에 특화된 인공신경망으로, Convolution layer을 사용하여 지역적인 feature을 추출한다. Convolution 연산은 local적인 receptive field 내에서 가중치를 공유하며, 이는 공간적 변환에 대한 equivariance(등변성)을 제공한다.
이러한 강력한 귀납적 바이어스(inductive bias) 덕분에 CNN은 시각적 패턴(에지, 모서리 등)을 효율적으로 학습하며, 다양한 시각 과제에서 뛰어난 성능을 보여왔다.
깊은 CNN 구조에서는 layer이 깊어질수록 receptive field가 점차 확대되어, 하위 layer은 local feature를, 상위 layer은 보다 global한 feature를 포착한다.
Vision Transformer (ViT)
ViT는 Transformer 모델을 이미지에 적용한 것으로, 본래 자연어 처리에서 쓰이는 Transformer 구조를 거의 그대로 사용한다.
이미지를 여러 patch(patch)로 분할하여 각각을 하나의 입력 token으로 취급하고, 추가로 전체 이미지를 대표하는 $\text{[CLS]}$ token을 함께 모델에 입력한다. 각 token에는 위치 정보를 보강하기 위한 positional 인코딩이 더해진다.
ViT의 핵심 연산은 self-attention 메커니즘으로, 모든 token 쌍 사이의 관계를 학습하여 정보의 가중 합산을 수행한다. multi-head attention를 통해 서로 다른 종류의 관계를 병렬로 학습하며, 이를 통해 모델은 전 layer에서 global적인 정보를 통합할 수 있다.
CNN과 달리 ViT는 구조 자체에 local성에 대한 제약이 없으며, 충분한 데이터와 연산 자원이 주어지면 Convolution 없이도 시각 과제를 성공적으로 학습할 수 있음이 알려졌다 .
Self-Attention
Self-attention은 입력 token들의 쌍마다 유사도 점수를 계산하여, 각 token이 다른 token을 얼마나 참고할지 결정하는 방법이다.
구체적으로, 각 token으로부터 쿼리(query), 키(key), 값(value) 벡터를 생성하고 쿼리-키 간 내적 유사도를 산출한 뒤 softmax를 통해 가중치를 얻는다.
이 가중치로 모든 값 벡터의 가중 합을 계산하면, 해당 token에 대한 attention 출력이 된다. 이런 과정을 모든 attention 헤드에서 거치면, 모델은 전 공간에 걸쳐 정보를 결합한 새로운 token 표현을 산출한다. 이처럼 self-attention은 첫 층부터 global 범위의 의사소통이 가능하나, 반대로 CNN처럼 지역 구조에 대한 명시적 바이어스는 없다. 따라서 ViT는 대규모 데이터로 학습하지 않으면 초반에 유의미한 local feature를 배우지 못할 수 있다는 점이 지적되어 왔다.
Receptive Field와 Residual Connection
Receptive field는 신경망의 한 뉴런(또는 출력 위치)에 영향을 미치는 입력의 영역을 뜻한다.
CNN에서는 Convolution 커널 크기와 layer 깊이에 의해 receptive field가 계단식으로 확대된다.
반면 ViT에서는 self-attention으로 인해 receptive field가 이론적으로 무한대(입력 전체)로 시작하지만, residual 연결의 존재와 학습 데이터 특성에 따라 실질적 receptive field (effective receptive field)는 결정된다.
Residual connection은 입력을 변환(output)과 더하는 지름길 경로로, ResNet에서 처음 도입되었다.
기울기 소실을 줄이고 훈련을 용이하게 할 뿐만 아니라, 하위 layer의 표현을 상위 layer에 직접 전달하는 통로 역할도 한다. Transformer 및 ViT에서도 모든 self-attention 및 MLP 층 뒤에 skip connection이 존재하며, 이는 모델의 표현 구조와 학습 동작에 큰 영향을 준다.
1. Introduction
CNN은 지난 수년간 Computer vision 분야의 표준 모델 역할을 해왔다.
특히 Convolution 연산이 제공하는 공간적 불변성 등의 특성으로, 대규모 이미지 데이터셋에서 robust한 표현 학습과 Transfer learning의 효과적인 토대를 마련했다.
하지만 최근 ViT의 등장은 이러한 통념에 도전하고 있다.Transformer 기반 ViT 모델이 대용량 데이터에서 학습될 경우 이미지 분류 성능이 CNN에 필적하거나 그 이상일 수 있음이 확인되었다.
흥미롭게도 ViT는 Convolution이나 Pooling을 사용하지 않고도 높은 성능을 보여주는데, 이는 곧 “ViT는 시각 과제를 CNN과 같은 방식으로 풀고 있는가?”라는 근본적인 의문을 불러일으킨다.
다시 말해, ViT가 높은 성능을 내는 이유가 CNN과 유사한 표현을 우연히 학습한 것인지, 아니면 전혀 다른 표현 전략을 채택한 것인지를 밝혀볼 필요가 있다.
또한 데이터 규모(scale)는 이러한 표현 학습에 어떤 영향을 주며, ViT와 CNN의 차이가 downstream task(예: 물체 검출, Transfer learning 등)에서는 어떤 의미를 가지는지도 중요한 질문이다.
본 논문에서는 이러한 질문들에 답하기 위해, ViT와 CNN 내부의 표현 구조를 다양한 측면에서 면밀히 분석하였다. 저자들은 모델의 layer 표현을 비교하는 여러 기법을 통해 두 아키텍처 사이의 뚜렷한 차이점을 발견하였으며, 그러한 차이가 발생하는 원인을 실험적으로 규명하고자 하였다. 특히 self-attention 메커니즘과 skip connection이 표현 형성에 미치는 영향, 공간적 정보 보존능력의 차이, 그리고 학습 데이터 규모에 따른 표현 및 전이 성능 변화를 집중적으로 다루었다. 마지막으로, 이러한 발견을 토대로 최근 제안된 MLP-Mixer 등 새로운 비Convolution 모델과의 관련성을 논의하면서 결론을 맺는다 .
Goal
이 논문의 목표는 “ViT가 시각적 입력을 처리하는 방식이 CNN과 어떻게 다른가?”를 체계적으로 밝히는 것이다.
Motivation
ViT의 성공이 기존 CNN의 inductive bias 없이도 가능함을 보여주었다는 점에서 출발한다.
따라서 ViT 내부의 표현이 CNN과 유사한지, 아니면 Transformer만의 독자적 표현을 형성하는지 알아내는 것은 딥러닝 모델의 표현 한계와 가능성을 이해하는 데 중요하다.
저자들은 이러한 탐구를 통해 ViT와 CNN의 작동 원리를 깊이 있게 비교하고, 나아가 더 나은 모델 설계 지침을 얻고자 했다.
Contribution
논문의 핵심 기여는 다음과 같이 요약된다.
내부 표현 구조 비교:
ViT는 모든 layer에 걸쳐 Representation Similarity가 높게 유지되는 균일한 구조를 보이는 반면, ResNet 등 CNN은 layer 간 유사도가 단계별로 뚜렷이 구획화되어있음
layer Representation Similarity가 스테이지(stage) 단위로 뭉쳐 보인다는 것
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
ResNet (단계적 블록 구조) [■■■········] [■■■········] [■■■········] [···■■■■····] [···■■■■····] [···■■■■····] [······■■■■■] [······■■■■■] [······■■■■■] ViT (전층 비교적 균일) [■■■■■■■■■] [■■■■■■■■■] [■■■■■■■■■] [■■■■■■■■■] [■■■■■■■■■] [■■■■■■■■■] [■■■■■■■■■] [■■■■■■■■■] [■■■■■■■■■]
ViT의 하위 layer과 상위 layer이 매우 유사한 표현을 공유하지만, CNN은 저차원 feature↔고차원 feature 간 유사성이 훨씬 낮고 layer별로 구분된 스테이지(stage) 특성을 나타낸다 .
local vs global 정보 활용
ViT는 초기 layer부터 global 정보를 통합하여 표현을 형성
- 고정된 local receptive field를 갖는 CNN과의 중요한 차이점
ViT의 하위 self-attention layer에서는 local head과 global head가 혼재되어, local과 global 정보를 모두 활용하는 반면, CNN 하위 layer은 설계상 local 정보만 처리
이러한 global 정보 접근은 학습된 feature의 성질에도 차이를 만들어, CNN이 학습한 local feature과 ViT의 global feature 간에는 정량적 차이가 존재함을 보임
하지만, 충분한 데이터가 없으면 ViT의 하위 layer이 local 정보를 제대로 학습하지 못해 성능이 저하
→이는 CNN에서 암묵적으로 주어지는 local inductive bias의 중요성을 방증
Skip Connection의 역할
ViT에서는 skip connection을 통해 하위 layer의 표현이 상위 layer으로 강하게 전달
layer 간 Representation Similarity가 전반적으로 높게 유지되는 것으로 나타났다.
구체적으로 ViT에서는 네트워크 전반에 걸쳐 skip connection의 기여도가 CNN보다 훨씬 큼
특히 네트워크 전반부에는 $\text{[CLS]}$ token을, 후반부에는 공간 token을 주로 skip 연결이 운반하는 phase transition 현상이 관찰
ViT에서 특정 layer의 skip connection을 제거하면 해당 지점 전후로 Representation Similarity가 급격히 단절되고 성능 하락
공간 정보 보존 및 위치 특이성
ViT는 최종 layer까지도 입력 patch의 공간적 position 정보를 상당 부분 보존
ViT의 각 token은 대체로 해당 입력 위치에 특화된 표현을 지니며, 특히 내부 영역 token은 그 위치의 이미지 patch와 높은 유사도
ResNet의 경우 최종 feature map의 한 위치에 해당하는 표현이 특정 입력 위치에 대응되지 않고 여러 위치에 고루 유사한 양상을 보임
이는 global average pooling(GAP)으로 인해 공간 정보가 혼합되었기 때문으로 해석
데이터 규모와 Transfer learning
- 대규모 데이터세트로 pretraining한 ViT는 우수한 중간 표현을 학습하며, 이는 작은 데이터로 학습한 모델과 큰 차이를 보임
- 데이터 규모와 모델 크기는 ViT의 representation 학습에 매우 중요하며, 대규모 사전학습으로 얻은 ViT 표현은 transfer learning 측면에서 CNN보다 유리한 feature을 지님
2. Background and Experimental Setup
비교 분석을 위한 대표적인 CNN과 ViT 모델을 다음과 같이 선정한다.
- CNN
- ResNet-50x1 (표준 크기)
- ResNet-152x2 (레이어를 늘리고 폭을 2배로 확장한 모델)
- ViT
- ViT-B/32
- ViT-B/16
- ViT-L/16
- ViT-H/14
모델들은 별도 언급이 없는 한 JFT-300M 데이터셋으로 사전학습되었다.
JFT-300M은 약 3억 장의 이미지로 이루어진 구글 내부의 매우 큰 데이터셋으로, ViT 논문에서 높은 성능을 달성하는 데 활용되었다.
추가로, 저자들은 ImageNet ILSVRC 2012 데이터셋으로 학습된 모델들도 실험에 포함시켜 데이터 규모 변화에 따른 효과를 관찰했으며, 학습된 표현의 Transfer learning 성능을 평가하기 위해 표준적인 벤치마크 (예: CIFAR-10/100 등)에도 모델을 적용한다.
Representation Similarity and CKA
신경망 representation을 layer적으로 분석하려면, 각 layer의 활성화 패턴(feature맵 또는 임베딩)이 다른 layer이나 다른 모델의 것과 얼마나 유사한지를 측정할 수 있어야 한다.
하지만 신경망 표현은 다차원 공간에 분산되어 있어 단순 비교가 어렵고, 특히 두 모델 간 표현 비교는 뉴런의 순서나 스케일 차이 등으로 의미있는 유사도 측정이 곤란하다.
Centered Kernel Alignment (CKA)는 이러한 문제를 해결하기 위해 제안된 대표적인 Representation Similarity 측정 기법이다.
두 layer (또는 모델)에서 같은 입력 데이터에 대해 추출된 feature 행렬 $X$, $Y$가 주어지면, CKA는 각 feature 행렬로부터 Gram 행렬(내적 유사도 행렬) $K = X·X^T, L = Y·Y^T$를 계산한 뒤 두 Gram 행렬 간의 비교 지표를 산출한다.
구체적으로는 Hilbert-Schmidt Independence Criterion(HSIC)을 활용하여, 두 Gram 행렬의 공분산을 정규화한 값으로 유사도를 정의한다 . 수식으로 나타내면 다음과 같다:
$\text{CKA}(X, Y) = \frac{\text{HSIC}(K, L)}{\sqrt{\text{HSIC}(K, K)\,\text{HSIC}(L, L)}}.$
CKA의 중요한 성질은 표현 공간의 직교 변환이나 스케일링에 대해 불변이라는 점이다 .
CKA는 좌표값 자체가 아니라 표본들 간의 상대적 관계(내적/유사도 구조)를 비교한다.
- 직교 변환은 내적을 보존하므로 “점들 사이 각도/거리 구조”가 그대로여서 CKA가 변하지 않는다.
- 등방 스케일은 모든 내적을 같은 비율로 키울 뿐이므로, 정규화(분자/분모)에서 그 비율이 소거된다.
예를 들어 한 layer의 뉴런 순서를 섞거나 활성값에 일정 배율을 곱해도 CKA 유사도 값은 변하지 않는다. 덕분에 서로 다른 아키텍처 사이에서도 Representation Similarity를 공정하게 비교할 수 있다.
본 연구에서는 대용량 데이터와 많은 layer을 다루기 위해, 데이터셋에서 mini-batch를 샘플링하여 Gram 행렬의 HSIC를 근사하는 방법으로 CKA를 효율적으로 계산하였다.
이를 통해, 논문에서는 단일 모델 내 layer들 사이, 모델 간 layer들 사이의 Representation Similarity를 체계적으로 비교하였다.
3. Representation Structure of ViTs and Convolutional Networks
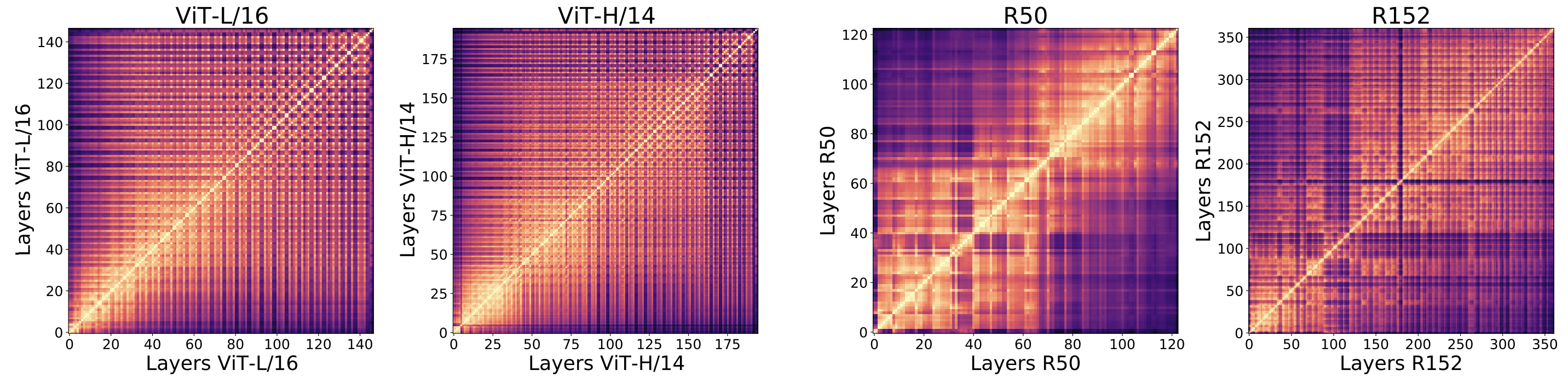 ViT와 ResNet의 내부 표현 구조의 CKA를 heatmap으로 시각화한 결과.
ViT와 ResNet의 내부 표현 구조의 CKA를 heatmap으로 시각화한 결과.
x축과 y축은 모델의 layer을 입력→출력 순서로 나타내며, 히트맵의 각 셀 색깔은 해당 두 layer 간 CKA 유사도 값을 표현한다.
- ViT
- ViT의 경우 전 구간에 걸쳐 격자 무늬의 균일한 패턴이 나타나며, 이는 낮은 layer과 높은 layer 모두 상당히 비슷한 표현을 공유하고 있다는 것을 의미
- 대각선을 따라 밝은색(자기 자신과의 유사도 100%)이 보이고, 그 주변으로도 전반적으로 높은 유사도 영역이 넓게 분포하여 layer 간 경계가 흐릿한 모습을 관찰할 수 있다.
- 다시 말해 ViT에서는 초기 특성들이 상위 layer까지 계속 전달되면서 일관된 표현 구조가 형성
ResNet
layer별 Representation Similarity가 뚜렷하게 단계적으로 구분되는 양상
히트맵에서 밝은색의 블록 무늬들이 layer을 따라 몇 구간으로 나누어져 있음
ResNet이 스테이지라 불리는 layer 그룹 단위로 유사한 표현을 형성
- 초기 Convolution layer들 사이, 중간 layer들 사이, 최종부 layer들 사이에는 각각 높은 유사도
- 초기 vs 최종 layer처럼 멀리 떨어진 layer끼리는 유사도가 매우 낮음
layer이 깊어지면서 feature 표현을 점진적으로 변화시켜, 낮은 층의 low-level (에지, 질감 등)과 높은 층의 high-level feature(객체 개념 등)이 확연히 구별됨을 의미
이처럼 동일 모델 내에서 ViT와 CNN의 표현 구조는 크게 대조된다.
그렇다면 서로 다른 모델 간에는 어떤 대응관계가 있을까?
저자들은 한 모델의 모든 layer과 다른 모델의 모든 layer 사이의 CKA를 계산하여 교차 모델 Representation Similarity를 분석하였다.
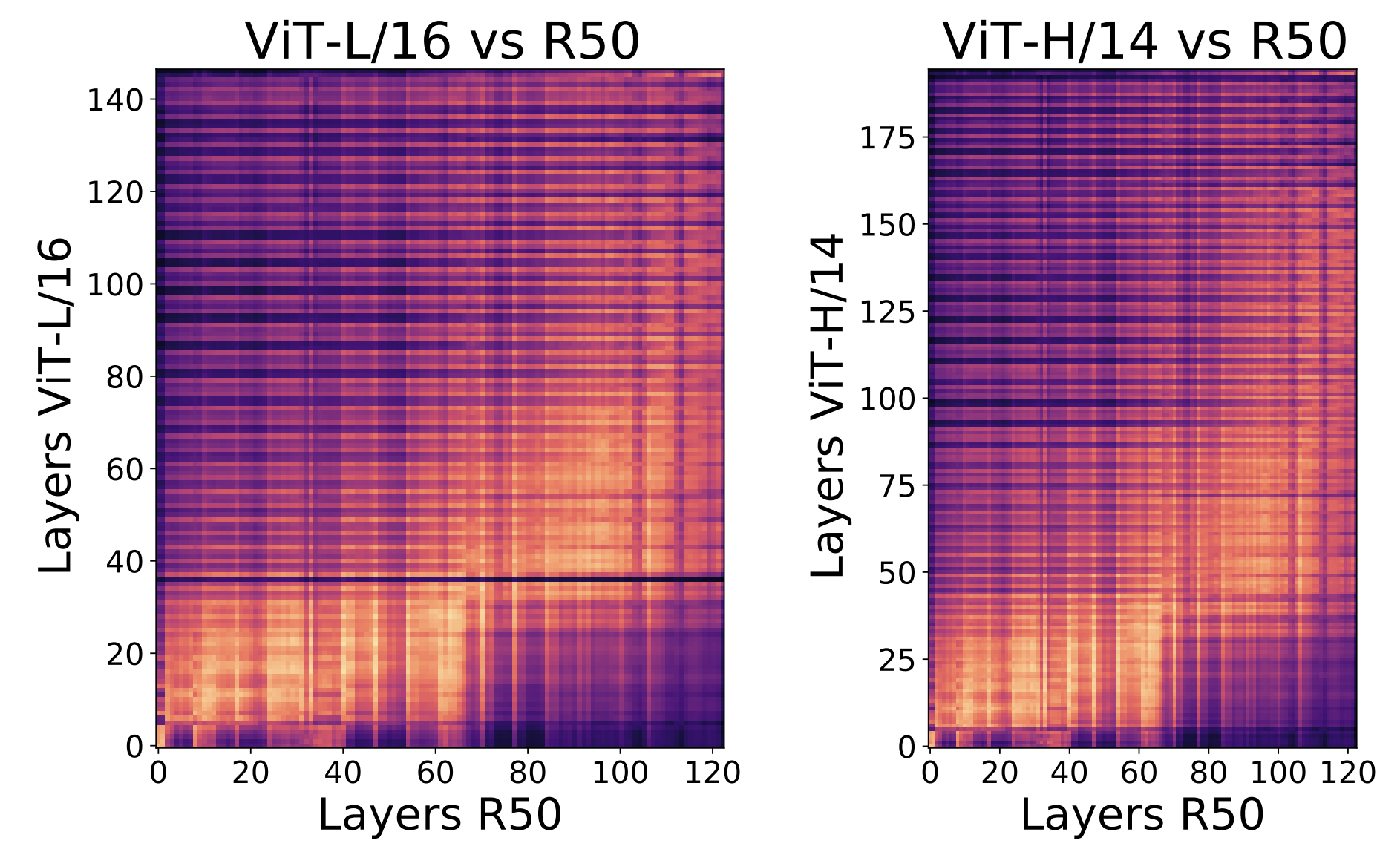
- ResNet의 하위 절반 layer들의 표현이 ViT의 극초기 몇 개 layer의 표현과 유사도가 높음
- ResNet의 상위 절반 layer은 ViT의 그 다음 1/3 정도 layer과 유사도가 높음
- ViT의 최상위 layer들(마지막 약 1/3)은 ResNet 어느 layer과도 뚜렷한 유사도를 보이지 않음
- 이는 ViT 최종부의 표현인 $\text{[CLS]}$ token 관련 표현이 CNN의 어떤 layer 표현과도 상이함을 시사
위 발견들은 다음을 시사한다.
- ViT의 초기 layer 표현은 ResNet의 초기보다 상당히 다른 방식으로 이루어진다.
- ResNet 여러 layer이 쌓여야 얻는 표현을 ViT는 불과 몇 layer만에 달성하거나, 전혀 다른 feature을 형성
- ViT는 하위 layer의 표현을 상위 layer까지 강하게 전달하여, 낮은 층과 높은 층 간 Representation Similarity가 크다.
- 반면 ResNet은 layer별로 표현 변화가 커 하위/상위 간 유사도가 낮다.
- ViT의 최상위 layer 표현은 ResNet과 판이하게 다르다.
- ViT의 마지막 layer들이 주로 분류 token(CLS)에 집중하여 학습
- ResNet은 global 평균 Pooling으로 혼합된 feature을 가지기 때문으로 추정
왜 다른 아키텍쳐사이에 CKA 비교가 의미가 있을까?
서로 다른 아키텍처 사이에 CKA를 쓰는의미
무엇을 비교하나?
각 layer 표현으로부터 샘플-샘플 유사도 행렬(Gram)을 만든 뒤, 두 유사도 행렬이 같은 무늬를 가지는지(같은 샘플 쌍이 둘 다 비슷하거나 둘 다 다르게 보이는지)를 정규화해 측정한다.
→ 두 표현이 클래스/이미지 집합을 어떻게 ‘배치’하는지가 비슷하면 CKA가 높아진다.
왜 공정한가?
CKA는 (선형 CKA 기준) 직교 기저변환(회전/반사)과 등방 스케일링에 불변이다. 또 Gram을 쓰므로 차원 수가 달라도 비교 가능하다.
→ 뉴런 순서, 채널 재배열, 단위 스케일 차이 같은 표면적 차이를 걷어내고 표현의 관계 구조만 본다.
무엇을 말해주나?
“두 layer가 같은 입력들 사이의 상대적 유사·비유사 구조를 비슷하게 인코딩한다”는 증거를 제공한다. 이는 “분류 경계가 비슷한 위치에 놓일 개연성”, “같은 군집/축(salient factors)을 분리한다”는 표현 수준의 정합을 시사
</details>
요약하면, ViT와 CNN은 내부 표현 형성 방식에서 근본적 차이가 있으며, ViT는 CNN보다 표현의 layer 간 일관성이 높고 global적 feature 통합을 더 일찍 수행하는 반면, CNN은 layer별로 점진적인 feature 추출과 local→global 단계적 진행이 두드러진다 .
이러한 초기 관찰 결과는, 뒤이어 자세히 살펴볼 self-attention의 역할, skip connection에 의한 특성 전달, 공간 정보 보존 여부 등이 이러한 차이에 어떻게 기여하는지를 탐구하도록 동기를 부여한다.
4. Local and Global Information in Layer Representations
앞선 결과에서 ViT와 CNN의 하위 layer 표현이 상당히 다르며, 특히 ViT는 하위 layer부터 상위 layer과 유사한 표현을 유지함을 보았다.
이러한 차이의 한 가지 원인으로 저자들은 “Global 정보의 조기 활용 여부”에 주목한다.
CNN의 초기 Convolution layer은 고정된 작은 receptive field 때문에 local적 feature만 처리하지만, ViT의 self-attention layer은 멀리 떨어진 이미지 부분도 한 번에 통합할 수 있다.
따라서 ViT 하위 layer은 global 정보까지도 표현에 반영될 가능성이 있다.
이 섹션에서는 ViT의 각 layer이 실제로 얼마나 global 정보를 포함하는지를 분석하고, 그에 따른 표현 특성의 차이를 정량화한다.
또한 ViT가 충분한 데이터로 학습되지 않을 경우 global/local 정보 활용이 어떻게 달라지는지 관찰함으로써, 데이터 규모와 표현 학습의 관계도 함께 고찰한다 .
핵심적으로, self-attention의 spatial한 범위와 CNN의 local receptive field의 대비를 통해, 표현 형성의 지역성 vs global성에 따른 차이를 밝히고자 한다.
4-1. Analyzing Attention Distances
ViT의 self-attention 구조는 여러 head로 구성되어 있고, 각 헤드는 입력 token들의 특정 거리 범위에 집중하여 정보를 모을 수 있다.
이를 정량화하기 위해, 저자들은 attention 헤드 별로 주목하는 거리를 계산하는 분석을 수행한다. 방법은 다음과 같다:
입력 이미지를 patch로 나눌 때 각 patch에 2차원 좌표를 부여
한 attention 헤드에서 쿼리 token이 attention을 할당한 다른 token들의 평균적인 거리를 측정
이 때 거리는 해당 patch들의 이미지 상 유클리드 거리(픽셀 단위)로 정의하고, attention 가중치를 가산하여 가중 평균 거리를 계산
이렇게 하면 각 헤드가 주로 local 정보를 보는지(짧은 거리) 또는 global 정보를 보는지(긴 거리)를 수치화할 수 있다.
모든 헤드에 대해 이 값을 구한 뒤, 낮은 layer vs 높은 layer에서 헤드들의 거리 분포를 비교한다.
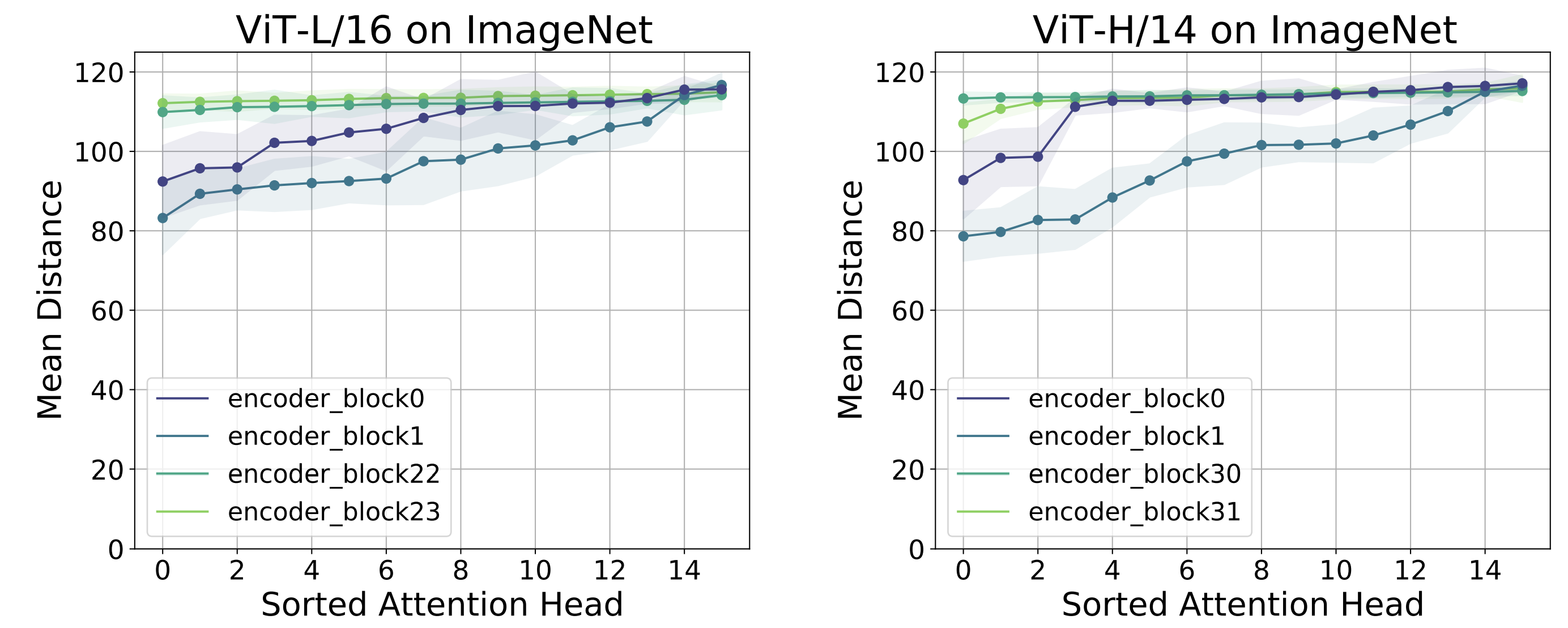
그 결과, ViT의 하위 layer에서는 짧은 거리에 집중하는 local 헤드와 긴 거리를 보는 global 헤드가 혼재되어 있었다.
위 그림에서,
- 최하위 layer의 헤드들 중 일부는 자기 주변 patch들에 주로 attention을 두고(작은 평균거리), 다른 일부는 이미지 전반에 걸쳐 넓게 attention을 두는(큰 평균거리) 패턴이 동시에 존재
- 이는 Dosovitskiy 등 ViT 논문에서 보고된 “저층에서도 지역/global 정보를 모두 활용한다”는 관찰과 일치
- 높은 layer으로 갈수록 모든 헤드의 평균 거리가 크게 나타났는데, 이는 상위 layer일수록 오직 global적인 정보만을 통합하고 있음을 시사
즉, ViT는 초기부터 local+global 혼합 -> 후반에는 global 위주의 attention 양상을 보인다.
이에 비해 CNN의 Convolution은 구조적으로 첫 layer에서는 local 이외의 정보를 볼 수 없으므로, 이러한 헤드 다양성이 존재하지 않는다.
CNN은 layer을 거듭하며 receptive field가 커질 때에야 비로소 global 정보를 다루게 되지만, ViT는 애초에 모든 범위를 참조할 수 있는 자유를 갖고 학습하는 것이다.
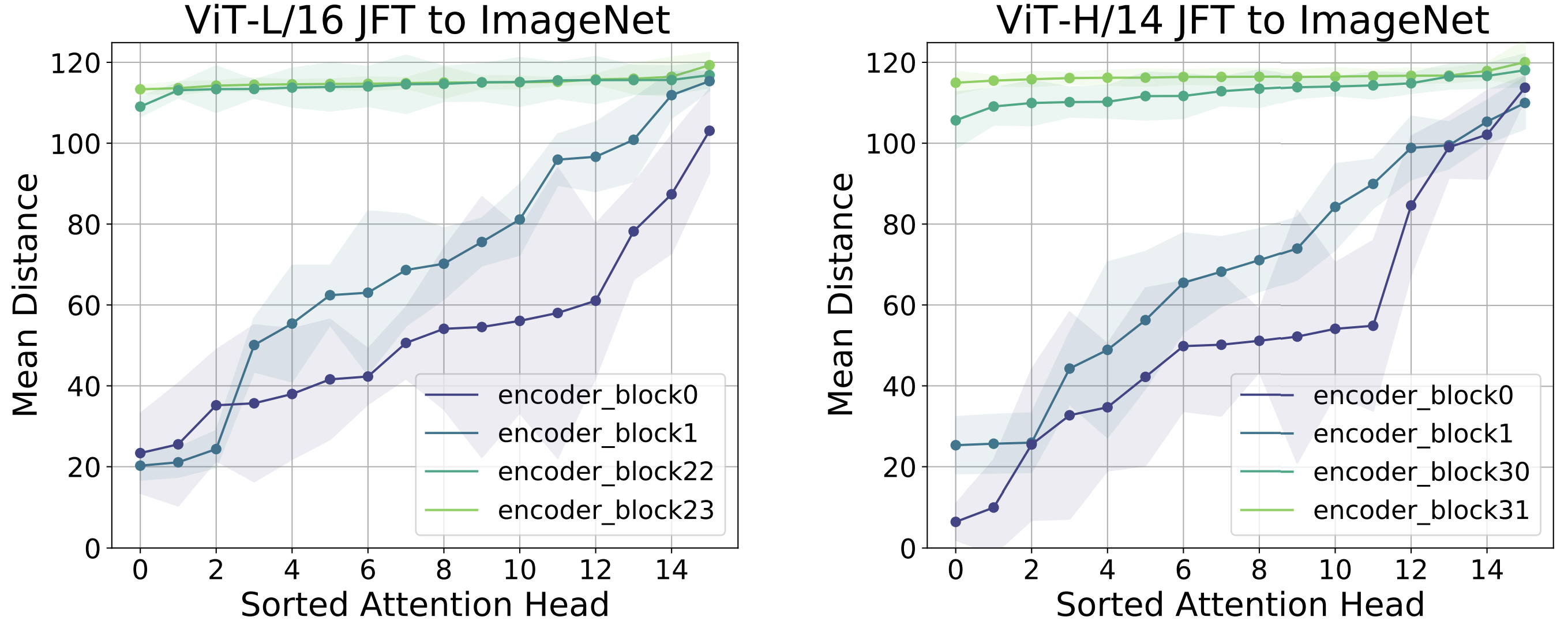
또한, 학습 데이터의 규모가 ViT의 attention 패턴에 영향을 준다. 저자들은 대규모 사전학습 없이 ImageNet 정도의 데이터만으로 학습한 ViT 모델을 분석해 본다.
결과적으로는 ViT의 하위 layer 헤드들이 local적 attention을 거의 배우지 못하고, 대부분이 global적인 attention에 치우치는 경향을 보인다.
위 그림은 ImageNet만으로 학습한 ViT-L/16, H/14 모델의 헤드 평균거리를 보여준다.
충분한 데이터가 없으면 낮은 layer 헤드들도 큰 거리만 주목하고 있음을 확인할 수 있음
ViT가 local feature의 중요성을 자체적으로 학습하기 위해서는 방대한 데이터가 필요하며, 데이터가 부족하면 쉽게 global적 패턴에 과도하게 의존하게 됨을 시사
실제로 이러한 모델들은 JFT-300M으로 학습한 경우보다 분류 성능이 크게 떨어지는데, 초기 layer에서 local 정보를 활용하는 능력이 부족한 것이 성능 부진의 원인으로 추정된다.
결국 이미지 작업에서 local 정보의 활용은 여전히 매우 중요하며, CNN은 구조적으로 이를 보장하지만 ViT는 충분한 데이터를 통해 이를 학습해야만 획득할 수 있다는 점을 확인할 수 있었다 .
4-2. Does access to global information result in different features?
ViT가 초기부터 global 정보를 통합한다는 사실이 밝혀졌다.
그렇다면 이러한 global 정보 활용이 실제 학습 feature의 내용에도 차이를 만들어내는가? 라는 질문이 이어진다.
다시 말해, ViT의 global attention 헤드들이 만들어낸 표현과 CNN의 local Convolution이 만든 표현은 정량적으로 얼마나 다른지 알아보고자 한다. 이를 위해 저자들은 개입적 실험(interventional test)을 수행한다.
ViT의 가장 하위 Encoder 블록에서, 여러 attention 헤드들 중 일부만 선택하여 표현을 구성하고 그 유사도를 ResNet 표현과 비교한다.
구체적으로, ViT-B/16의 1번째 블록에서 가장 local적인 헤드들만의 출력, 중간 정도 거리 헤드들의 출력, 가장 global적인 헤드들의 출력을 각각 분리하여 만든다.
이렇게 얻은 표현 부분집합들은 “ViT가 초기에 local 정보만 활용한 경우부터 global 정보까지 활용한 경우”를 가정한 시나리오로 볼 수 있다.
그런 다음, 이 부분집합 표현들과 ResNet의 하위 layer 표현 사이의 CKA 유사도를 계산한다.
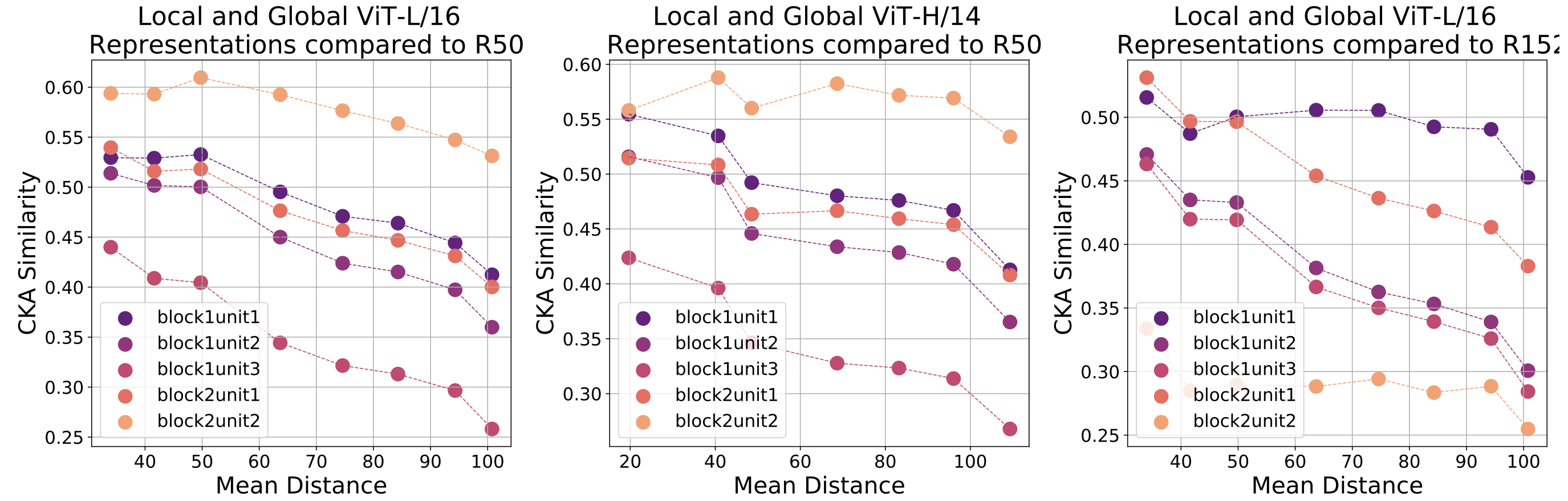
ResNet의 하위 layer 표현은 ViT의 local적 헤드 표현과 가장 비슷했고, 점차 더 많은 global 정보가 포함될수록 유사도가 감소하는 것으로 나타난다.
즉 ViT의 attention 헤드 중 local한 정보만 담은 헤드들의 출력은 ResNet이 추출한 feature과 상당히 유사하지만, global 정보를 더 많이 포함한 헤드들의 출력일수록 ResNet과 거리가 멀어지는 것이다.
Global 정보의 조기 결합이 feature 공간을 질적으로 변화시킴을 시사한다.
ViT가 global attention을 통해 학습한 하위 layer 피처는 ResNet의 local 피처와는 본질적으로 다른 종류임을 정량적으로 보여준 셈
이는 ViT와 CNN 표현 차이의 한 원인이 초기 layer에서 global vs local 정보 활용 여부라는 가설을 뒷받침하는 증거라고 할 수 있다.
4-3. Effective Receptive Fields
ViT와 CNN의 공간 정보 통합 범위 차이를 살펴보는 또 다른 방법으로, 저자들은 layer별 effective receptive field를 측정한다.
effective receptive field란 이론적/최대 범위가 아니라, 실제로 그 layer의 출력이 입력의 어느 부분에 영향을 받고 있는지를 나타내는 개념
방법론적으로는 각 모델에서 특정 layer 출력의 중앙 위치 뉴런을 선택하고, 그 값에 대한 입력 픽셀들의 gradient를 계산하여 절댓값을 취한다. 이 gradient 맵을 시각화하면 입력 이미지 중 어떤 영역이 해당 출력 뉴런에 영향을 미치는지, 그리고 그 세기는 어느 정도인지를 알 수 있다.
이러한 작업을 모든 layer에 대해 수행하면, layer이 깊어짐에 따라 receptive field가 어떻게 변하는지 비교할 수 있다.
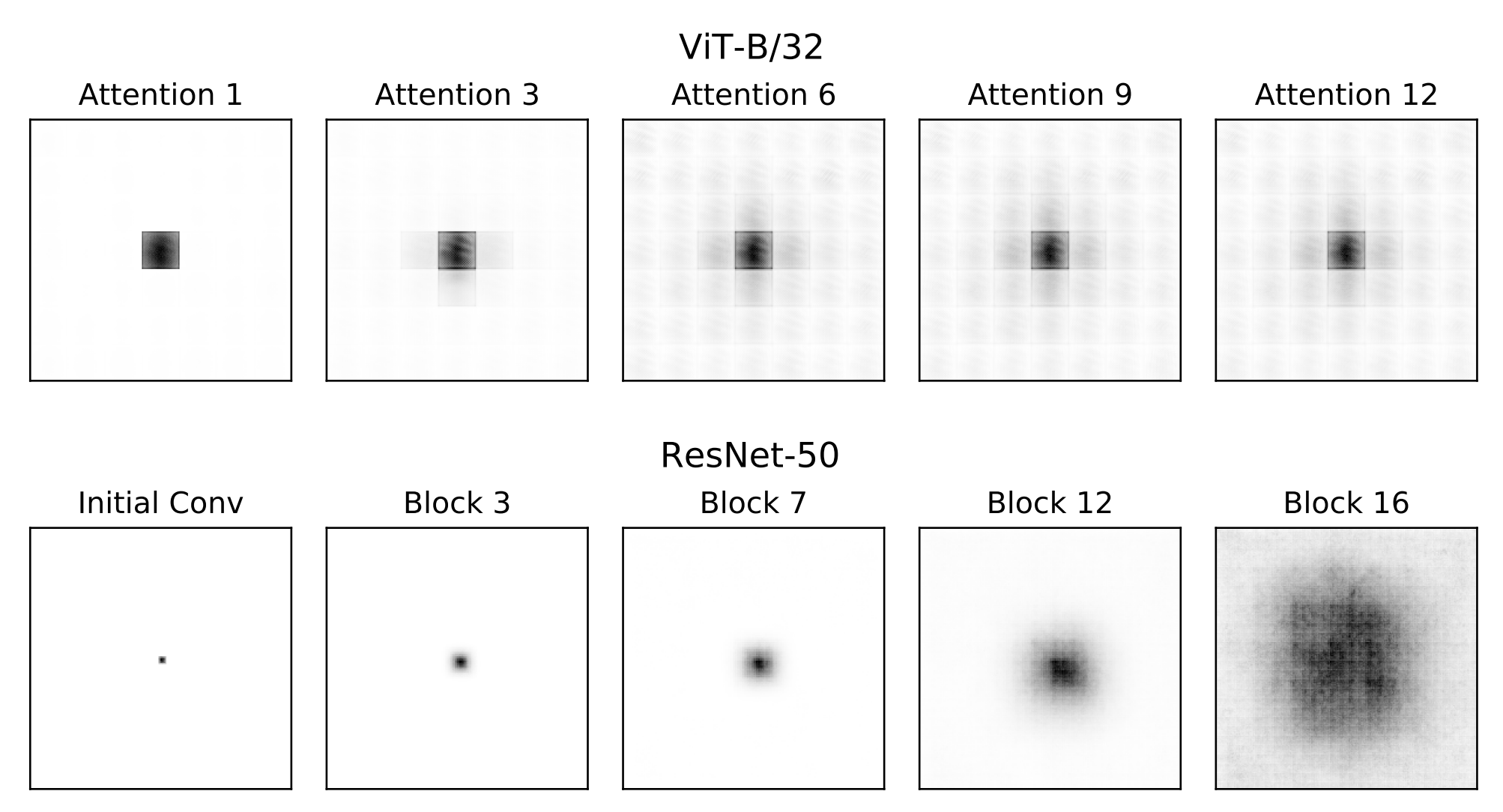
위 그림은 ResNet과 ViT에 대해 이러한 effective receptive field를 계산한 결과를 보여준다.
ResNet
- 하위 layer일수록 receptive field가 매우 국한되어 있고, layer을 거듭할수록 점차 넓어져 상위 layer에서야 이미지 global에 가까워지는 경향
- 이는 Convolution 필터와 Pooling에 의한 직관적 결과로, 처음에는 작은 영역 (예: 7x7 필터 적용 영역)만 영향을 주다가 매 layer 누적되며 조금씩 커진다.
ViT는
낮은 layer부터 이미 ResNet의 같은 수준 layer보다 훨씬 넓은 영역에 반응하고 있었고, 네트워크 중간쯤에서 이미 거의 전체 입력에 대한 dependence를 보임
비교적 적은 layer으로도 global적인 receptive field를 가짐
receptive field가 넓어져도 가장 중심 patch에 대한 영향력이 매우 강하게 유지
중심부 픽셀의 gradient 세기가 주변부보다 압도적으로 크게 나타남
self-attention으로 다른 patch 정보를 얻더라도 자기 자신 patch의 정보를 강하게 보존하는 ViT의 residual connection을 반영
ablation study(부록 c)
- ViT의 attention 층 residual conncetion 전의 출력으로 receptive field를 계산하면 중심 patch 의존성이 훨씬 약해지는데 , Residual 연결을 추가한 후에는 다시 중심 영향력이 강해진다.
이는 ViT의 skip connection이 각 patch의 자기 정보를 상위 layer까지 지속적으로 전달함으로써 생기는 현상으로, 다음 섹션에서 자세히 다룰 표현 전달 메커니즘의 시사점이기도 하다.
정리하면, ViT는 이론적으로 global receptive field를 가지며 실제로도 중~상위 layer에서 입력 global에 고르게 반응한다. 반면 CNN은 설계상 local→global으로 서서히 receptive field를 확장하며, 따라서 표현 형성 과정에서의 지역 대 global 정보 활용 방식이 근본적으로 다르다. 또한 ViT에서 발견된 중심 patch 자기정보의 강한 잔존은 skip connection의 역할을 암시하며, 이는 다음으로 논의될 표현 전파 특성과 연결된다.
5. Representation Propagation through Skip Connections
앞서 ViT와 CNN의 표현 구조를 비교하면서, ViT 내부 표현이 전 layer에 걸쳐 유사도가 높고 균일함을 확인했다. 이러한 현상의 이면에는 skip connection을 통한 표현 전파가 중요한 역할을 하고 있을 것으로 예상된다.
ResNet에서도 Convolution간 skip 연결이 성능 향상과 gradient 흐름에 중요하지만, ViT에서는 skip 연결이 가져오는 표현 유지 효과가 특히 강하다는 것이 앞선 receptive field 결과 등에서 암시되었다 .
이 섹션에서는 ViT와 ResNet에서 skip connection을 통한 표현 전달 양상 차이를 정량적으로 분석한다.
저자들은 먼저 layer별 skip 연결의 기여도를 측정하여, ViT에서는 네트워크 진행 도중 $\text{[CLS]}$ token과 기타 token의 skip 의존성이 뒤바뀌는 현상을 발견한다.
또한 skip 연결을 의도적으로 제거하는 실험을 통해, ViT의 균일한 표현 구조가 skip 연결에 크게 의존함을 확인하한다.
먼저 skip 연결의 기여 비율을 살펴보자.
저자들은 각 layer에서 skip 경로의 출력과 메인 경로(셀프attention/MLP 경로)의 출력의 벡터 norm을 비교한다.
구체적으로, 한 layer의 출력 $h^{(l)}$가 skip 분기를 통해 전달된 입력 $x^{(l)}$와 변환 분기(attention 또는 MLP 연산 결과) $f(x^{(l)})$의 합으로 주어질 때, skip의 기여도를 $\frac{|x^{(l)}|}{|x^{(l)} + f(x^{(l)})|}$로 측정한 것이다. 이 값을 layer $l$에 존재하는 모든 token에 대해 계산하면, 각 token별로 skip 대비 변환의 상대적 비중을 알 수 있다.
아래 그림의 왼쪽 패널은 ViT-B/16 (ImageNet으로 학습) 모델의 layer별 token별 norm 비율을 히트맵으로 나타낸 것이고, 오른쪽 패널은 이를 ResNet50과 비교한 라인 플롯이다 .
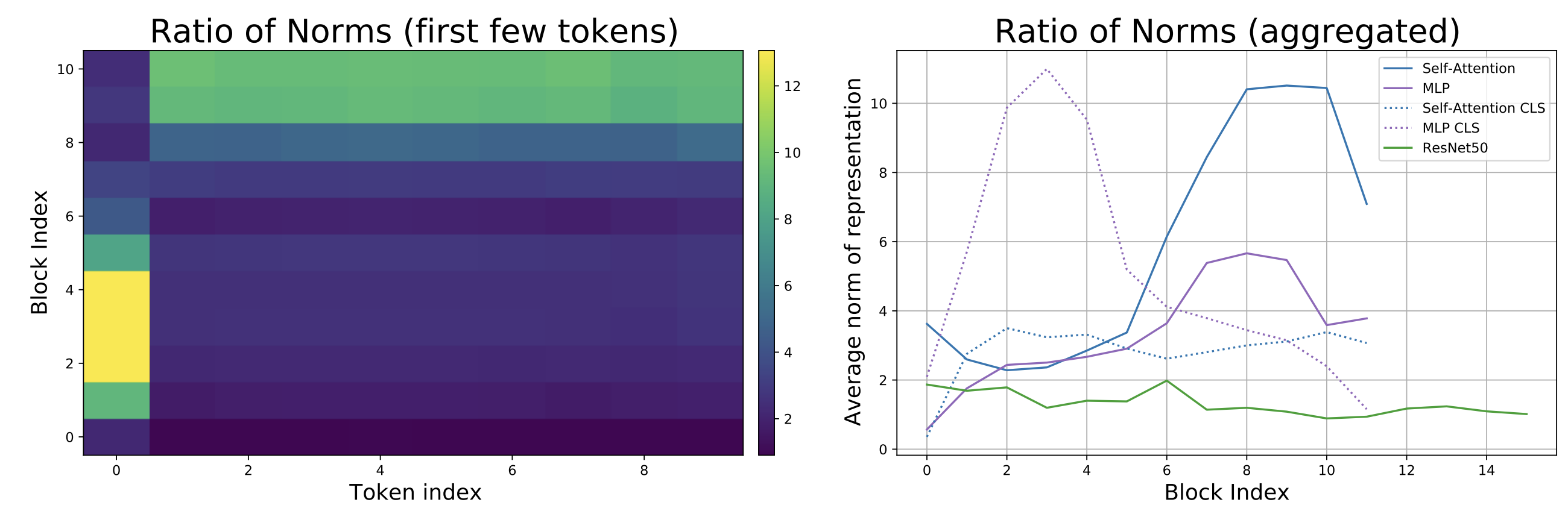
분석 결과, ViT에서는 네트워크 전반부와 후반부에서 skip 기여 양상이 뚜렷하게 전환되는 것이 관찰되었다.
- 초기 절반 layer에서는 $\text{[CLS]}$ token(token 0)의 skip 비율이 매우 높아, $\text{[CLS]}$ token 표현이 거의 변화없이 전달되고 있었다.
- 나머지 공간 token들은 skip 비율이 낮아, 변환 경로(attention/MLP)에 의한 갱신 비중이 더 크다는 것을 알 수 있다
- 후반부 절반 layer에서는 반대로, $\text{[CLS]}$ token은 이제 변환 경로 영향을 더 받고 skip 비율이 낮아진 반면, 공간 token들은 skip 비율이 높아져 거의 변화없이 전달되고 있다.
요약하면, ViT에서는 네트워크 중간 지점을 경계로 “$\text{[CLS]}$ token은 초기엔 그대로 유지되다가 후반에 변화되고, 공간 token들은 초기엔 많이 변화되다가 후반엔 유지된다”는 phase transition이 일어난다.
이러한 현상은 Transformer에서 $\text{[CLS]}$ token이 초기에 이미 global적 분류 정보를 모으고, 후반부에서는 오히려 다른 token들이 쌓은 표현을 받아들이는 역할 전환으로 해석할 수 있다.
한편, ResNet의 skip 연결은 layer 전체에 걸쳐 상대적으로 일정한 기여도를 보이고, ViT에 비해 skip 비율 자체도 전반적으로 낮았다 . 즉 ViT의 skip 연결이 ResNet보다 훨씬 강력하게 표현을 전달하며, 특히 CLS vs 공간 token 간 차별적 효과까지 나타낸다는 점에서 큰 차이를 보인 것이다.
5-2. ViT Representation Structure without Skip Connections
skip connection 제거하고 Representation Similarity 구조와 성능 변화를 관찰하는 실험을 수행한다.
예를 들어 ViT-B/16 모델의 중간 블록(예: 6번째 Encoder 블록)에서 skip 연결을 없앤 모델을 훈련하고, 이 모델의 layer와 원본 ViT의 CKA 유사도를 비교한다.
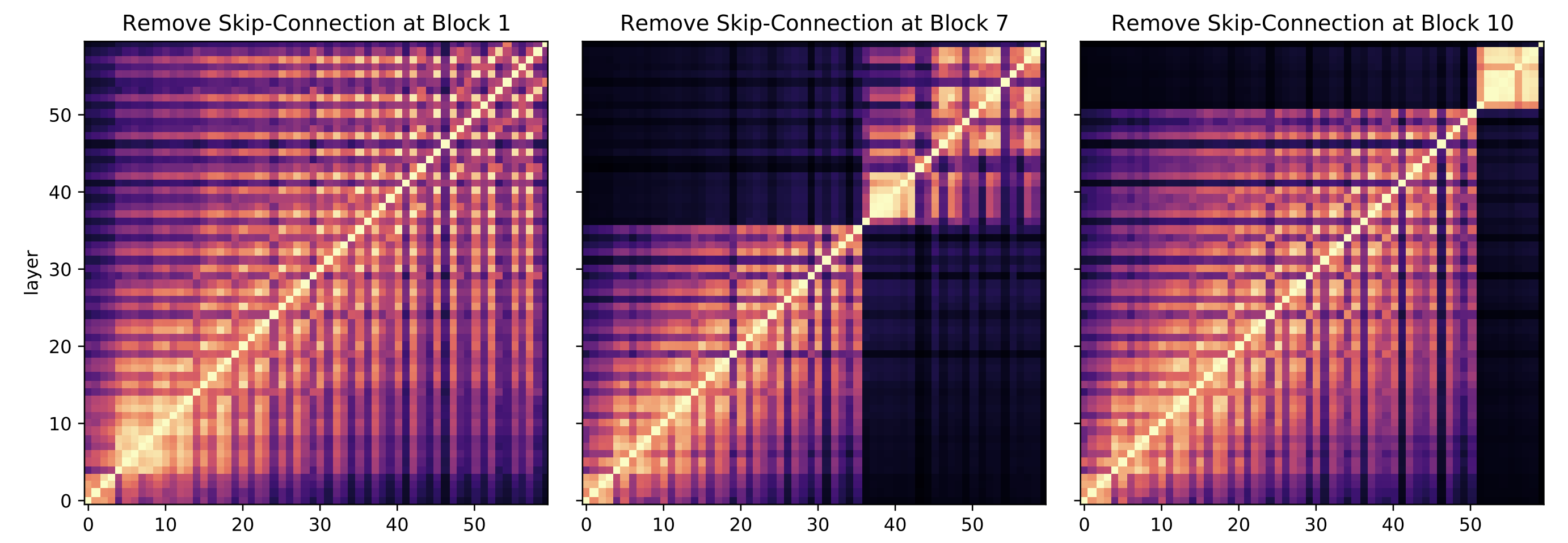
그 결과, skip 연결이 제거된 블록을 경계로 이전/이후 layer 간의 유사도가 급격히 감소하여, 마치 하나의 네트워크가 두 개로 분리된 듯한 표현 단절이 발생했다.
이는 skip 연결이 없는 블록에서는 하위와 상위 표현이 연속성을 잃고 별개로 학습됨을 보여준다.
이러한 skip 제거는 모델의 최종 성능에도 악영향을 미쳤는데, 중간 블록 하나만 skip을 끊어도 4%의 성능 저하가 관찰되었다.
여러 위치의 skip을 제거하여 실험한 결과 모두 유사하게 표현 구조가 블록에서 단절되었으며, 제거 위치가 모델 중간일수록 성능 하락이 뚜렷했다.
이로써 ViT의 균일하고 강한 Layer Representation Similarity 구조는 skip connection에 크게 의존함이 입증되었다 .
반면 ResNet의 경우 skip을 제거하면 학습 자체가 불안정해지기는 하지만 (ResNet에서 skip은 주로 학습 안정화 용도), ViT처럼 Representation Similarity 패턴을 극적으로 바꾸는 사례는 없었다.
정리하면, skip 덕분에 ViT는 하위 layer에서 학습된 feature을 상위까지 보존하면서 필요에 따라 변형을 가해 나갈 수 있다.
특히 ViT에서는 $\text{[CLS]}$ token과 공간 token의 skip 이용 양상이 다르게 진화하여, $\text{[CLS]}$ token은 초기 feature를 그대로 유지함으로써 global 정보를 누적하고, 후반에 공간 token들의 정보를 수용하여 최종 분류에 활용하는 것으로 볼 수 있다.
이러한 강한 표현 전파 능력이 ViT 내부 표현을 ResNet과 구별짓는 중요한 요소임을 본 섹션의 분석이 보여준다.
6. Spatial Information and Localization
지금까지 ViT가 global 정보를 조기에 활용하고 skip connection으로 표현을 유지함으로써 CNN과 다른 표현 구조를 갖는다는 것을 살펴보았다.
이러한 차이가 공간적 위치정보의 보존 측면에서도 영향을 미칠 수 있다.
Spatial localization(공간적 위치 특이성)
모델이 입력 이미지의 어떤(feature)가 어디에 해당하는지를 구별할 수 있는 능력을 뜻한다.
예를 들어, 객체 검출과 같은 과제에서는 최종 feature가 원래 이미지의 특정 위치(객체 위치)에 대응되어야 유용하다.
CNN의 경우, Convolution과 Pooling을 거치며 공간 해상도가 줄어들지만 공간적 순서는 유지되며, 최종 Convolution feature맵의 한 위치는 입력의 특정 영역에 대응한다.
그러나 ResNet 등의 분류 모델은 마지막에 global 평균 Pooling을 해버리므로, 최종 표현 하나에는 모든 공간 정보가 섞여 위치 구분성이 사라진다.
반면 ViT는 별도의 $\text{[CLS]}$ token으로 분류를 수행하므로, 나머지 patch token들은 개별 위치의 정보를 보존한 채 남겨둘 수 있다.
본 섹션에서는 ViT와 ResNet의 높은 layer 표현에 남아있는 공간 정보를 측정하여, Localization 측면의 차이를 분석한다.
이를 통해 ViT가 분류 외의 다른 시각 과제(탐지 등)에서도 잠재력이 있는지 가늠해볼 수 있다.
6-1. Localization and Linear Probe Classification
token별 Localization 실험
저자들은 ViT와 ResNet의 최종 layer에서 token 표현과 입력 이미지 patch 간의 유사도를 측정하는 방식으로 공간 정보 보존 여부를 확인한다.
ViT의 경우 입력을 16×16 등 patch로 쪼개므로, 각 patch token은 해당 위치의 이미지 내용을 주로 담고 있다.
ResNet에서는 명시적 token이 없지만, 최종 Convolution feature맵의 각 공간 위치 (예: 7×7 feature map 중 (i,j) 위치의 2048채널 벡터)를 하나의 “token”으로 간주
이렇게 정의한 token 표현을 가지고, 특정 token vs 입력 이미지의 모든 patch 사이의 CKA 유사도를 계산한다.
만약 한 token이 자신에 대응하는 입력 위치 patch와 높고, 다른 위치 patch와 낮은 유사도를 보이면, 그 token은 선명한 위치 특이성을 갖는다고 볼 수 있다. 반대로 만약 한 token이 여러 입력 위치와 비슷한 관계를 맺으면, 위치정보가 희석되었다고 해석할 수 있다.
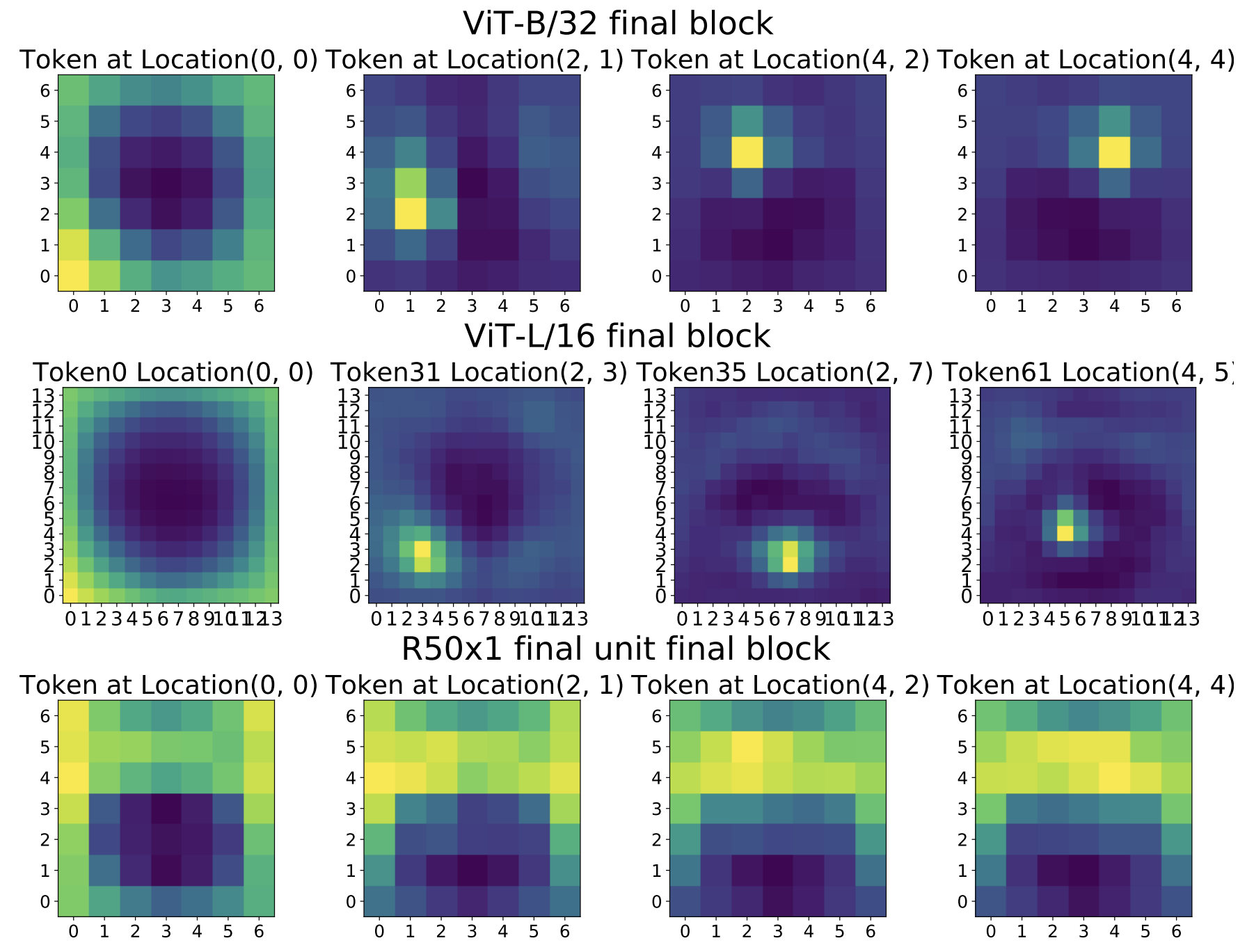
ViT
내부 지역에 해당하는 token들은 해당 입력 patch와 가장 높은 유사도, 다른 위치의 patch와는 낮은 유사도
중앙에 대응하는 token은 입력 이미지의 중앙 patch와 강하게 연관
- 주변 patch들과의 유사도는 낮음
→ ViT token들이 최종 layer까지도 자신의 위치 정보를 유지하고 있음을 의미
다만 가장자리 부분의 token, 예를 들어 맨 모서리 patch에 대응하는 token(0,0)은 자기 위치 patch뿐 아니라 다른 가장자리 patch들과도 일정 수준 유사도를 보였다 .
- 이는 이미지 가장자리 영역들이 비슷한 배경 정보를 공유하거나, 모델이 경계부 token들을 처리할 때 유사한 feature을 주는 결과로 해석
대부분의 ViT token은 자기가 나타내는 위치에 명확히 대응되는 표현을 유지
ResNet
feature맵의 한 위치 벡터와 입력의 여러 위치 patch들이 비교적 고르게 높은 유사도
- 특정 위치의 정보를 뚜렷이 보존하지 않고, 여러 공간 정보가 섞인 포괄적 표현이 되었음을 시사
ResNet의 어떤 위치 feature벡터도 이미지 전체를 두루본 흔적이 남아 있어, 특정 입력 patch에만 매칭되지 못함
다만 ResNet에서도 완전히 위치 특이성이 없는 것은 아니며, 이전 layer들에서는 일부 localization이 남아있다
부록 D의 Figure D.3에서 ResNet의 중간 layer은 최종층보다는 나은 localization을 보임
분류 token vs GAP의 영향
ViT와 ResNet의 이러한 차이는 부분적으로 분류 기법에서 기인한다.
- ResNet : 최종적으로 Global Average Pooling (GAP)으로 모든 공간 위치의 feature을 평균내어 하나의 벡터로 만들고 이를 분류에 사용
- 학습 과정에서 모든 공간정보를 적절히 섞음
- ViT : $\text{[CLS]}$ token 하나만 분리하여 분류
- 다른 patch token들은 개별 정보로 남아있음
이를 검증하기 위해 저자들은 ViT를 $\text{[CLS]}$ token 없이 학습시키는 실험을 진행한다.
구체적으로, ViT 구조에서 $\text{[CLS]}$ token을 제거하고 patch token들을 GAP 방식으로 벡터로 만들도록 해서 동일 데이터로 학습한다.
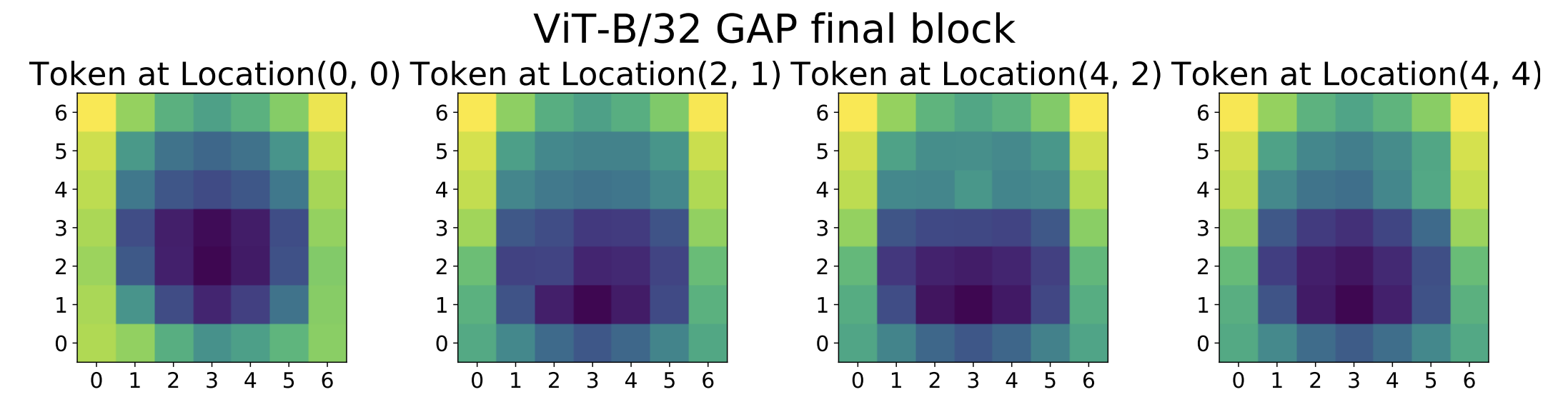
그 결과, GAP 방식 ViT의 token들은 Localization 특성이 많이 감소하였다 .
이는 전용 $\text{[CLS]}$ token 없이 모든 token을 분류에 사용하게 되자 각 token들이 서로 비슷한 global 정보를 띠게 되었음을 의미한다.
결국 ResNet과 ViT의 Localization 차이는 구조적/훈련적 요인에 의한 것이며, ViT의 $\text{[CLS]}$ token 존재가 공간 정보 보존에 긍정적 역할을 한다는 점이 확인되었다.
token별 Linear Probing
Localization을 다르게 바라보는 또 하나의 실험으로, 각 token이 얼마나 global적인 분류 정보를 담고 있는지를 평가한다.
ViT의 경우 $\text{[CLS]}$ token은 전 이미지의 정보를 종합한 분류 특성이지만, 개별 patch token들은 local 특성에 머무를 수 있다. ResNet의 feature맵 위치 벡터들은 최종적으로 평균될 운명이지만, 그 자체로 어느 정도 분류력을 가질 수도 있다.
이를 검증하기 위해, 각 layer의 각 token별로 linear probing으로 학습시켜 해당 token만 가지고 ImageNet 클래스를 예측하도록 실험한다.
일종의 부분 정보로 분류 성능을 보는 실험으로, token이 충분한 global 정보를 가졌다면 이 분류 성능이 높을 것이고, token이 local 정보에 머물러 있다면 낮을 것이다.
실험은 ViT-B/32 모델 (CLS 버전과 GAP 버전), 그리고 ResNet-50 모델에 대해 수행된다. 각 모델의 여러 layer에 대해 10-shot (샘플 10개로 학습) 선형 분류기를 훈련하여, 그 정확도를 측정하였다 .
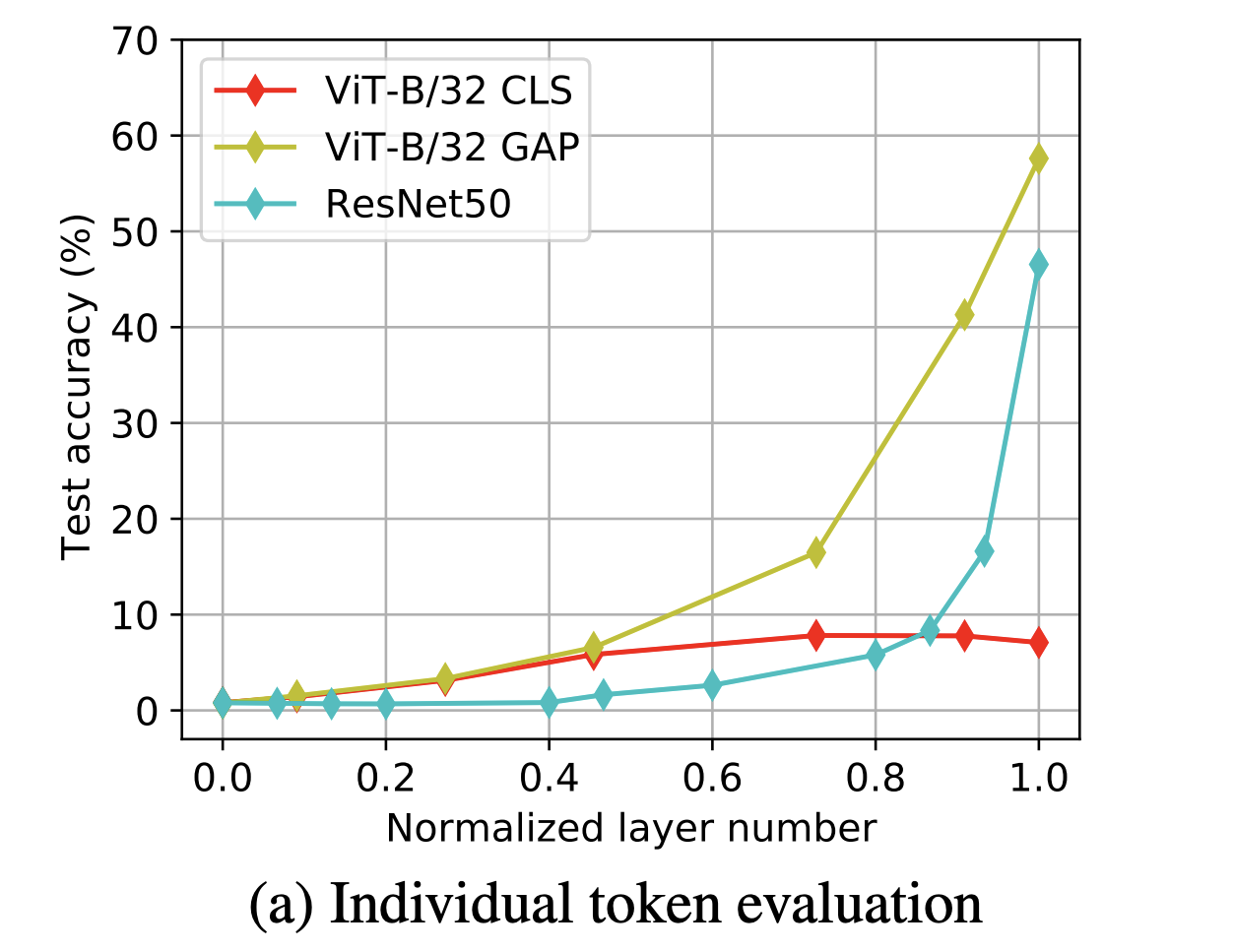
ResNet-50 and ViT-GAP
상위 layer일수록 개별 token(공간 위치)의 선형 분류 정확도가 높아져 최종 layer 근처에서는 상당히 높은 정확도를 보인다
ResNet이나 GAP로 학습된 ViT에서는 각 공간 위치의 표현도 이미 전체 클래스를 예측할 만한 충분한 정보를 지니고 있음을 시사
→ 결국 모델이 최종적으로 평균을 하거나 안 하거나 간에, 학습 과정에서 각 위치 표현들이 유사한 global 정보로 수렴
ViT-CLS
- 상위 layer으로 갈수록 개별 patch token의 분류 정확도는 오히려 떨어지는 경향
- 특히 최종 layer에서 $\text{[CLS]}$ token을 제외한 patch token들은 분류 정확도가 매우 낮음
- token들이 끝까지 각자 local적인 정보만 지니고 있어 하나만으로는 전체 클래스를 맞힐 수 없기 때문
ViT-CLS의 patch token들은 global 정보가 부족한 대신 위치특화 정보로 남아 있고, ResNet이나 ViT-GAP의 token들은 각자 global 정보가 혼합되어 있음을 알수있다.
이 결과는 앞서 CKA 기반 Localization 실험과 일맥상통한다
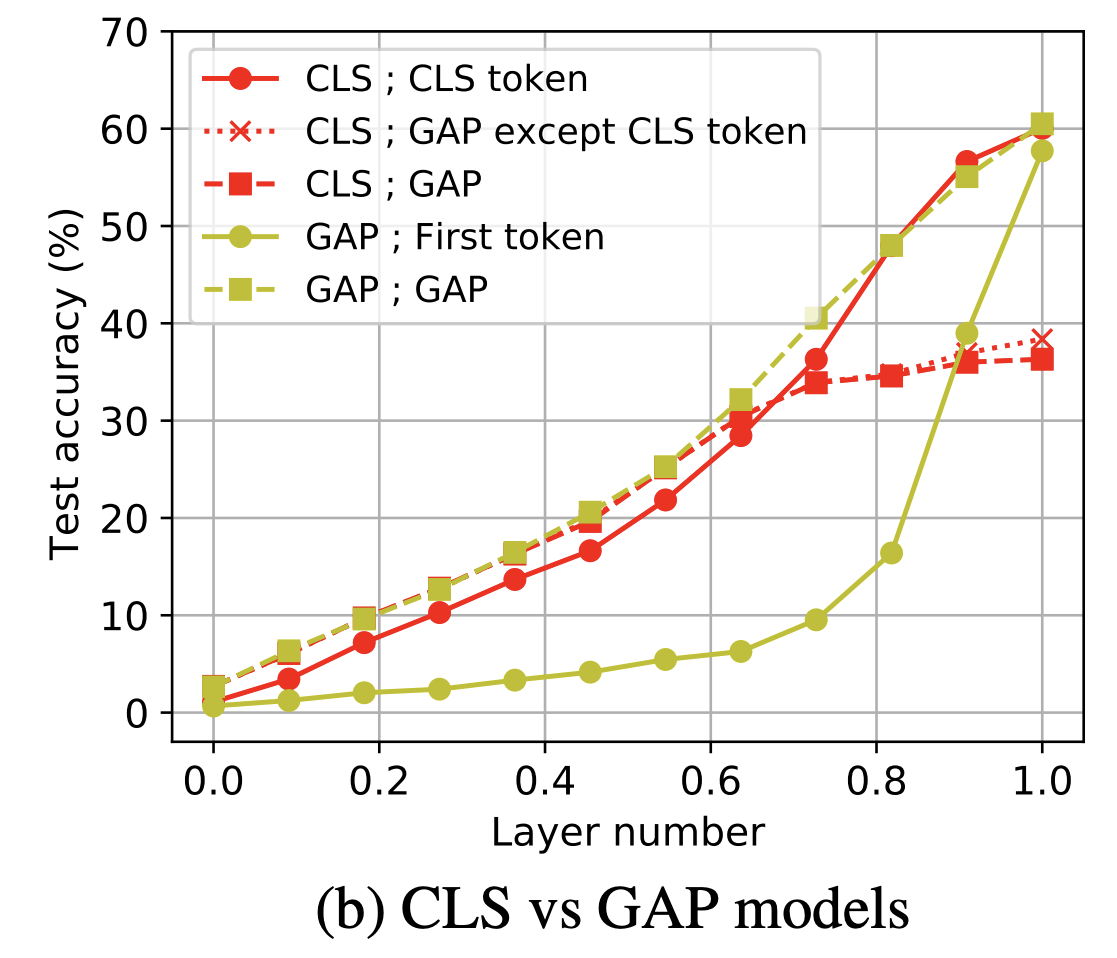
위 이미지는 ViT-CLS와 ViT-GAP 모델을 대상으로, token들을 어떻게 활용하느냐에 따른 분류 성능 비교 결과이다.
ViT-CLS 모델은 원래 $\text{[CLS]}$ token 하나만 써서 분류하지만 만약 모든 patch token을 평균내 분류하면 어떻게 되는지, 반대로 ViT-GAP 모델에서 특정 한 token만 사용하면 어떻게 되는지를 비교한 것이다.
ViT-GAP
- 임의의 한 token만으로도 최종 전체 평균한 것과 맞먹는 분류 정확도를 달성
- 이는 앞서 언급한 대로 GAP 모델의 token들이 서로 매우 유사한 global 표현을 학습했기 때문
ViT-CLS
$\text{[CLS]}$ token 없이 patch token만 평균하면 정확도가 크게 떨어지며, patch token 중 하나만 쓰면 거의 분류가 되지 않았다.
이는 $\text{[CLS]}$ token 없이 ViT-CLS 모델을 활용하기 어렵다는 것을 보여주는 반례인 동시에, ViT-CLS의 patch 표현이 여전히 위치 고유정보 위주로 남아있음을 재확인시켜준다.
추가로 부록 F에는 이러한 linear probing 실험을 CIFAR-10/100 등의 Transfer learning 시나리오로 확장한 결과가 제시되어 있는데, 작은 데이터셋에 대한 분류에서도 대규모 데이터로 학습된 ViT의 중간표현이 ResNet보다 우수하다는 등 일관된 결론을 보여준다.
결론적으로, ViT (특히 $\text{[CLS]}$ token을 사용하는 표준 형태)는 최종 layer까지 공간적 정보가 뚜렷이 보존되고, 각 token이 자기가 담당하는 이미지 부분의 표현을 유지하는 경향이 강하다.
반면 CNN (ResNet)은 마지막에 이르러 공간 정보가 대부분 혼합되어 개별 위치의 특이성이 약하다.
이러한 차이는 분류 token vs global Pooling 전략의 영향이 크며 , 나아가 ViT의 이러한 속성이 물체 검출 등 위치 예민한 작업에서 잠재적 이점으로 작용할 수 있음을 시사한다.
7. Effects of Scale on Transfer Learning
ViT와 CNN의 표현 차이를 이해하는 데 있어 학습 데이터셋 규모(scale) 역시 중요한 요소로 부각되었다. ViT 논문 에서도 대량의 데이터로 사전학습해야 ViT가 CNN을 능가할 수 있음을 강조한 바 있으며, 본 연구에서도 앞서 데이터 부족 시 ViT의 지역 정보 학습 부진을 확인했다.
이 섹션에서는 데이터셋 크기가 모델의 중간표현 및 Transfer learning 성능에 미치는 영향을 다음 2가지를 통해 조사한다.
- 대형 ViT 모델일수록 대규모 데이터의 이점이 큰지
- 동일한 데이터로 학습한 ViT vs ResNet의 transfer learning 성능 차이
먼저 사전학습 데이터의 일부만 사용하여 ViT를 학습시키면서, 전체 데이터로 학습한 모델과 Representation Similarity를 비교한다.
JFT-300M 데이터셋의 3%, 10%, 30%만 이용해 사전학습한 ViT-L/16, ViT-B/32 모델들의 각 layer 표현을, 풀 데이터로 학습한 동일 모델과 CKA로 비교
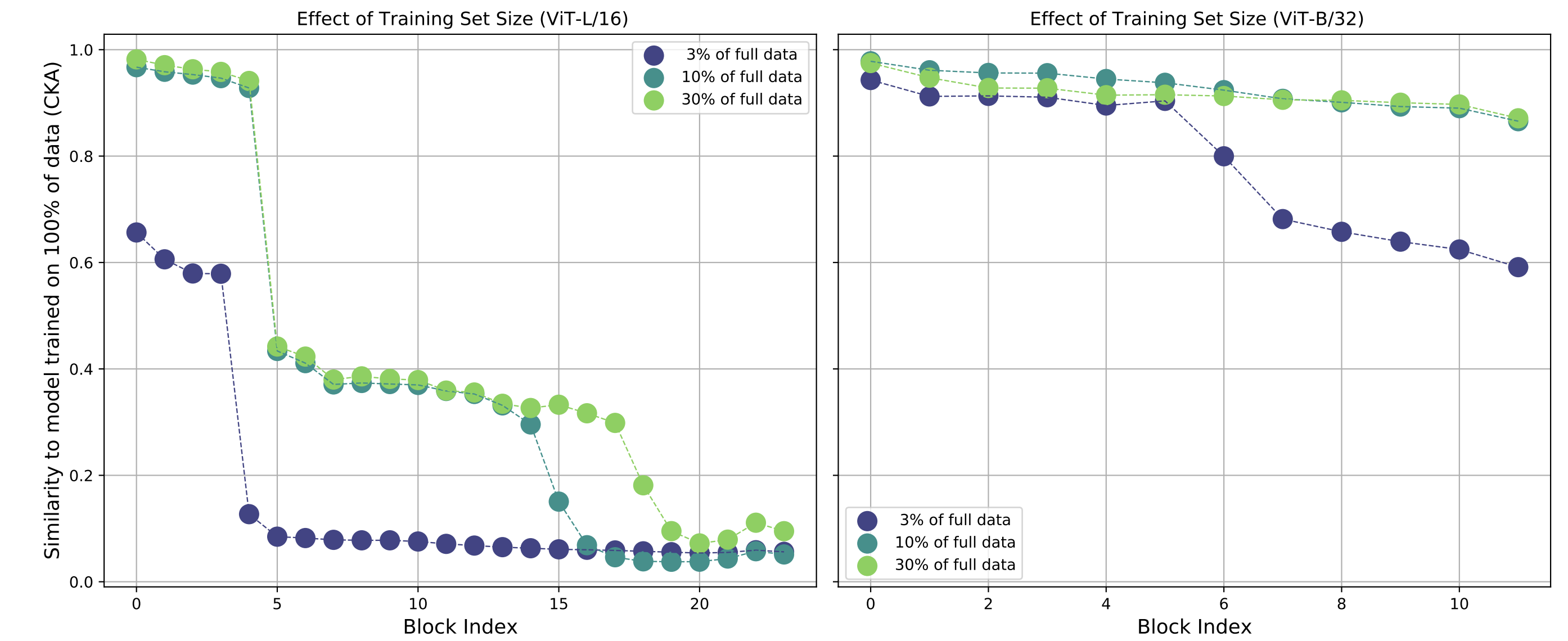
하위 layer 표현은 데이터가 10% 수준으로 적어도 꽤 높은 유사도를 유지
- 이는 엣지, 색 등 저레벨 feature은 적은 데이터로도 충분히 학습됨을 시사
상위 layer 표현은 데이터 양에 따라 큰 차이를 보임
데이터가 부족할수록 상위 표현이 풀 데이터 모델과 상이하며, 특히 모델 크기가 클수록 이러한 차이가 두드러짐
ViT-L/16 같은 큰 모델은 상위 Representation Similarity가 낮아, 충분한 데이터 없이 큰 모델을 훈련하면 모델 용량을 활용한 고품질 표현 학습이 어려움을 보여준다.
이는 곧 대규모 ViT 모델이 진가를 발휘하려면 그에 상응하는 대량의 데이터가 필수임을 시사
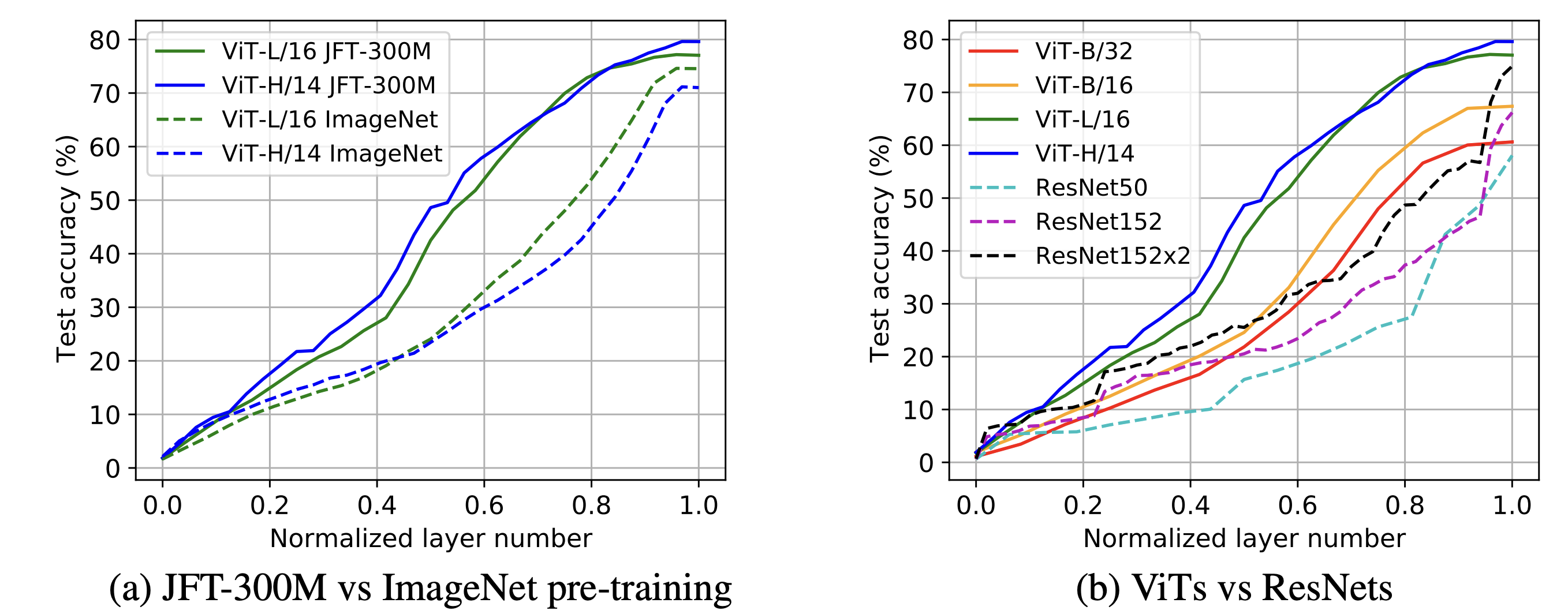
Transfer learning 관점에서 데이터 규모 효과를 평가하기 위해 linear probing를 통한 이미지 분류 성능을 비교한다.
위 그림의 (a)에서는 대규모(JFT) vs 소규모(ImageNet) 사전학습이 ViT-L/16 등의 중간layer 분류 성능에 미치는 영향을 보여준다.
JFT-300M으로 사전학습한 ViT는 ImageNet으로만 학습한 ViT 대비, 중간 layer부터도 월등히 높은 분류 정확도를 보인다.
예컨대 한 중간layer의 선형프로브 정확도 차이가 두 자릿수 퍼센트 포인트에 이를 정도로, 대규모 데이터 학습은 ViT의 표현 품질을 비약적으로 향상시킨다.
이는 특히 대형 모델일수록 두드러져서, 작은 데이터로는 유효한 중간표현을 거의 학습하지 못했던 ViT-L/H 모델도 거대한 데이터로는 뛰어난 중간표현을 갖추게 된다.
(b)에서는 동일한 JFT-300M 데이터로 사전학습한 ViT vs ResNet들의 전이 성능을 비교한다.
ViT 계열 모델들이 전반적으로 ResNet보다 높은 정확도를 보인다.
특히 모델 크기가 커질수록 그 격차가 벌어져, ViT-L/16은 ResNet-152보다 중간layer 전이 성능이 훨씬 우수하다 .
이는 ViT 아키텍처가 대규모 데이터 학습에서 보다 일반화된 feature을 학습하여, Transfer learning시 더 나은 성능을 발휘함을 의미한다.
결국 대규모 사전학습 데이터는 Transformer 기반 모델의 표현력을 극대화하며, 충분한 데이터를 갖춘 ViT는 동일한 데이터로 학습한 CNN보다 Transfer learning 친화적인 표현을 형성한다는 결론을 얻을 수 있다.
Discussion
Limitations
- CKA라는 단일 지표에 많이 의존하여 표현 구조를 논의
- CKA는 대규모 신경망 표현을 간결한 하나의 유사도 수치로 요약해주는 강력한 도구이지만, 그 과정에서 세부적인 차이나 분포 형태 등의 정보는 소실될 수 있음
- 이 한계를 보완하고자 개입 실험(attention 헤드 부분집합, skip 제거 등)이나 linear probing 등의 추가 분석을 수행
- 그럼에도 불구하고 여전히 CKA로는 드러나지 않는 미묘한 표현상의 차이가 있을 수 있음
- 다른 분석 기법(예: 특이벡터 분석, 시각화 기법 등)을 통해 더 세밀한 통찰을 얻을 여지 존재
- 이미지 분류 모델에 초점
- 분류 이외의 작업(예: 세분화, 검출)이나 다른 구조의 모델(예: EfficientNet, Swin Transformer 등)에 대해서는 추가 검증이 필요
- Representation Similarity가 곧 모델의 모든 것을 말해주는 것은 아님
- 표현이 달라도 최종 성능은 비슷할 수 있음
- 반대로 Representation Similarity가 높아도 처리과정이나 동작은 다를 수 있음
- 따라서 표현 분석은 모델 동작 이해의 한 측면일 뿐이며, 이를 종합하여 신중히 해석해야함
Conclusion
이 논문은 ViT와 CNN의 내부 표현 구조 차이를 면밀히 비교 분석함으로써, 두 아키텍처가 시각적 과제를 해결하는 방식의 근본적 차이를 밝혀낸다.
CNN이 수년간 vision 분야를 지배해온 가운데, Transformer 계열 모델이 거의 변경 없이도 vision 분야에서 성공한 것은 놀라운 일이며 , 이에 따라 “과연 이들이 같은 방식으로 보이는 성과를 내는가?”라는 질문이 제기되었다. 본 연구의 분석에 따르면, ViT는 CNN과 상당히 다른 내부 feature과 구조를 지닌 것으로 드러났다:
- 표현 구조
- ViT의 layer 표현들은 global적으로 균일하고 연속적인 반면, ResNet의 표현들은 layer별로 구획화되고 단계적인 feature을 보임
- ViT 내부에서는 하위-상위 Representation Similarity가 높아 일관된 표현 흐름이 유지되며, CNN 내부에서는 저수준→고수준 feature으로 뚜렷이 변화한다.
- global 정보 및 지역성
- ViT는 self-attention을 통해 초기부터 global 정보를 통합하고, CNN이 갖는 지역 특성 학습은 충분한 데이터로부터 사후에 학습
- 이로 인해 ViT 하위 feature은 CNN의 하위 feature과 성질이 달랐으며, 동시에 local 정보의 조기 활용은 성능에 여전히 중요하여 대규모 데이터 학습이 ViT에 필요함을 확인
- Residual 연결의 영향
- ViT의 강한 skip connection은 표현을 상위 layer까지 보존하며, $\text{[CLS]}$ token과 공간 token 간 표현 전달 방식에 feature적인 전환을 형성
- skip connection을 제거하면 ViT 특유의 균일한 표현 구조가 붕괴되어 성능 저하로 이어지는 등, Representation Similarity 구조 형성에 skip이 결정적임이 증명됨
- 공간 정보 보존
- ViT (특히 $\text{[CLS]}$ token 사용 모델)는 최종 표현까지도 입력의 공간적 대응관계를 상당 부분 유지하여, 각 token이 자기 위치에 해당하는 정보를 지니고 있음
- 반면 ResNet은 global Pooling으로 인해 위치정보가 혼합되어 token별 구분도가 감소
- ViT를 GAP 방식으로 바꾸면 위치 특이성이 감소하는 등, $\text{[CSL]}$ token의 존재가 ViT의 공간정보 보존에 기여
- ViT가 분류 이외에도 객체 위치 식별 등으로 활용될 가능성을 시사
- 데이터 규모와 Transfer learning
- 대규모 데이터 사전학습은 특히 대형 ViT의 중간표현 품질을 크게 향상
- Transfer learning시 우수한 선형 분류 성능
- 동일한 대규모 데이터로 학습한 경우에도 ViT의 중간표현은 ResNet보다 풍부한 정보를 담아, 작은 데이터셋에 대한 전이 성능에서도 ViT가 앞섰다
- 이는 ViT가 데이터로부터 더 나은 범용 표현을 학습하는 잠재력이 있음을 시사
- 대규모 데이터 사전학습은 특히 대형 ViT의 중간표현 품질을 크게 향상
이러한 발견들은 동시대에 제안된 MLP-Mixer 등 비Convolution 신경망을 이해하는 데에도 시사점을 준다.
MLP-Mixer는 self-attention 대신 MLP로 patch 간 상호작용을 하는 구조인데, 부록 H의 예비 결과에 따르면 MLP-Mixer 모델들도 뚜렷한 자체의 표현 패턴을 보인다.
ViT와 CNN의 차이를 이해함으로써, MLP-Mixer나 향후 등장할 새로운 아키텍처들의 표현 특성도 유추해볼 수 있을 것이다.
종합하면, 본 연구는 “ViT는 CNN처럼 보는가?”라는 중앙 질문에 대해 “내부적으로는 다르게 본다”는 답을 제시하면서, 미래 연구 방향으로
- 다양한 아키텍처 간 표현 비교 확대
- 표현 구조와 성능의 인과관계 탐구
- 해석가능성 제고와 잠재적 실패 모드 진단
등에 대한 단서를 제공한다.
이러한 심층적인 비교 연구는 향후 더 효율적이고 강건한 vision 모델 설계와 모델 이해 향상에 기여할 것으로 기대된다.
추가 Limitation
- 지표 의존성(=CKA 한계)
- 원 논문도 “CKA는 (한 쌍의 층에 대해) 단일 스칼라로 요약해 버려 세부 구조를 놓칠 수 있다”는 점을 한계로 명시한다. 더 미세한 방법이 다른 통찰을 줄 수 있음을 인정한다.
- 후속으로 CKA의 신뢰성 문제가 이론·실험적으로 제기되었다: (i) 단순 변환·이상치(outlier)에 민감, (ii) 선형분리 보존 변환에도 값이 크게 바뀔 수 있어 모델 기능적 동등성과 반드시 일치하지 않음 → CKA 값은 조작 가능하며 해석에 주의가 필요하다는 결과.
- 주의 가중치 기반 해석의 한계(Attention distance 등)
- ViT에서 raw attention만으로 수용범위/원인성을 해석하는 것은 불완전하다는 비판이 다수: attention은 skip connection·비선형성과 얽혀 있어 그 자체가 설명(Explanation)이 아니다는 결과와, 보다 신뢰도 높은 관련성 전파/그래디언트 기반 방법을 권장하는 보고가 있다. 따라서 “attention distance”류 분석은 근사적 지표로 이해해야 한다.
- 아키텍처 범위의 제한(바닐라 ViT vs 현대 계층형 ViT)
- 원 논문은 바닐라 ViT(B/L/H) 대 ResNet 비교가 중심이다. 이후 연구는 계층형/윈도우형 ViT(Swin 등)이 다단(stage-wise) 네트워크처럼 동작하고, MSA는 저역통과(low-pass), Conv는 고역통과(high-pass)라는 대체 메커니즘을 제시했다. 즉 “초기 global 접근성”만으로 모든 ViT를 설명하기 어렵다.
- [CLS] vs GAP에 따른 일반화 한계(공간정보 보존 주장)
- 원 논문은 ViT가 최상위에서도 공간위치 정보를 비교적 잘 보존한다고 보고했지만(특히 CLS 사용 시), 후속 대규모 시각화는 “마지막 layer는 오히려 공간정보를 버리고 ‘학습된 global pooling’처럼 동작”한다고 보고했다. 즉 pooling 전략에 따라 결론이 바뀐다.
- 또한 GAP/Attention Pooling이 CLS를 대체해도 성능이 동등·개선될 수 있다는 결과들이 있어, CLS 기반 결과의 보편성에 주의가 필요하다.
- 데이터 레짐 의존성·재현성
- 실험 다수가 비공개 초대형 JFT-300M 사전학습에 의존한다(논문 본문에 명시). 이는 재현성·접근성 한계를 만든다. 이후 연구는 공개 데이터셋 + 강한 AugReg로 JFT 성능을 상당 부분 대체 가능함을 보였다 → 데이터 규모·전처리의 영향이 큼.
- 과제 범위
- 원 논문은 분류 및 linear probe 중심으로 분석했다. 후속 연구는 자기지도·다양한 사전학습이나 다른 다운스트림(검출/분할 등)에서 표현·공간성 보존 양상이 달라질 수 있음을 보인다(예: 자기지도 목표가 표현 유사도 곡선을 바꾼다는 결과). → 학습 목적/태스크에 따른 표현 차이를 추가로 고려해야 한다.
요약하면: 이 논문은 CKA 기반의 정량 비교로 ViT와 CNN의 차이를 처음 크게 조명했지만, (i) CKA 자체의 한계, (ii) attention 가중치 해석의 신뢰도, (iii) 아키텍처·pooling·데이터 레짐에 따른 결론 민감도, (iv) 태스크 다양성 부족이 후속 연구에서 지적·보완되었다고 보면 된다.