[Paper Review] WaveNet
[논문 리뷰] WaveNET: A Generative Model for Raw Audio
WaveNET: A Generative Model for Raw Audio
Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, Koray Kavukcuoglu
[Arxiv]
2016년에 구글 DeepMind에서 발표한 음성 생성모델로, AutoRegregressive 구조의 이미지 생성모델 PixelCNN에서 영감을 받은 모델이다.
BackGround
기존 TTS 합성 방식에는 다음과 같이 Parametric TTS와 Concatenative TTS 방식이 SOTA로 자리잡고있었다.
Parametric TTS
음성을 직접 합성하는 대신, 음성 합성기에 필요한 음향 parameters를 예측하고, 이를 기반으로 합성 filter나 vocoder가 원시 음성 신호를 생성하는 방식
문장과 발음 단위(음소), 강세 정보 등을 추출하고 DNN, RNN 등의 모델로 Melspectrogram, F0(피치), 지속시간(duration) 등의 파라미터를 예측
단점
예측된 파라미터가 실제 음성 파형의 미세한 스펙트럴 변화를 완벽히 반영하지 못해 기계음 같은 합성음이 됨
보코더가 파라미터를 단순 변환하기 때문에, 말투나 감정 표현이 제한적
Concatenative TTS
- 실제 인간이 녹음한 음성 샘플(단어, 음소, 음절, 짧은 프레이즈 등)을 데이터베이스에 저장해 두고, 입력 텍스트에 맞춰 가장 적절한 unit를 검색한 뒤 concatenate하여 자연스러운 문장을 합성하는 방식
- 단점
- 다양한 발음·억양·속도를 포괄하려면 수십~수백 시간 분량의 녹음이 필요해 저장 공간과 관리 비용이 크다.
- 단위 간 연결 부위에서 음질 불연속, 박자 어긋남, 음색 차이 등이 발생하기 쉽다.
- 새로운 단어나 억양, 감정 등을 지원하려면 추가 녹음이 필수여서 유연성이 떨어진다.
WaveNet은 기존 TTS 합성방식을 따르지 않고 unit(픽셀,단어)에 대한 결합 확률을 조건부 분포의 곱으로 모델링하는 Autoregressive 구조를 따르며, dilated causal convolution을 사용해 긴 시계열 의존성을 효율적으로 학습한다.
그렇다면 Autoregressive 구조란 무엇일까?
Autoregressive 모델
Autoregressive 모델은 시퀸스한 시계열 데이터에서 $i$ 번째 시점의 확률 분포 $p(x_i)$를 이전 시점까지의 데이터 $x_{<i}, (x_1,x_2,⋅⋅⋅,x_{i−1})$을 가지고 예측하는 모델이다.
전체 데이터 분포 $p(\mathbf{x})$는 chain rule을 이용해 다음과 같이 분해된다:
\[p_\theta(\mathbf{x}) \;=\; \prod_{i=1}^{N} p(x_i \mid x_1, \ldots, x_{i-1}).\]여기서 $\theta$는 신경망 파라미터를 의미하며, input으로 ${x_1, \ldots, x_{i-1}}$를 받아 $x_i$의 분포를 예측한다.
Introduction
논문에서는 위와 같이 복잡한 분포를 모델링한 Autoregressive 생성 모델에서 영감을 받아 원시(raw) 오디오 파형 생성 기법을 탐구하며, 초당 16,000개 이상의 샘플을 가지는 고해상도 오디오 파형 생성을 위해 유사한 접근법이 유효한지 여부를 다룬다.
연구의 주된 기여를 요약하면 다음과 같다.
- 주관적 자연도 : WaveNet이 인간 평가자에 의해 평가된 TTS 분야에서 SOTA 수준의 자연스러움을 가진 원시 음성 신호를 생성함을 보인다.
- 장기 의존성 처리 : 원시 오디오 생성에 필요한 장기 시계열 의존성을 다루기 위해 dilated causal convolutions 기반의 신규 아키텍처를 개발하여 매우 큰 Receptive field를 확보한다.
- 다중 화자 지원 : 화자 ID를 Condition으로 제공하면 단일 모델로 여러 화자의 음성을 생성할 수 있음을 보인다.
- 다양한 오디오 응용 : 동일한 아키텍처가 작은 음성 인식 데이터셋에서 강력한 성능을 보이며, 음악 등 다른 오디오 형태의 생성에도 유망함을 확인한다.
WaveNet은 TTS, 음악 생성, 음성 향상, 음성 변환, 음원 분리 등 오디오 생성이 필요한 다양한 응용에 범용적이고 유연한 프레임워크를 제공한다.
WaveNet
WaveNet은 길이 $T$인 오디오 파형 $\mathbf{x} = {x_1, x_2, \dots, x_T}$에 대해, 아래와 같이 체인 룰(chain rule)을 이용해 결합 확률을 오토리그레시브 방식으로 모델링한다:
$p(\mathbf{x}) = \prod_{t=1}^{T} p\bigl(x_t \mid x_1, x_2, \dots, x_{t-1}\bigr).$
각 샘플 $x_t$는 이전에 생성된 모든 샘플 $x_{<t}$에 대해 조건부 확률 분포로 모델링되며, PixelCNNs 처럼 Convolution Layer들을 쌓아 모델링된다.
네트워크에는 Pooling layer가 없고, softmax를 통해 다음 값 $x_t$에 대한 분포를 출력하며, 파라미터에 대한 데이터의 log likelihood를 최대화하도록 optimizing된다.
Pooling layer가 없는 이유는 Pooling을 적용하면 입력을 다운샘플링해 시간 해상도가 떨어지므로, 각 샘플을 하나하나 예측해야 하는 Autoregressive 구조와 맞지 않기 때문
또한, Pooling 후 업샘플링 과정에서 샘플 간 연결 부위에서 잡음이 생기기 쉬움
WaveNet 아키텍처의 핵심 구성 요소는 dilated causal convolutions, gated activation 유닛, residual 및 skip 연결이다.
1. Dilated Casual Convolutions
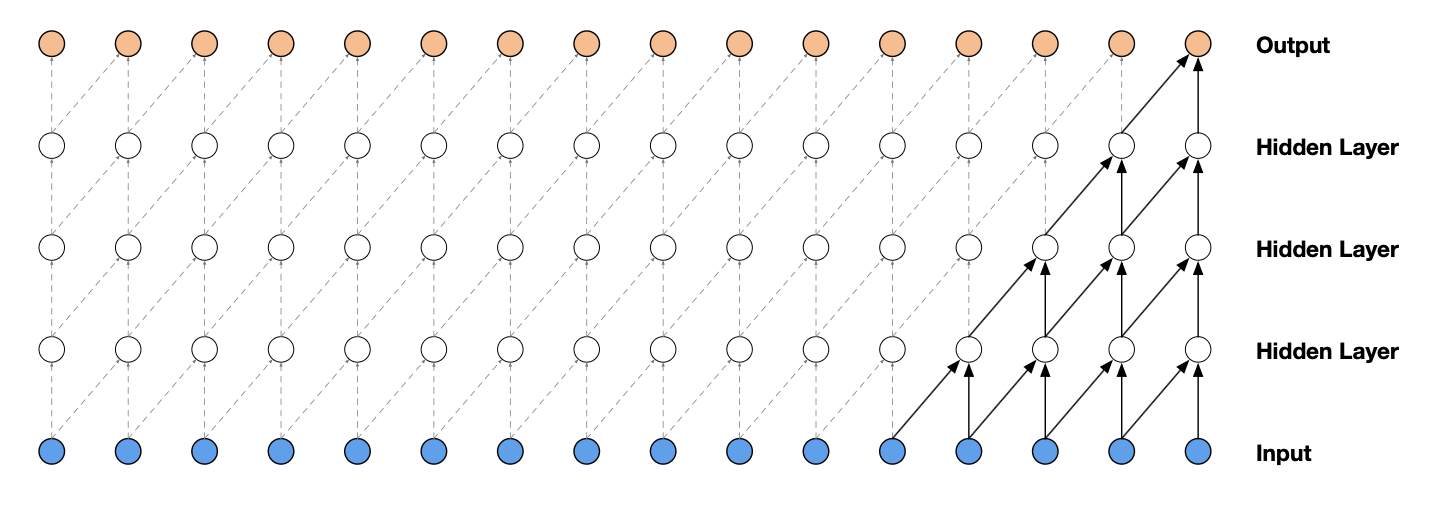
WaveNet은 Causal Convolution에 딜레이(dilation) 를 결합한 구조를 사용하여, 장기 시계열 의존성을 효율적으로 모델링하는 것이다.
Casual Convolution
일반적인 Convolution과 달리 오직 과거 시점 $<t$의 입력만을 참조하는 Causal Convolution을 사용함으로써, 모델링 과정에서 순서를 위반하지 않도록 한다.
위 그림처럼 모델이 timestep $t$에서 생성하는 예측 $p(x_{t+1} |x_1,…,x_t)$는 미래 timestep $x_{t+1},x_{t+2},…,x_T$에 의존하지 않는다.
이미지 합성(PixelCNN)에서는 Mask를 적용하여 참조하지 않을 정보(현 위치의 픽셀보다 우측, 하단에 있는 픽셀)에 0으로 표시하여 모델링
오디오는 1차원 시퀸스 데이터이기 때문에 WaveNet에서는 Mask 없이 참조하지 않을 정보만큼(T-t) 뒤로 shift하고, 앞쪽에 생긴 빈공간에는 0을 채우는 방식을 통해 과거 정보만 참조
$[x_1, x_2, x_3, x_4] \rightarrow [0,0,x_1, x_2],x_3,x_4$
Causal Convolution은 recurrent connection이 없기 때문에, 아주 긴 시퀀스에 적용할 때 RNN보다 학습 속도가 빠르다. 하지만 receptive field를 키우기 위해 많은 층이나 큰 필터를 필요로 한다는 문제가 있다.
이 논문에서는 Dilated Convolution을 사용해 계산 비용을 크게 늘리지 않으면서도 receptive field을 수십 배로 확장한다.
Dilated Convolution
신호 처리 혹은 Segmentation 분야에 적용된적 있는 Dilated Convolution은 필터, 즉 kernel이 더 넓은 영역에 걸쳐 적용되도록, 일정 간격만큼 입력 값을 건너뛰면서 연산하는 Convolution이다.
일반 Convolution의 3×3 커널 \(W = \begin{bmatrix} w_{11} & w_{12} & w_{13}\\ w_{21} & w_{22} & w_{23}\\ w_{31} & w_{32} & w_{33} \end{bmatrix}\) 이 있을 때,
dilation = 2인 Dilated Convolution의 커널은 \(W_{\text{dilated}} = \begin{bmatrix} w_{11} & 0 & w_{12} & 0 & w_{13}\\ 0 & 0 & 0 & 0 & 0 \\ w_{21} & 0 & w_{22} & 0 & w_{23}\\ 0 & 0 & 0 & 0 & 0 \\ w_{31} & 0 & w_{32} & 0 & w_{33} \end{bmatrix}\) 가 된다.
실제로 위와같이 0을 넣은 5×5 커널을 적용하지 않고, 효율적인 구현을 통해 연산량을 최소화한다.
오디오나 시계열 데이터의 경우 1D 벡터에 3 kernel $[w_1, w_2, w_3]$를 사용한다고 하면,
dilation = 1 (표준 합성곱과 동일)
$y_t = w_1 x_{t-2} + w_2 x_{t-1} + w_3 x_t$
dilation = 2
$y_t = w_1 x_{t-4} + w_2 x_{t-2} + w_3 x_t$
여기서 $x_{t-4}, x_{t-2}, x_t$처럼 두 칸씩 건너뛴 샘플들만 참조
이는 pooling이나 strided Convolution과 유사하지만, 출력 해상도는 입력과 동일하다.
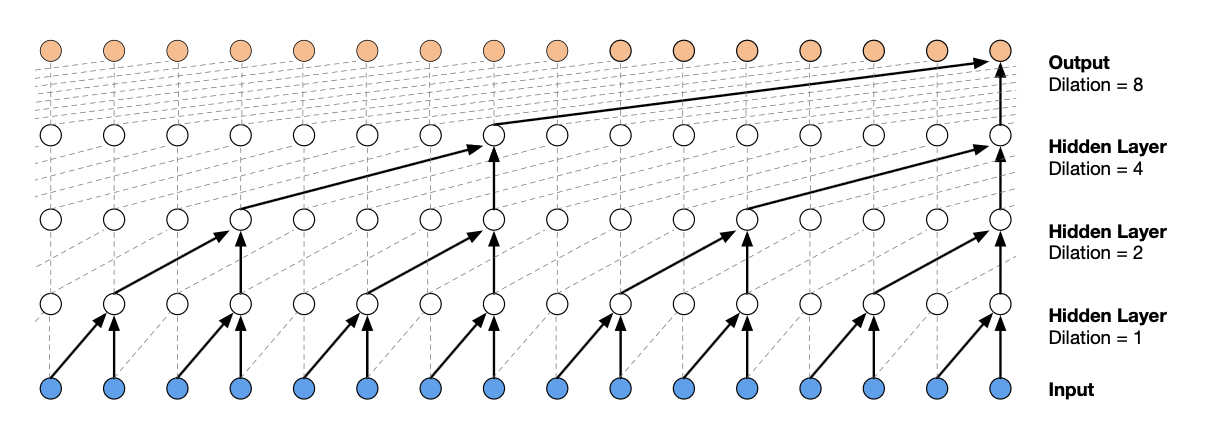
위 그림은 dilation이 1, 2, 4, 8일 때의 Dilated Convolution을 보여 준다.
이와 같이 Dilated Convolution을 여러개 쌓으면 네트워크 전체에서 입력 해상도를 유지하면서도 큰 receptive field을 단 몇 개 layer로 확보할 수 있고, 계산 효율성도 유지된다.
dilation 계수를 $1,2,4,\dots$로 늘리면, 각 layer가 참조하는 과거 샘플 간격이 두 배씩 커져 블록 하나만으로도 긴 시퀀스를 커버한다.
예컨대 $k=2$인 필터를 $d=1,2,4,\dots,512$로 10개 쌓으면 수용 영역이 $2^{10}-1=1023$ 샘플이 된다.
본 논문에서는 dilation 계수를 각 layer마다 두 배씩 늘렸다가 일정 한계에 도달하면 다시 1로 되돌리는 방식을 반복한다. ($1,2,4,…,512,1,2,4,…,512,1,2,4,…,512$)
한 번 $1→512$ 까지 늘린 다음 다시 1로 돌아가는 것을 여러 번 반복하면, 네트워크가 짧은·중간·긴 범위의 패턴을 모두 비선형적으로 학습할 수 있다.
반복 횟수가 늘어날수록 모델의 표현력과 수용 영역이 함께 증가한다.
2. Softmax Distribution
각 샘플 $x_t$의 조건부 분포 $p(x_t \mid x_{<t})$는 categorical distribution로 모델링하며, 마지막 출력층에서는 Softmax 함수를 사용해 각 양자화된(quantized) 값에 대한 확률을 계산한다.
오디오 파형은 연속적인 실수 값이지만, 직접 실수 분포(예: 가우시안)를 학습하면 모델링이 어렵고 수치적 불안정할 수 있다.
그렇기 때문에 $\mu$-law 양자화를 통해 16비트(65,536단계) 신호를 8비트(256단계)로 압축하면, 음질 저하를 최소화하면서도 모델이 다룰 출력 차원을 256으로 제한할 수 있다.
원시 오디오 신호를 아래 $\mu$-law 양자화를 거쳐 256단계로 조밀하게 분할한 뒤, 각 단계에 정수 레이블 $(0,1,\dots,255)$ 를 부여한다.
\[f(x_t) = \operatorname{sign}(x)\,\frac{\ln\bigl(1 + \mu |x_t|\bigr)}{\ln(1+\mu)}, \quad \text{where} -1 <x<1,\;\mu=255.\]WaveNet의 최종 블록에서 256 크기의 벡터로 변환하는 1×1 Convolution을 사용하여 각각에 대한 로짓(logit) 값을 구하고, Softmax로 확률 분포를 얻는다.
이렇게 얻은 분포로부터 샘플링하거나, 학습 시에는 각 로짓 벡터에 대해 정답 레이블 하나만을 교차 엔트로피(cross-entropy) 손실을 최소화하도록 네트워크를 최적화한다.
생성시에는 이전까지 생성된 샘플만 이용해 Softmax 분포를 계산하고, 그 분포로부터 하나의 심볼을 샘플링한다. 이 값을 다시 입력으로 넣어 순차적으로 다음 샘플을 생성
3. Gated Activation Units
gated PixelCNN에서 사용된 동일한 Gated Activation Units을 사용한다.
\[\mathbf{z} = \tanh\bigl(W_{f,k} * \mathbf{x}\bigr)\;\odot\;\sigma\bigl(W_{g,k} * \mathbf{x}\bigr),\]- $*$ : convolution 연산
- $\sigma(\cdot)$ : Sigmoid 함수
- $k$ : layer 인덱스
- $f$와 $g$ : filter와 gate
- $W$ : 학습 가능한 Convolution Kernel
각 레이어 k마다 두 종류의 Convolution(filter, gate)을 수행한다.
$\tanh$ 분기(filter)는 입력의 변형된 값을 만들어 내고, $\sigma$ 분기(gate)는 0~1 사이의 게이트 값을 생성해 어느 정도 “통과”시킬지를 조절한다. 원소별 곱을 통해, “filter 분기”의 각 성분이 “gate 분기”의 출력을 통해 가중 제어되는 셈이다.
음수 값을 모두 없애버리는 ReLU는 파형의 음성 신호 같은 연속적 변화에는 부적합할 수 있다.
Gated Activation은 tanh를 통해 양방향 정보를 남기면서도, 시그모이드 게이트로 각 위치의 중요도를 학습해 더 풍부한 표현력을 제공한다.
4. Residual and Skip Connections
WaveNet은 Residual connections 과 Skip connections 을 도입한다.
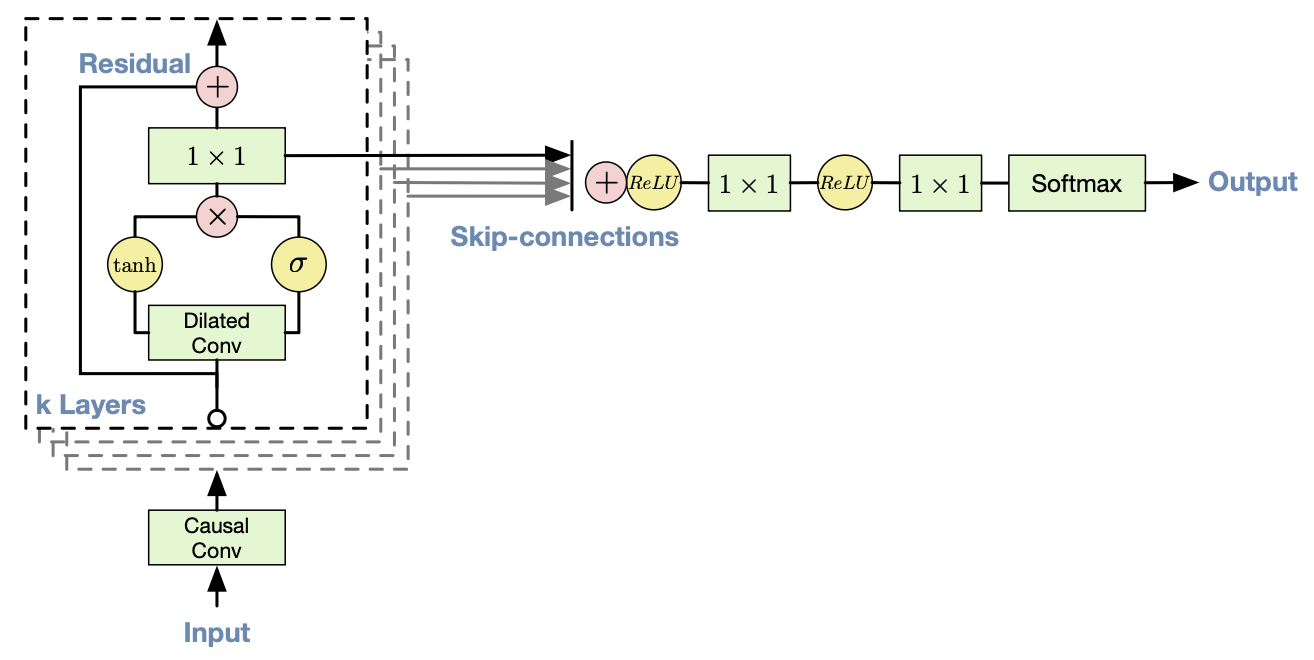
Residual connections을 통해 각 Convolution의 출력에 입력값을 더해주고, Skip connections에서 각 블록의 Gated Activation 출력을 최종 출력층에 보냄으로써 low-level부터 high-level 표현까지 학습할 수 있다.
Residual connections
- 깊은 신경망에서는 층이 깊어질수록 gradient가 사라지거나 폭발하는 문제가 발생한다.
- 잔차 연결은 “입력 → 블록 연산 → 출력”의 전형적 흐름에, **블록 입력을 그대로 출력에 더해준다.
- 이로 인해 역전파 시 기울기가 직접 앞쪽으로 전달되어, 학습이 원활해지고 수백 레이어를 쌓아도 성능 저하를 막을 수 있다.
Skip connections
- 단일 블록만의 출력을 최종 layer에서 직접 사용하면, 중간 단계에서 학습한 다양한 level의 특징이 소실될 수 있다.
- 이를 통해 네트워크는 low-level의 detail한 정보 와 high-level의 추상적인 표현 을 동시에 활용할 수 있어, 더욱 풍부하고 정확한 생성이 가능하다.
Conditional WaveNet
추가 입력 $h$가 주어지면, WaveNet은 이 입력에 conditional distribution $p(\mathbf{x}|\mathbf{h})$를 모델링할 수 있다.
\[p(\mathbf{x}\mid \mathbf{h}) = \prod_{t=1}^T p\bigl(x_t\mid x_1,\dots,x_{t-1},\,\mathbf{h}\bigr)\]이를 통해 화자식별자를 condition으로 하여 특정 목소리를 선택하게 하거나 TTS에서 텍스트를 condition으로 주는 등, 원하는 특성을 지닌 오디오를 생성하도록 유도할 수 있다.
WaveNet을 다른 입력에 조건화하는 방식은 크게 두 가지다:
Global Conditioning
모든 timestep에 걸쳐 출력 분포에 영향을 주는 단일 latent representation $\mathbf{h}$를 사용하는 방법이다.
예를 들어 TTS 모델에서 화자 임베딩(speaker embedding)이 여기에 해당한다. 이때 Gated Activation Unit 식은 다음과 같이 바뀐다:
\[\mathbf{z} = \tanh\bigl(W_{f,k} * \mathbf{x} \;+\; V_{f,k}^{\mathsf{T}}\,h\bigr) \;\odot\; \sigma\bigl(W_{g,k} * \mathbf{x} \;+\; V_{g,k}^{\mathsf{T}}\,h\bigr),\]여기서 $V_{\ast,k}$는 학습 가능한 linear projection이며, $V_{\ast,k}^{\mathsf{T}}h$ 벡터는 시간 차원 전체에 브로드캐스트된다.
적용 예시 : 다중 화자 TTS:
각 화자의 one-hot 벡터를 전역 조건화로 입력해, 단일 모델이 여러 화자의 목소리를 생성하도록 함.
Local Conditioning
오디오 신호보다 해상도가 낮을 수 있는 두 번째 시계열 ${h_t}$를 사용하는 방법이다.
예를 들어 TTS에서는 언어학적 특징(텍스트 특징, 음운·강세 정보 등)이 해당한다. 이 시계열을 먼저 전치 합성곱(transposed convolution) 네트워크로 업샘플링하여 오디오 샘플과 동일한 해상도의 시계열 $\mathbf{y}=f(h)$을 얻는다. 그런 다음 Gated Activation Unit은
\[\mathbf{z} = \tanh\bigl(W_{f,k}\mathbf{x} + V_{f,k} * \mathbf{y}\bigr) \;\odot\; \sigma\bigl(W_{g,k}\mathbf{x} + V_{g,k} * \mathbf{y}\bigr),\]와 같이 동작한다. 여기서 $V_{\ast,k} * \mathbf{y}$는 $1\times1$ Convolution이다. 전치 합성곱 대신 ${V_{\ast,k}*h}$를 시간 축으로 반복(repeat)해 사용할 수도 있지만, 논문 실험에서는 전치 합성곱 방식을 썼을 때가 약간 더 우수했다고 말한다.
적용 예시 : 텍스트-투-스피치
언어학적 특징(phoneme, duration, stress 등)을 국부 조건화 입력으로 넣어, 지정된 문장을 자연스럽게 합성.
Context Stack
WaveNet의 receptive field를 확장하는 방법으로는 여러 방법이 있지만, 본 논문에서는 비교적 가벼운 context stack을 도입한다.
Context Stack은 긴 구간의 오디오 신호를 처리하여 얻은 추상 표현을, 수용 영역이 더 작은 주 WaveNet 모델이 처리하는 짧은 구간(끝부분을 잘라낸)에서 Local Conditioning 입력으로 사용하는 방식이다.
긴 구간”을 낮은 해상도로 요약(summary)해 주는 작은 네트워크라고 볼 수 있다. 이 요약을 Local Conditioning의 입력으로 제공하여 짧은 구간을 고해상도로 처리하면서도, 문맥 스택이 제공한 장기 정보를 함께 활용해 더 넓은 시간 범위를 모델링할 수 있다.
또한, pooling layer를 도입해 낮은 주파수(더 긴 시간 축 간격)로 신호를 처리하도록 할 수 있다.
이 구조는 전체 모델의 계산 비용을 크게 늘리지 않으면서, 다양한 시간 척도(time scale) 의 패턴을 효과적으로 포착할 수 있게 해 준다.
Expreiments
논문에서는 WaveNet의 성능을 평가하기 위해 세 가지 실험을 진행한다.
- 다중 화자 음성 생성 (Multi-Speaker Speech Generation) : 텍스트 조건 없이 무작위로 음성 신호 생성
- TTS (Text Condition)
- 음악 생성
이 중 (1)과 (2)가 음성 합성 품질 평가에 해당한다.
https://www.deepmind.com/blog/wavenet-generative-model-raw-audio/
위 링크로 접속하면 WaveNet이 생성한 Sample을 들어볼 수 있다.
1. Multi-Speaker Speech Generation
텍스트에 조건화되지 않은 자유형(free-form) 음성 생성을 평가한다.
CSTR voice cloning toolkit (Yamagishi, 2012)을 사용하였고, 화자 정보 조건화는 화자 ID를 원-핫(one-hot) 벡터 형태로 모델에 입력하는 방식으로 적용되었다.
텍스트 정보를 condition으로 주지 않았기 때문에, 실제로 존재하지 않는 단어들을 매끄럽게 생성하면서도 사람의 언어처럼 들리는 억양을 구현했다.
단일 WaveNet 모델은 화자별 one-hot 인코딩만으로 109명 모든 화자의 음성을 모델링할 수 있었다. 이는 단일 모델이 데이터셋 내 모든 화자의 특성을 포착할 만큼 충분히 강력함을 확인해 준다. 또한, 다수의 화자를 추가해 학습했을 때가 단일 화자만으로 학습했을 때보다 검증(validation) 성능이 더 좋게 나왔다. 이는 WaveNet이 내부 표현을 여러 화자에 걸쳐 공유함을 시사한다.
2. Text-to-Speech
TTS에서는 언어학적 특징에 local conditioning하여 학습했다.
추가로, 언어학적 특징뿐 아니라 로그 스케일 기본 주파수($\log F_0$) 값에 조건화한 WaveNet도 훈련하였다. 각 언어별로 언어학적 특징에서 log F0 값과 음소 지속시간(phone durations)을 예측하는 외부 모델도 별도로 학습했다.
baselines으로는
- 예시 기반(example-based) HMM 구동 단위 선택 합성(concatenative) 기법(Gonzalvo et al., 2016)
- 모델 기반(model-based) LSTM-RNN 통계적 파라메트릭(Statistical Parametric) 기법
을 사용하였으며, Metric은 주관적 비교 테스트와 MOS(mean opinion score)를 사용하였다.

위 그림은 주관적 비교 테스트 결과 중 일부를 보여준다.
영어와 중국어 모두에서 WaveNet이 통계적 파라메트릭 및 단위 결합 합성기들보다 우수한 성능을 보였다.
언어학적 특징만 조건화한 WaveNet은 음절 품질은 자연스러웠으나, 문장 단위 프로소디(prosody) 에서 잘못된 단어에 강조를 주는 등의 부자연스러운 경향이 있었다.
이는 WaveNet Receptive field(240 ms)가 $\log F_0$ 곡선의 장기 의존성(long-term dependency) 을 포착하기에 충분히 길지 않았기 때문이다.
반면, 언어학적 특징과 log F0 값을 모두 조건화한 WaveNet은 이 문제를 겪지 않았다. 이는 외부 F0 예측 모델이 낮은 빈도(200 Hz)로 동작해 F0 곡선의 장기 의존성을 학습할 수 있기 때문이다 .
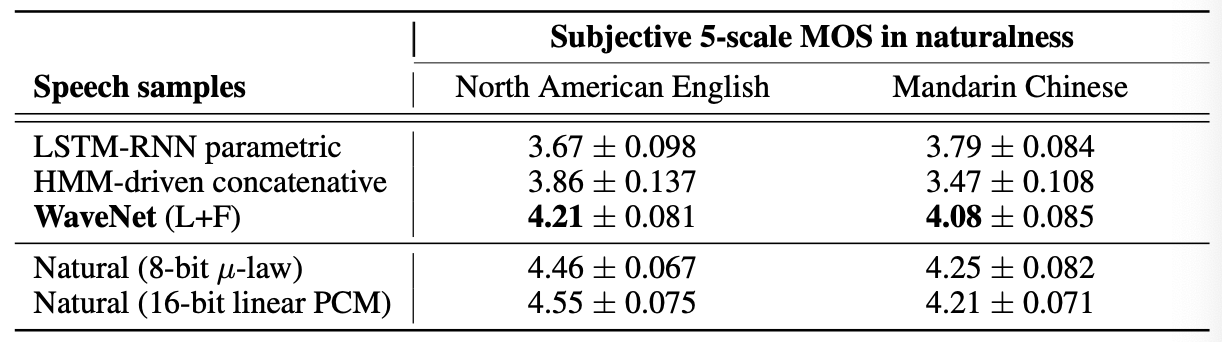
위 표는 MOS 테스트 결과를 보여준다. WaveNet은 자연스러움에 대해 5점 스케일에서 4.0 이상의 MOS를 기록했으며, 이는 비교 합성기들을 유의미하게 앞서는 수치였다. 이는 당시 해당 데이터셋과 테스트 문장에서 SOTA 수준에 해당하는 수치이다.
3. Music
2개의 음악 데이터셋을 모델링하도록 학습시킨다.
- MagnaTagATune 데이터셋(Law & Von Ahn, 2009): 약 200시간 분량의 음악 오디오로 구성되어 있다. 각 29초 클립에는 장르, 악기 구성, 템포, 볼륨, 분위기 등을 설명하는 188개 태그 집합 중 일부가 어노테이션되어 있다.
- YouTube 피아노 데이터셋: YouTube 영상에서 얻은 약 60시간 분량의 솔로 피아노 음악으로 구성되어 있다. 단일 악기에 한정되어 있어 모델링이 훨씬 수월하다.
생성된 샘플을 들어보는 주관적 평가가 가능하며, 정량적으로 평가하는 것은 어렵다.
저자들은 Receptive Field를 확장하는 것이 음악적으로 들리도록 생성하는 데 매우 중요하다는 것을 발견하였다고 한다.
몇 초 단위의 Receptive Field을 갖더라도, 모델은 장기적 일관성을 강제하지 못해 장르, 악기 구성, 볼륨 및 음질이 초단위로 급격히 변하는 현상을 보였다.
또한, 조건부 음악 모델로, 장르나 악기 등을 지정하는 태그 집합을 입력받아 원하는 성격의 음악을 생성할 수 있다.
각 학습 클립에 연관된 태그를 이진 벡터로 표현하여 그에 따라 bias 항을 삽입한다. 이를 통해 샘플링 시 원하는 특성을 입력함으로써 다양한 속성을 제어할 수 있다.
4. Speech Recognition
WaveNet은 생성 모델로 설계되었지만, 음성 인식과 같은 과제에도 간단히 적용할 수 있다.
순환 신경망(LSTM-RNN 등)은 장기 문맥을 모델링할 수 있어 이 분야의 핵심 요소였지만, WaveNet은 딜레이티드 합성곱만으로도 수용 영역(receptive field)을 훨씬 저렴하게 늘릴 수 있음을 보여 주었다.
마지막 실험으로, TIMIT 데이터셋(Garofolo et al., 1993)에서 WaveNet 기반 음성 인식을 시도했다.
- 평균 풀링(mean-pooling) 추가
- 딜레이티드 합성곱 블록 뒤에 10 ms 프레임(160배 다운샘플링) 단위로 활성화 출력을 요약하는 평균 풀링 층을 삽입했다.
- 비인과(non-causal) 합성곱
- 풀링 뒤에는 일반 합성곱 몇 겹을 더 쌓아 프레임 단위 특징을 정교하게 추출했다.
- 두 가지 손실함수 병합
- 다음 샘플 예측용 손실과, 프레임 단위 분류용 손실을 함께 최적화하도록 훈련했다.
- 이중 손실 설정이 단일 손실보다 일반화 성능을 높이는 것으로 나타났다.
이렇게 훈련한 모델은 TIMIT 테스트셋에서 18.8% 음소 오류율(PER) 을 기록했으며, 원시 오디오를 직접 사용한 모델 중에서는 최고 성능에 해당한다고 보고되었다.
Conclusion
WaveNet은 원시(raw) 오디오 파형을 직접 모델링하는 완전 확률적·오토리그레시브 생성 모델로,
- TTS 분야에서 기존 시스템을 뛰어넘는 주관적 자연도(MOS)를 달성했고,
- 다중 화자 음성 합성, 음악 생성, 음성 인식까지 한 가지 아키텍처로 처리할 수 있음을 보였다.
하지만 여전히
- 실시간 합성(real-time generation) 구현을 위해 생성 속도를 높이는 병렬화 기법이 필요하고,
- 장기 문맥(long-range dependencies) 포착을 위해 더 넓은 수용 영역(receptive field) 확보가 과제로 남아 있으며,
- 모델 경량화(model compression)를 통해 모바일·임베디드 환경에서도 동작하도록 최적화할 필요가 있다.
또한 WaveNet의 강력한 확장성은 비디오·텍스트 연계 멀티모달 생성 등 후속 연구가 활발히 이루어질 수 있는 토대를 마련했다.